欢迎光临我的博客:[https://gaussic.github.io/2017/03/03/imdb-sentiment-classification/](https://gaussic.github.io/2017/03/03/imdb-sentiment-classification/) (转载请注明出处:[https://gaussic.github.io](https://gaussic.github.io)) Keras的官方Examples里面展示了四种训练IMDB文本情感分类的方法,借助这4个Python程序,可以对Keras的使用做一定的了解。以下是对各个样例的解析。 ## IMDB 数据集 IMDB情感分类数据集是Stanford整理的一套IMDB影评的情感数据,它含有25000个训练样本,25000个测试样本。以下是其中的一个正样本: > Bromwell High is a cartoon comedy. It ran at the same time as some other programs about school life, such as "Teachers". My 35 years in the teaching profession lead me to believe that Bromwell High's satire is much closer to reality than is "Teachers". The scramble to survive financially, the insightful students who can see right through their pathetic teachers' pomp, the pettiness of the whole situation, all remind me of the schools I knew and their students. When I saw the episode in which a student repeatedly tried to burn down the school, I immediately recalled ......... at .......... High. A classic line: INSPECTOR: I'm here to sack one of your teachers. STUDENT: Welcome to Bromwell High. I expect that many adults of my age think that Bromwell High is far fetched. What a pity that it isn't! 本文中的Keras样例使用的是整理好已经符号化的pkl文件,其数据格式大致如下: ``` from six.moves import cPickle (x_train, labels_train), (x_test, labels_test) = cPickle.load(open('imdb_full.pkl', 'rb')) print(x_train[0]) >>> [23022, 309, 6, 3, 1069, 209, 9, 2175, 30, 1, 169, 55, 14, 46, 82, 5869, 41, 393, 110, 138, 14, 5359, 58, 4477, 150, 8, 1, 5032, 5948, 482, 69, 5, 261, 12, 23022, 73935, 2003, 6, 73, 2436, 5, 632, 71, 6, 5359, 1, 25279, 5, 2004, 10471, 1, 5941, 1534, 34, 67, 64, 205, 140, 65, 1232, 63526, 21145, 1, 49265, 4, 1, 223, 901, 29, 3024, 69, 4, 1, 5863, 10, 694, 2, 65, 1534, 51, 10, 216, 1, 387, 8, 60, 3, 1472, 3724, 802, 5,3521, 177, 1, 393, 10, 1238, 14030, 30, 309, 3, 353, 344, 2989, 143, 130, 5, 7804, 28, 4, 126, 5359, 1472, 2375, 5, 23022, 309, 10, 532, 12, 108, 1470, 4, 58, 556, 101, 12, 23022, 309, 6, 227, 4187, 48, 3, 2237, 12, 9, 215] print(labels_train[0]) >>> 1 ``` > 更详细的预处理过程请看 [keras/dataset/imdb.py](https://github.com/fchollet/keras/blob/master/keras/datasets/imdb.py) ## FastText FastText是Joulin等人在[Bags of Tricks for Efficient Text Classification](https://arxiv.org/abs/1607.01759)一文中提到的快速文本分类的方法,论文作者说这个方法可以作为很多文本分类任务的baseline。整个模型的结构如下图所示: 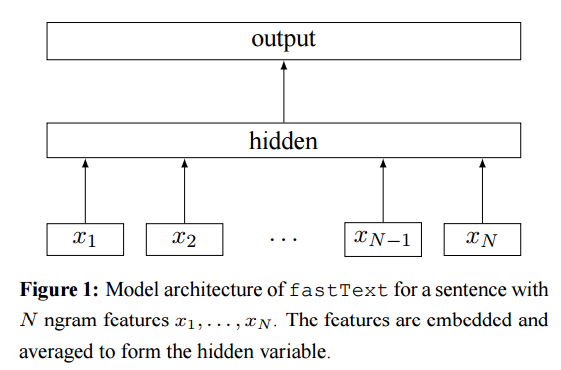 给定一个输入序列,首先提取N gram特征得到N gram特征序列,然后对每个特征做词嵌入操作,再把该序列的所有特征词向量相加做平均,作为模型的隐藏层,最后在输出层接任何的分类器(常用的softmax)就可以进行分类了。 这个思路类似于平均化的Sentence Embedding,将句子中的所有词向量相加求平均,得到句子的向量表示。











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 2216
2216





