






在https://blog.csdn.net/allenlu2008/article/details/103884170 中,虾神介绍了自然断点法在python中的实现方法,而我看到评论区有人提出了这样的问题:

其实我也遇到了这个问题。在思考了ArcGIS的jenkspy分类流程后,找到了解决方法。
先来看看ArcGIS中是如何做jenkspy分类的:
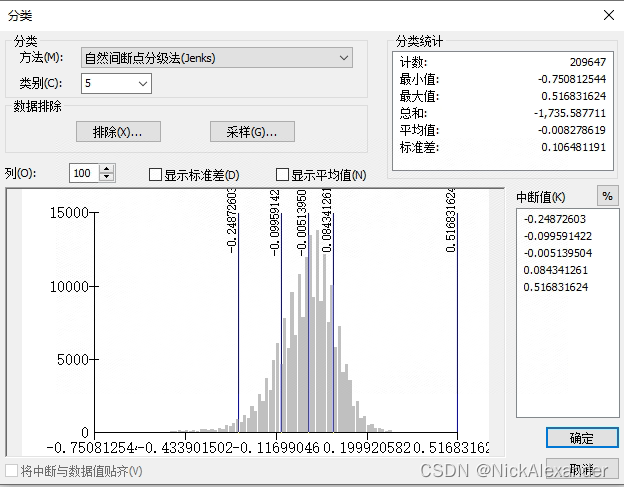
ArcGIS中,先统计直方图,再根据直方图横坐标来进行jenkspy分类。
问题来了:为啥要统计直方图呢?
其实是否统计直方图根本不重要,重要的是知道横坐标的分布,也就是知道数组中不重复的数字有哪些!
那么解决的办法也就很简单了:无论数据量有多大,只需要找到所有不重复的数字就好!
Numpy中的unique()和Python自带的set()都能做到~
numpy.unique()
set()下面我用unique()做一个例子实验一下:
1、数据不作处理,直接jenkspy分类
import jenkspy
import time
time_start = time.time() # 记录开始时间
# 假设一张500*500的栅格影像,栅格的值在0~20
a = np.random.randint(0, 20, size=(500, 500))
b = a.flatten() # jenkspy必须使用一维数组
# 不做处理,直接把全部数据用作计算
breaks = jenkspy.jenks_breaks(b, 4)
print(f"breaks: {breaks}")
time_end = time.time() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print(time_sum)2、找到不重复的值,将其作为jenkspy分类的数组
import jenkspy
import time
time_start = time.time() # 记录开始时间
# 假设一张500*500的栅格影像,栅格的值在0~20
a = np.random.randint(0, 20, size=(500, 500))
# 用unique()取唯一值
b = np.unique(a.flatten()) # jenkspy必须使用一维数组
breaks = jenkspy.jenks_breaks(b, 4)
print(f"breaks: {breaks}")
time_end = time.time() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print(time_sum)结果如下:
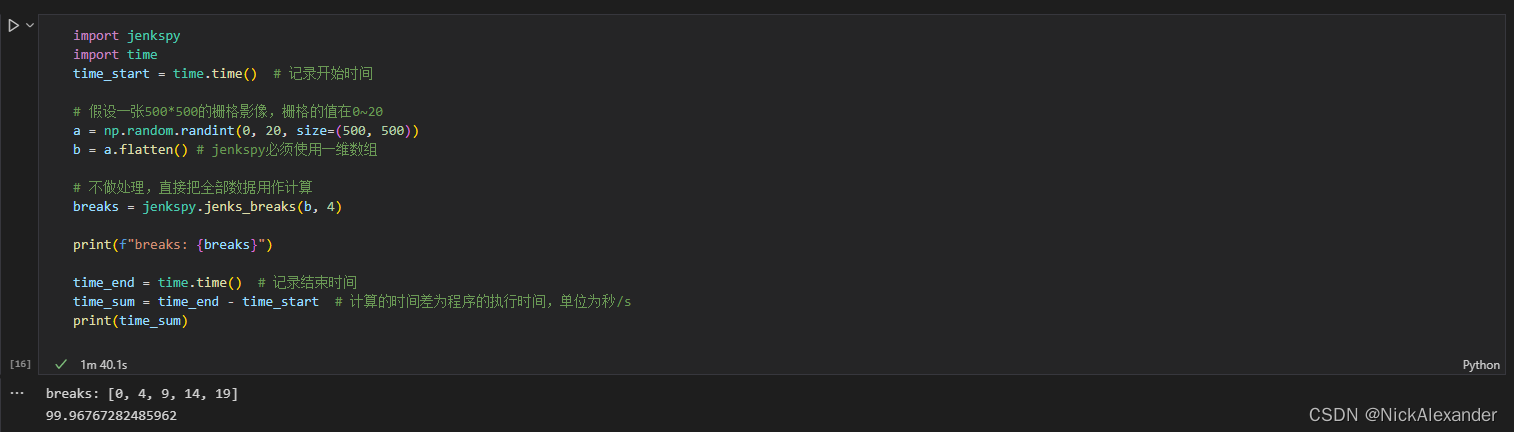
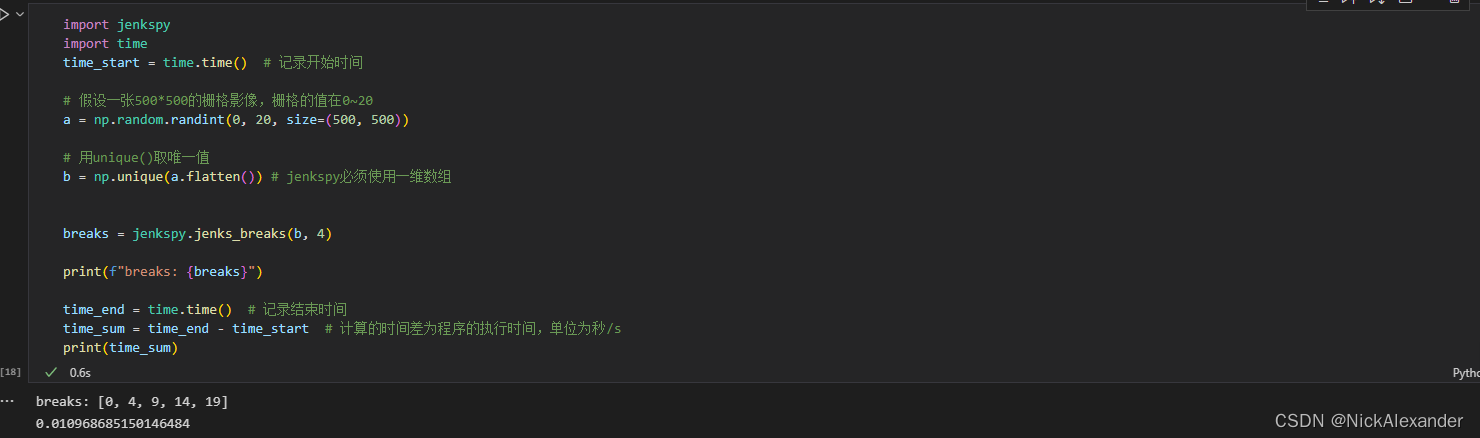
只能说,一个小小的取唯一值,结果却天差地别。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









