







二叉树非递归中序遍历
template<class ElemType>
const BinTreeNode<ElemType>*GoFarLeft(const BinTreeNode<ElemType>*r,LinkStack<const BinTreeNode<Elem>*>&s)
//操作结果:返回以r为根的二叉树的最左侧的节点,并将搜索过程中的节点加入到栈s中
{
if(r==null)
{
//空二叉树
return null;
}
else
{
//非空二叉树
const BinTreeNode<ElemType>*cur=r;
while(cur->leftChild!=null)
{
//cur存在左孩子,则cur移向左孩子
s.Push(cur);//cur入栈
cur=cur->leftChild;//cur移向左孩子
}
return cur;//cur为最左侧的节点
}
}
二叉树层次遍历
template<class ElemType>
void BinTreeNode<ElemType>::LevelOrder(void(*visit)(const ElemType &))const
//操作结果:层次遍历二叉树
{
LinkQueue<const BinTreeNode<ElemType>*>q;//队列
const BinTreeNode<ElemType>*cur;//当前节点
if(root!=null)
q.InQueue(root);//如果根非空,则入队,以便从根节点开始进行层次遍历
while(!q.Empty())
{
//q非空,说明还有节点未访问
q.OutQueue(cur);//出队元素为当前访问的节点
(*visit)(cur->data);//访问cur->data
if(cur->leftChild!=null)
q.InQueue(cur->leftChild);//左孩子非空,左孩子入队
if(cur->rightChild!=null)
q.InQueue(cur->rightChild);//右孩子非空,右孩子入队
}
}
删除单链表第一个位置元素
Node* Dele(Node* head)
{
if(NULL == head)
return head;
Node* p = head;
Node* q = p->next;
if(NULL == q)
return head;
p->next = q->next;
free(q);
return head;
}
线性表的特点
线性表是由类型相同的数据元素组成的有限序列。
1、存在唯一的一个被称作“第一个”的数据元素;
2、存在唯一的一个被称作“最后一个”的数据元素;
3、除第一个以外,结构中的每个数据元素均只有一个前驱;
4、除最后一个以,外结构中每个数据元素只有一个后继。
线性表的实现方法
1、顺序表
2、链表
栈
栈是限定只在表头进行出入(入栈)与删除(出栈)操作的线性表,表头端称为栈顶,表位端称为栈底。
1.在栈中,栈的修改按照 先进后出 的原则进行。
2.栈底指针始终指向栈底,栈顶指针始终指向最上面的那个元素。
队列
队列是一种 先进先出 的线性表。它值允许在表的一端进行插入,而在另一端进行删除元素。
队首元素始终指向最前面的元素,队尾元素始终指向最后到来的元素。
线性表时间的复杂度
对于一个长度为n的顺序存储的线性表,在表头插入元素的时间复杂度为O(n),在表尾插入元素的时间复杂度为O(1)
线性表插入需要移动元素的个数
添加到第1个,移动N个元素;
添加到第2个,移动(N-1)个元素;
……
添加到第N个,移动1个元素;
添加到第(N+1)个,移动0个元素
平均:(0+1+2+……+N)/(N+1)=N/2
线性表删除需要移动元素的个数
删除第1个,移动(N-1)个;
删除第2个,移动(N-2)个;
…
删除第N个,移动0个
平均:[0+1+……+(N-1)]/N=(N-1)/2
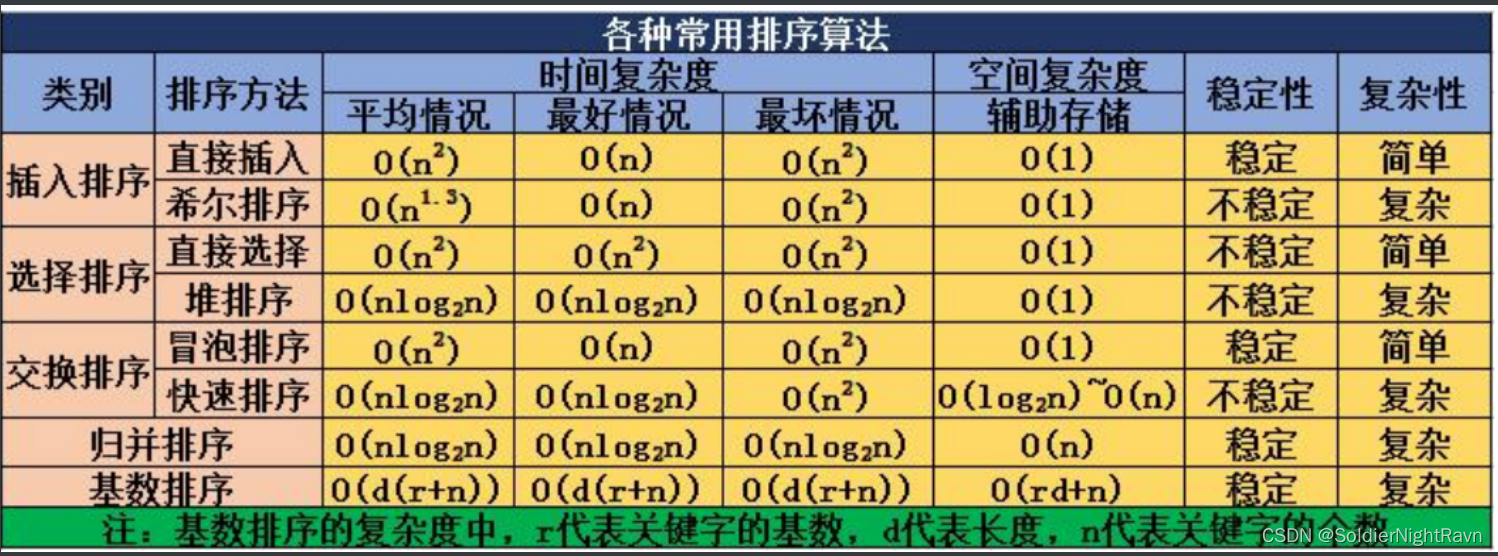
不同排序算法的内存需求、时间复杂度
二分查找的比较次数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WmEeIJzv-1657523890542)(https://bkimg.cdn.bcebos.com/formula/2407731a0ccaa91127f948304d88ec58.svg)]](https://img-blog.csdnimg.cn/f5b9abc0f98d4c19a529c1bc348f95b7.png)
不同数据结构的特点
1)数组
【1】会在内存中开辟一个连续的内存空间
【2】随机访问的效率比链表高。数组只要给定下标,则可以直接定位到该下标所对应的元素,而链表每次都是从头节点开始遍历。
【3】对元素的增删操作的效率比链表低。
2)链表
【1】通过一个个指针将节点串起来
【2】对于元素的随机访问,需要使用计数器来访问指定的元素,并且只能从头节点开始访问,每访问一个节点,计数器加1,直到给定的“下标”,此操作很耗时,时间复杂度为O(N)
【3】增加元素和删除元素的效率很高
3)队列
【1】不支持随机访问
【2】先进先出
【3】线程池中的线程就是从任务队列中取出任务
4)栈
【1】不支持随机访问
【2】后进先出
5)二叉树
【1】每个节点最多只有两个子节点
6)搜索树
【1】二分查找,数组对半分的路径就是一个搜索树
【2】不一定是二叉树
7)堆/优先队列
【1】按照顺序pop出元素
【2】优先队列中,以最小堆为例,树或子树根结点都是所在树或子树中最小的元素
8)无向图
【1】每个节点都没有方向,边上可能有权重
9)有向图
【1】每个节点是有方向的的
10)有向无环图
【1】可以描述任务之间的关系
二叉树特点:
1.每个节点最多有两个子树,所以二叉树不存在度大于2的节点(结点的度:结点拥有的子树的数目。),可以没有子树或者一个子树。
2.左子树和右子树有顺序,次序不能任意颠倒。
3.即使树种某节点只有一颗子树,也要区分是左子树还是右子树。
堆的特点
1、是完全二叉树;
2、用数组实现:将二叉树的结点按层级顺序放入数组,根节点在位置1,它的子节点在位置2和3,子节点的子节点在4、5、6、7,以此类推;
3、如果一个结点位置为k,则其父节点位置为k/2,其两个子节点的位置分别为2k和2k+1。因此,从a[k]向上一层,令k=k/2,向下一层令k=2k或2k+1;
每个结点大于等于它的两个子结点。
邻接矩阵的特点
1),无向图的邻接矩阵一定是对称的,对于有n个顶点的无向图则只存上(下)三角阵中剔除了左上右下对角线上的0元素后剩余的元素,故只需1+2+…+(n-1)=n*(n-1)/2个单元。
2),有向图的邻接矩阵不一定对称,表示图共需n^2个空间。
算法的基本语句
它包括五种最基本的算法语句。即输入语句,输出语句,赋值语句,条件语句,循环语句。
算法复杂度
算法复杂度分为时间复杂度和空间复杂度。其作用: 时间复杂度是指执行算法所需要的计算工作量;而空间复杂度是指执行这个算法所需要的内存空间。(算法的复杂性体运行该算法时的计算机所需资源的多少上,计算机资源最重要的是时间和空间(即寄存器)资源,因此复杂度分为时间和空间复杂度。)
先序遍历
DLR(中左右)
1、访问根节点
2、先序遍历左子树
3、先序遍历右子树
中序遍历
LDR(左中右)
1、中序遍历左子树
2、访问根节点
3、中序遍历右子树
后序遍历
LRD(左右中)
1、后序遍历左子树
2、后序遍历右子树
3、访问根节点
层次遍历
按照层数从左至右一次遍历
哈夫曼树的构建
哈夫曼树并不唯一,但带权路径长度一定是相同的。
举例说明:
1)8个结点的权值大小如下:

2)从19,21,2,3,6,7,10,32中选择两个权小结点。选中2,3。同时算出这两个结点的和5。
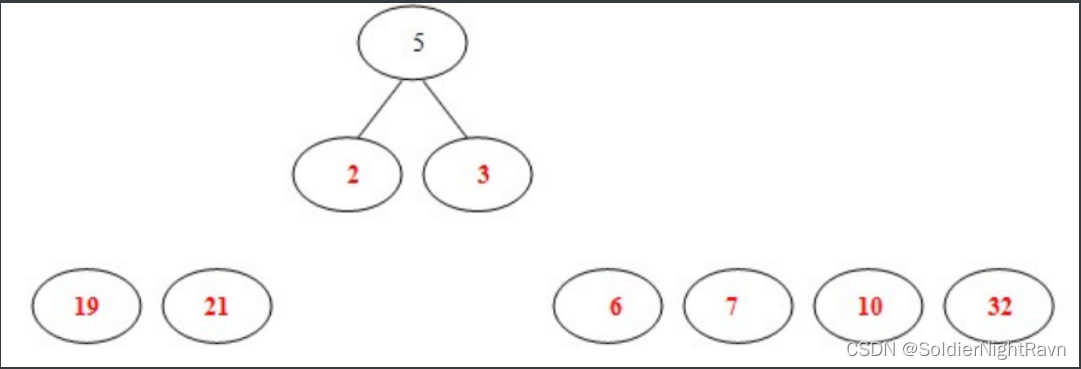
3)从19,21,6,7,10,32,5中选出两个权小结点。选中5,6。同时计算出它们的和11。
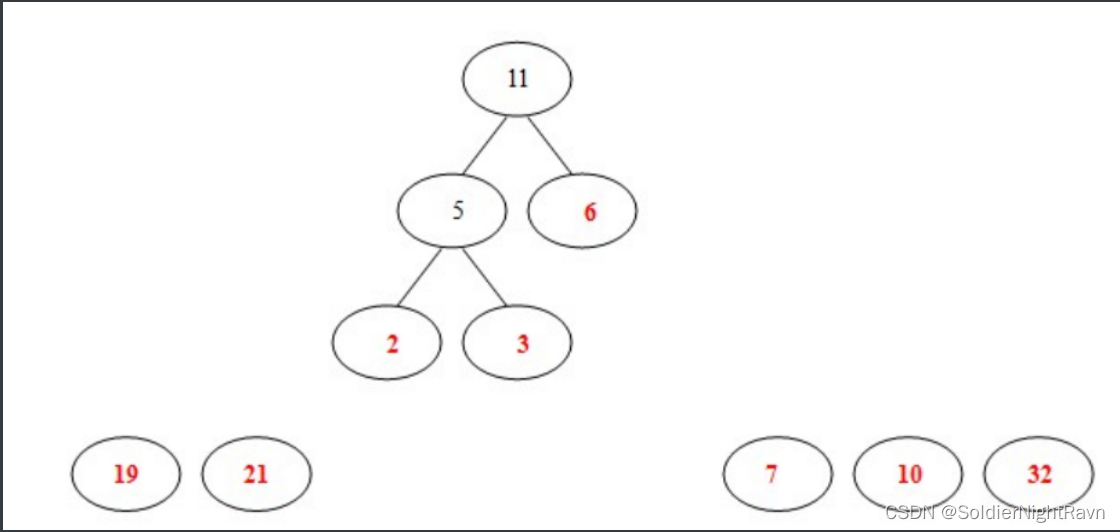
4)从19,21,7,10,32,11中选出两个权小结点。选中7,10。同时计算出它们的和17。
(这时选出的两个数字都不是已经构造好的二叉树里面的结点,所以要另外开一棵二叉树;或者说,如果两个数的和正好是下一步的两个最小数的其中的一个,那么这个树直接往上生长就可以了,如果这两个数的和比较大,不是下一步的两个最小数的其中一个,那么就并列生长。)
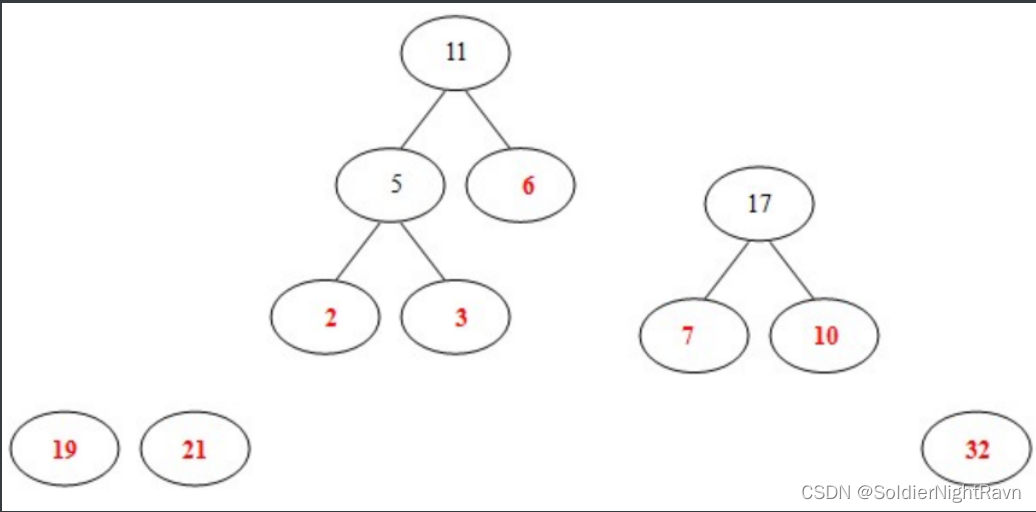
5)从19,21,32,11,17中选出两个权小结点。选中11,17。同时计算出它们的和28。

6)从19,21,32,28中选出两个权小结点。选中19,21。同时计算出它们的和40。另起一颗二叉树。
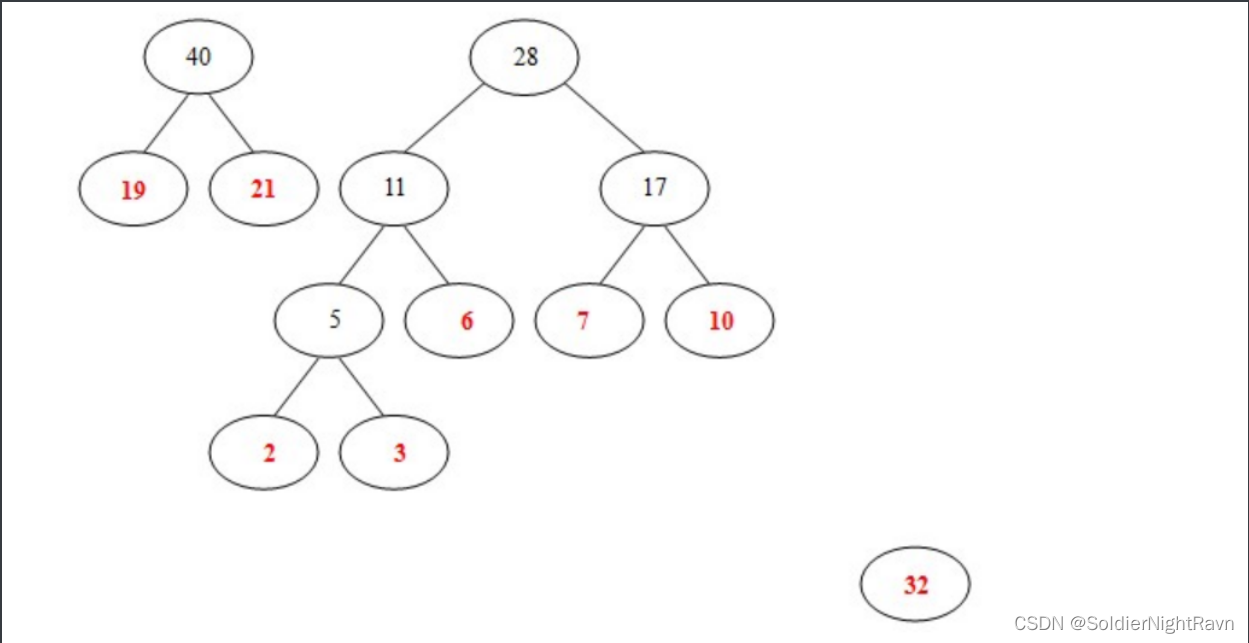
7)从32,28, 40中选出两个权小结点。选中28,32。同时计算出它们的和60。
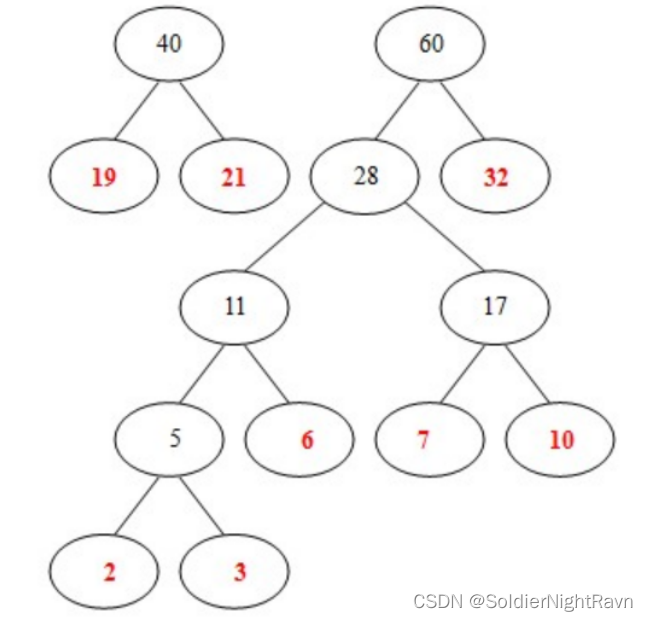
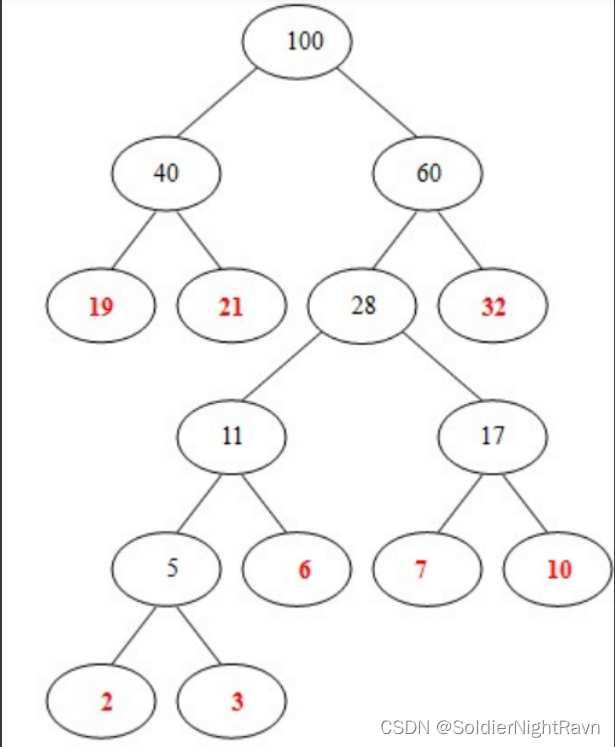
8)从 40, 60中选出两个权小结点。选中40,60。同时计算出它们的和100。 好了,此时哈夫曼树已经构建好了。
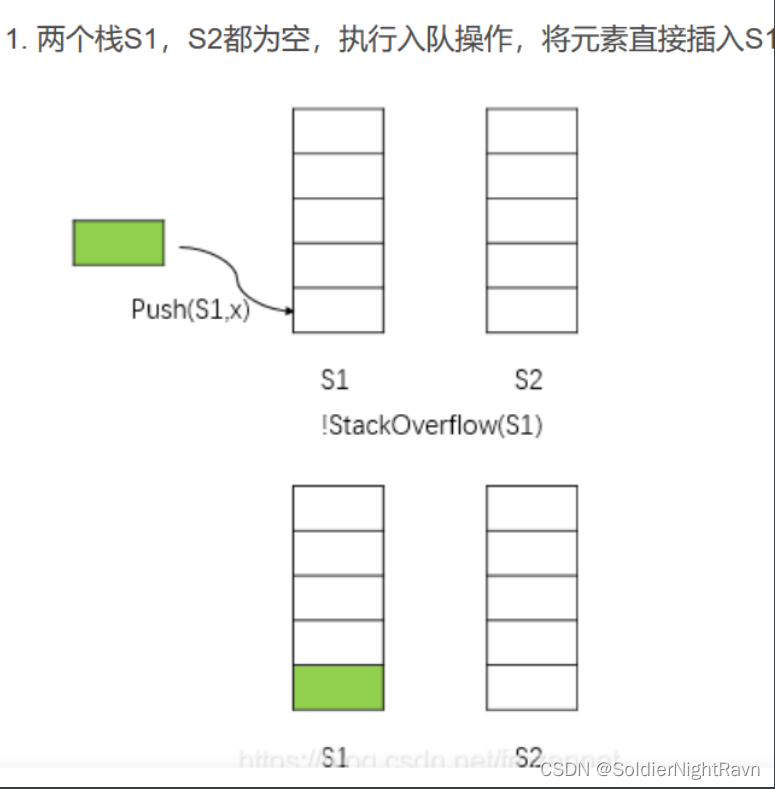
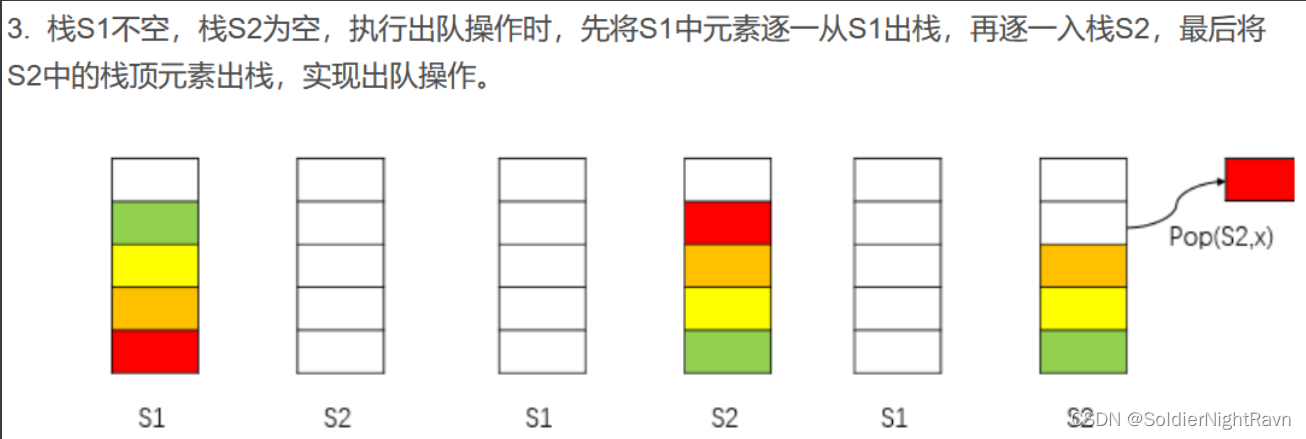
两个栈模拟一个队列进行插入和删除的过程
1、插入

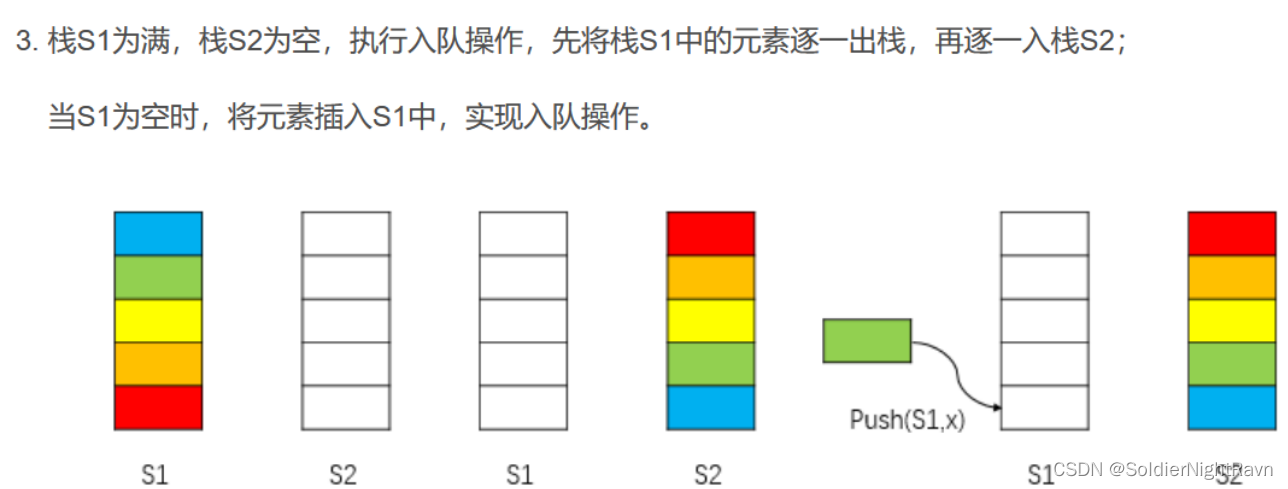
2、删除


深度优先搜索遍历
图的深度优先搜索遍历(DFS)类似于二叉树的先序遍历。
广度优先搜索遍历
图的广度优先搜索遍历(BFS)类似于树的层次遍历。
树转二叉树和中序线索二叉树
树转二叉树
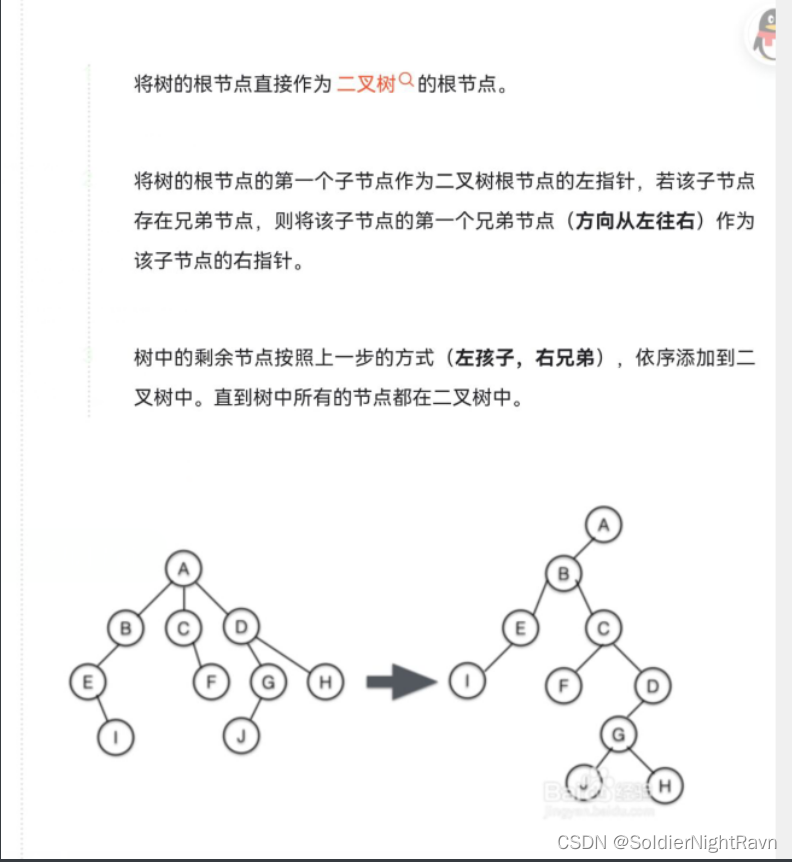















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









