






目录
前言
这是小编新开的一个栏目,为了记录自己在学习ProtoBuf的历程,也希望能帮助大家,本栏目主要以一个通信录小项目的形式来学习protobuf,本文主要浅浅认识一下protobuf是什么?以及我们如何使用protobuf,并没有进阶内容,只是作为一个新手初步了解protobuf的过程;
一、序列化与反序列化
在学习protobuf之前,大家都先得清楚一个概念,就是序列化与反序列化,这与我们接下来为什么学习protobuf有很大的关系;
序列化:把对象转换为字节序列的过程称为对象的序列化。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
应用场景:想必大家一定学习过网络编程吧?我们都知道,在进行网络传输过程中,我们一般不能传结构体,我们一般都传字符串等按字节为单位的数据,这是由于网络传输是跨主机的,不同主机可能出现不同的操作系统等不同标准,我们也听过一个概念就是大小端的概念,不同设备之间的标准也不同,若A主机按大端的方式将结构体传送给B主机,而B主机恰好为小端机器,那么这两者传输的数据就会出现异常,此时网络上就出现了网络字节序的概念,网络上的数据统一为大端,那么还有可能出现结构体对齐的问题,不同机器结构体对齐的标准也不同,因此就需要我们将数据进行序列化后再发送,接收端接收后,先进行反序列化得到结果;
二、protobuf是什么
我们直接看官网对其进行的解释,如下所示;protobuf官网链接

翻译:
Protocol Buffers是 Google 的⼀种语⾔⽆关、平台⽆关、可扩展的序列化结构数据的⽅法,它可⽤于(数据)通信协议、数据存储等。
Protocol Buffers 类⽐于 XML,是⼀种灵活,⾼效,⾃动化机制的结构数据序列化⽅法,但是⽐ XML 更⼩、更快、更为简单。你可以定义数据的结构,然后使⽤特殊⽣成的源代码轻松的在各种数据流中使⽤各种语⾔进⾏编写和读取结构数据。你甚⾄可以更新数据结构,⽽不破坏由旧数据结构编译的已部署程序。
简单来说,protobuf 就是一种让结构数据序列化的方法,关于翻译中的特点,我们在后面学习中慢慢体会;
三、protobuf的使用特点
我们使用proto文件定义结构对象(message)及属性,然后通过proto编译器编译后生成结构体对象对应的方法,如序列化与反序列化,其实生成的就是两个文件,一个头文件,一个源文件,这两个文件可以被我们主业务逻辑使用,就像我们平常引入头文件一样,如下图所示;

看完上面这个你可能还有点懵,不过没关系,下面我会进行使用演示,看完使用演示后,你会对上面这张图有更清晰的认识;
四、快速上手
在这里,我打算尝试演示一遍protobuf的使用,这里我打算做一个通讯录1.0版本,我将会实现如下;
- 对⼀个联系⼈的信息使⽤ PB(protobuf) 进⾏序列化,并将结果打印出来。
- 对序列化后的内容使⽤ PB(protobuf) 进⾏反序列,解析出联系⼈信息并打印出来。
- 联系⼈包含以下信息: 姓名、年龄。
1、proto文件编写
下面为我们所接触第一个段protobuf代码,我会对代码进行一一解释,具体如下所示;
// 注释
/* 注释 */
syntax = "proto3"; // 这是指定我们使用proto版本
package contacts; // 指定一个命名空间
// 定义一个 message 结构
message PeopleInfo
{
// 定义字段
string name = 1;
int32 age = 2;
}(1)我们创建一个proto文件时,通常建议采用小写字母命名,且小写字母之间可以采用下划线分隔开来;如下所示
create_file
open_file
下图是我们这段代码的文件名

(2)注释有两种方法,如上述代码一二行,此注释方法与C语言、C++相同;
(3)我们使用关键字syntax来指定protobuf版本,这里一般指定proto3,若不写默认指定proto2;
(4)我们使用关键字package来指定一个命名空间,类似C++中的namespace,该命名空间作用于我们后续使用proto编译器编译该文件生成的文件代码作用域;
(5)我们使用关键字message来定义一个结构,其中结构中的字段用花括号括起来;
(6)我们定义的字段有不同的类型,上面分别为string类型与int32类型;每个字段都有一个字段编号,这个字段编号在该message中生效且唯一;(关于具体类型这里不做详细介绍,后面专门介绍)
(7)字段唯一编号我们推荐使用 1~ 5 3687 0911(2^29-1);其中范围1~15的字段我们进行编码需要一个字节,16~2047需要两个字节;这里的编码可理解成序列化;
2、编译proto文件
我们通常使用如下命令进行编译proto文件;
protoc -I 要编译的proto文件所在目录 --cpp_out=生成文件所在目录 要编译的proto文件

如上图我们编译完proto文件后,我指定的是当前目录,所以当前目录生成如下文件;
没错,这些文件就是刚刚我们那个message结构对应的一些序列化、反序列化的方法;
3、序列化与反序列化的使用
我们在上述目录下创建一个 mian.cc 的文件,保存我们接下来所编写主程序上的代码,如下所示,其中每一行都有注释;
// main.cc文件
#include <iostream>
#include <string>
#include "contacts.pb.h"
int main()
{
// 1、对⼀个联系⼈的信息使⽤PB进⾏序列化,并将结果打印出来。
// 定义PeopleInfor结构体(PB根据我们的proto文件帮我们生成的)
contacts::PeopleInfo people;
people.set_name("张三");
people.set_age(19);
// 定义接收序列化后字符串的缓冲区
std::string people_str;
// 序列化
bool ret = people.SerializeToString(&people_str);
if(ret == false)
{
std::cout << "序列化失败" << std::endl;
exit(1);
}
printf("序列化成功,序列化后的结果为:\n%s", people_str.c_str());
std::cout << "\n--------------------------- 分割线 ---------------------------\n";
// 2、对序列化后的内容使⽤PB进⾏反序列,解析出联系⼈信息并打印出来。
contacts::PeopleInfo destPeople;
ret = destPeople.ParseFromString(people_str);
if(ret == false)
{
std::cout << "反序列化失败" << std::endl;
exit(2);
}
std::cout << "反序列化成功,结果为: " << std::endl
<< "name: " << destPeople.name() << std::endl
<< "age: " << destPeople.age() << std::endl;
return 0;
}上述中我们使用序列化,反序列化的接口都来自于我们编译proto文件后自动帮我们生成的代码;一般来说,我们获取一个类字段的值用我们一开始在proto文件中message中给字段取得名字来获取字段的值,如上述中的name和age,设置字段的值一种加一个set,对于序列化一般以Serialize为开头,反序列化一般以Parse为开头,这里我们作为初体验仅仅记住上述所陈述即可;
对于上述代码,我们必须使用g++进行编译时,必须加上如下特定选项;
-std=c++11 // 这是因为我们的protobuf帮我们生成的代码中使用c++11
-lprotobuf // 因为protobuf为第三方库,我们必须指定库名

我们直接运行,如下所示;
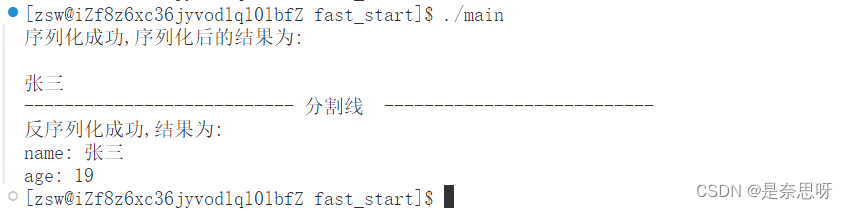
这时,我们会发现我们序列化后的结果是一行空行加一个张三,这是因为我们序列化后的结果为一串二进制序列,这里用string进行接收,所以打印时会出现乱码;















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









