







目录
概述
聚合函数(Aggregate Function)顾名思义,就是将一组数据进行统一计算,常常用于分析型数据库中,当然在应用中是非常重要不可或缺的函数计算方式。比如我们常见的COUNT/AVG/SUM/MIN/MAX等等。本文主要讲述数据库常用的实现方式。
Stream Aggregate算法
一、原理和伪代码描述
<1> 原理
Stream Aggregate的计算需要保证输入数据按照Group-By列有序。在计算过程中,每当读到一个新的 Group 的值或所有数据输入完成时,便对前一个 Group 的聚合最终结果进行计算。
Stream Aggregate的输入数据需要保证同一个Group的数据连续输入,所以Stream Aggregate处理完一个Group的数据后可以立刻向上返回结果,不用像Hash Aggregate一样需要处理完所有数据后才能正确的对外返回结果。
<2> 伪代码描述
Stream Group算法依赖于到达的数据并且这些数据按组按列进行排序。后续伪代码如下:
clear the current aggregate resultsclear the current group by columnsfor each input rowbeginif the input row does not match the current group by columnsbeginoutput the aggregate resultsclear the current aggregate resultsset the current group by columns to the input rowendupdate the aggregate results with the input rowend
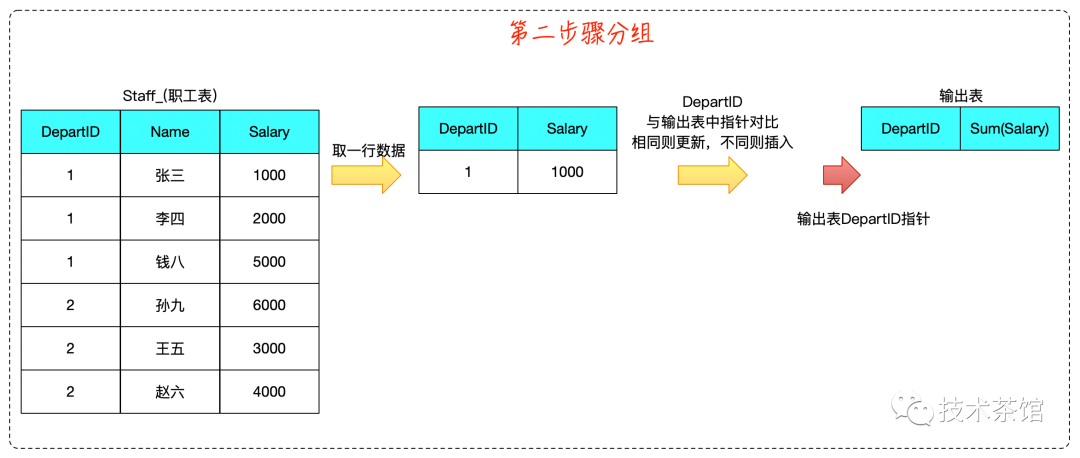
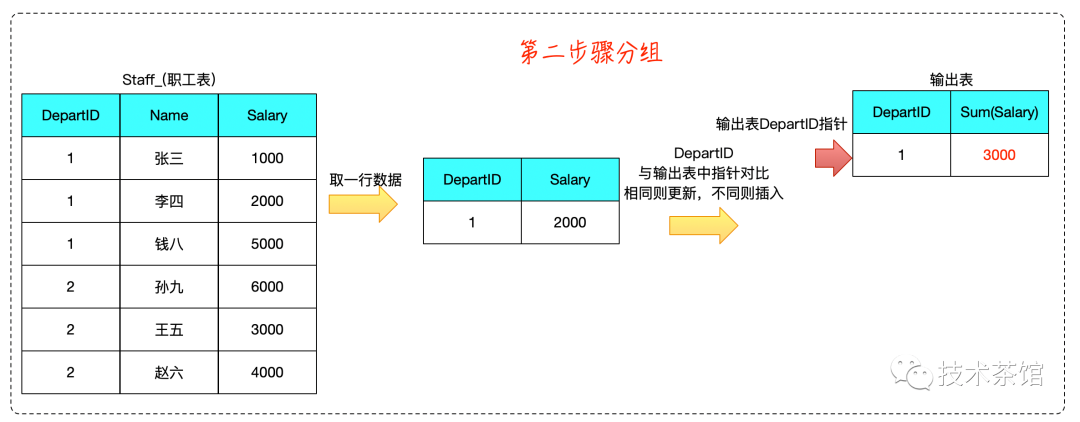
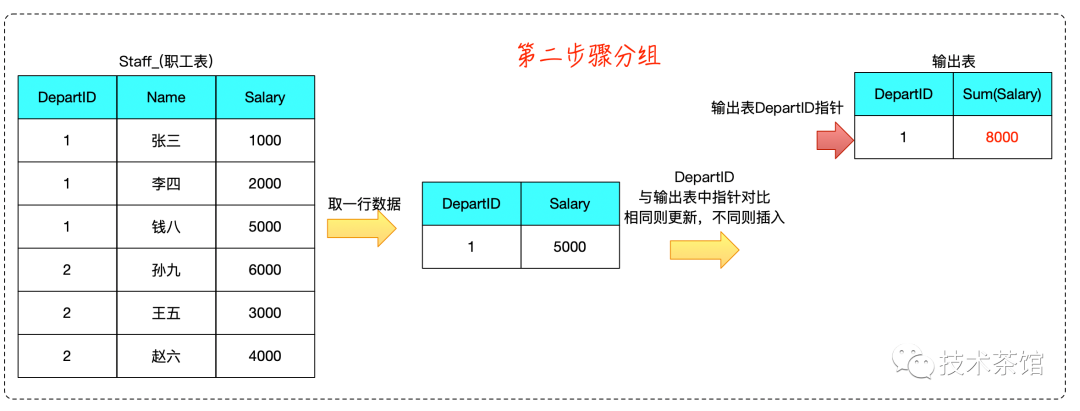
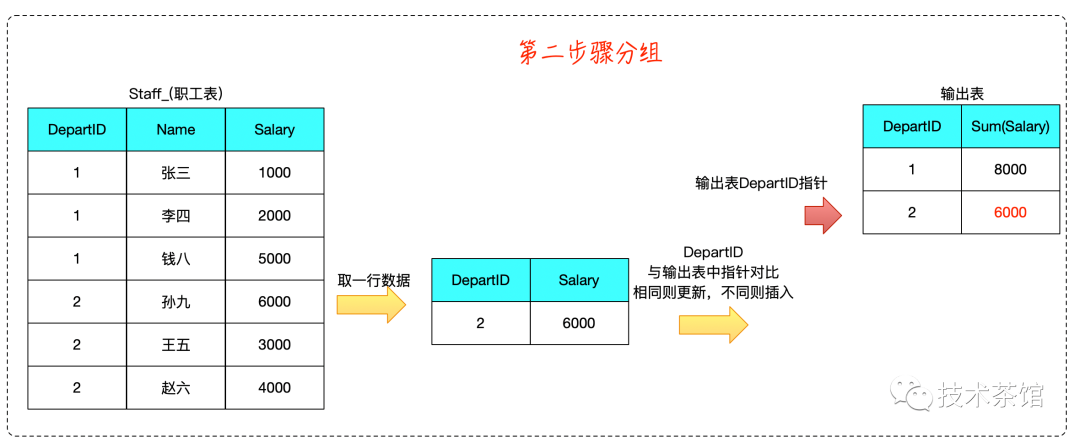
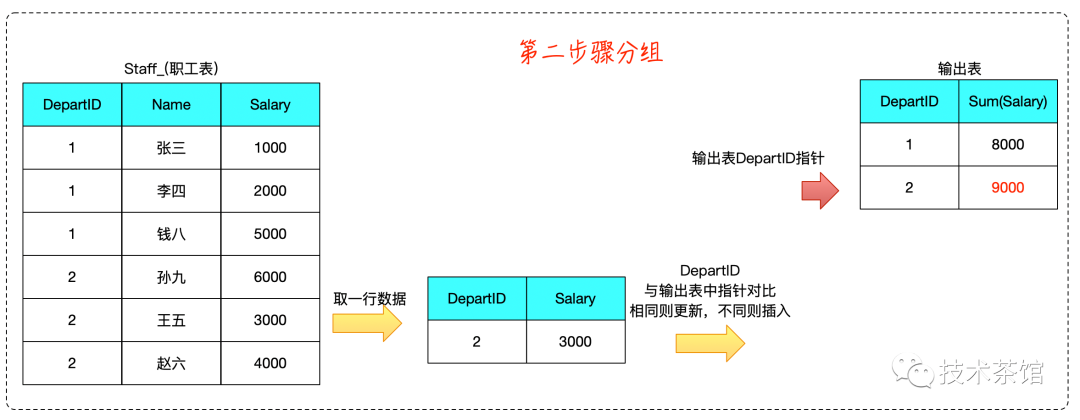
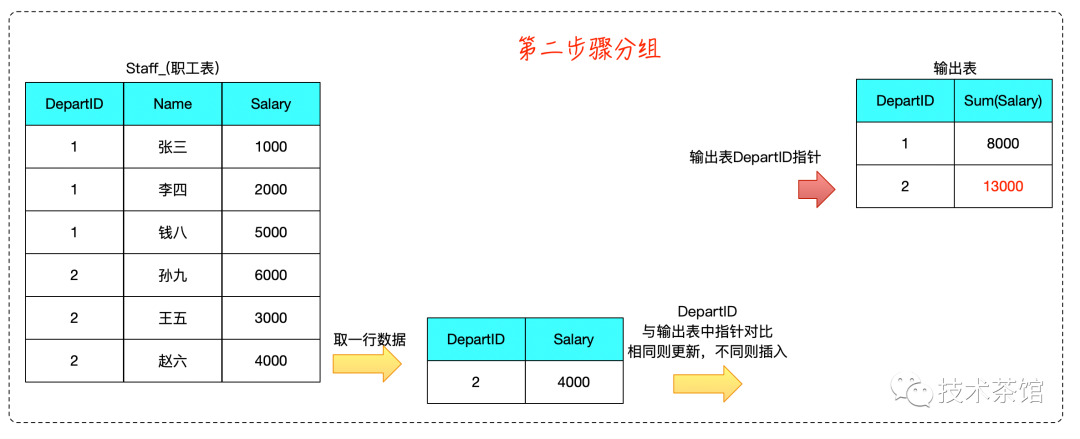
二、案例
测试SQL如下所示
SELECTdepartId,Sum( Salary )FROMstaff_GROUP BYdepartId
算法推演如下:

Hash Aggregate算法
一、原理和伪代码描述
<1> 原理
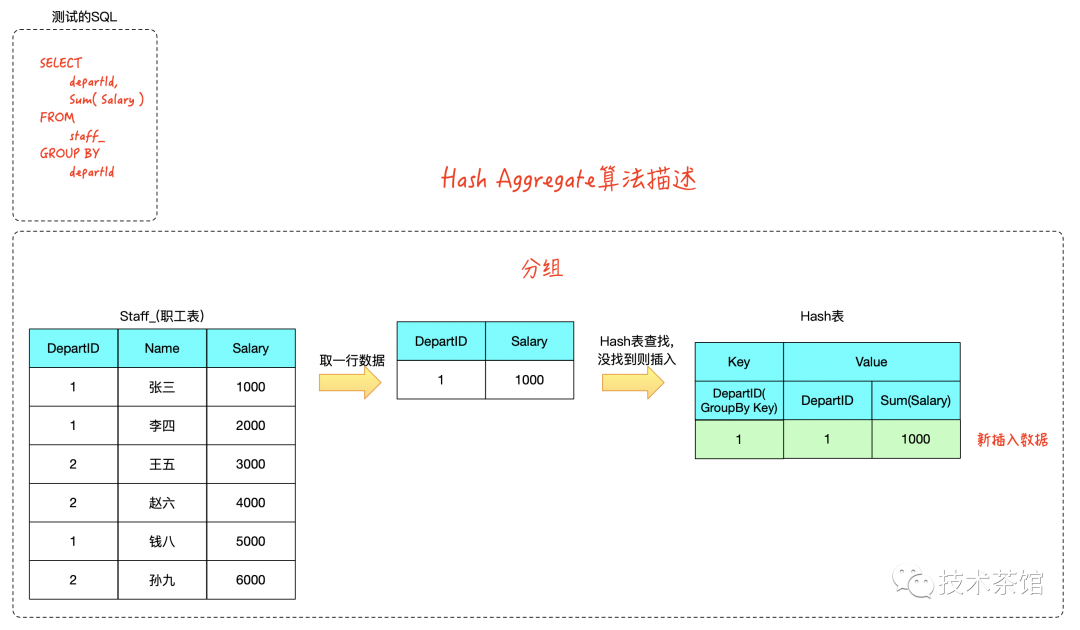
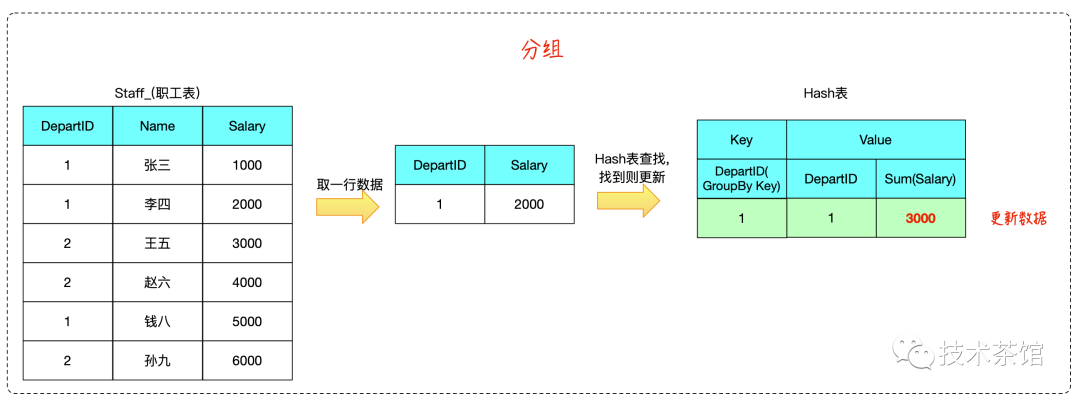
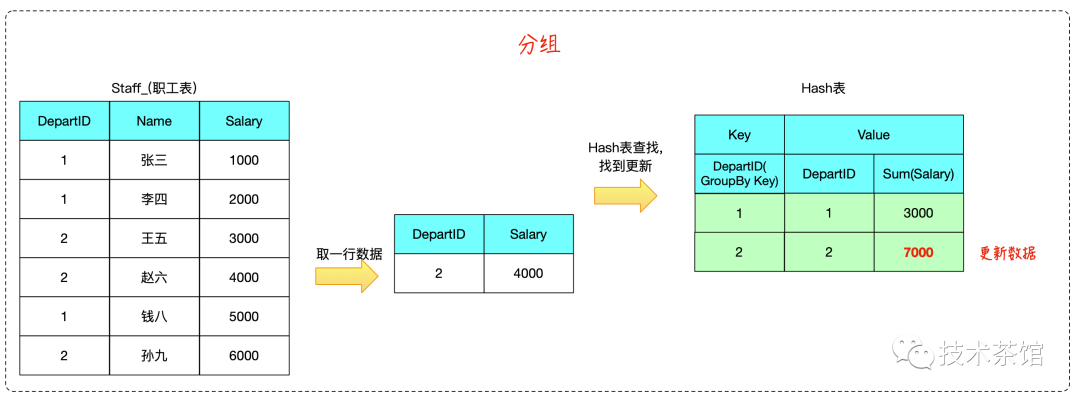
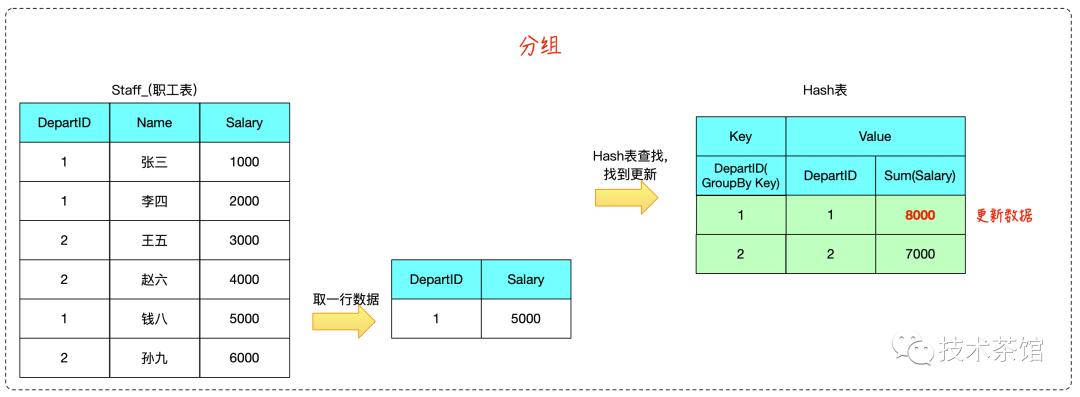
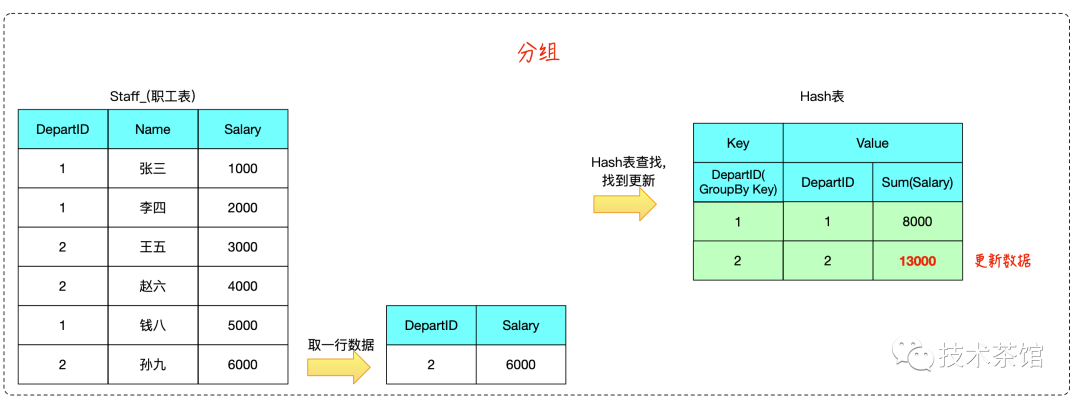
在 Hash Aggregate 的计算过程中,我们需要维护一个Hash表,Hash表的键为聚合计算的 Group-By 列,值为SQL的输出数据。
计算过程中,只需要根据每行输入数据计算出键,在 Hash 表中找到对应值进行更新即可。
<2> 伪代码描述
begincalculate hash value on group by column(s)check for a matching row in the hash tableif we do not find a matchinsert a new row into the hash tableelseupdate the matching row with the input rowendoutput all rows in the hash table
二、案例
测试SQL如下所示
SELECTdepartId,Sum( Salary )FROMstaff_GROUP BYdepartId
算法推演如下:

聚合函数的计算模式
由于分布式计算的需要,对于聚合函数的计算阶段进行划分,相应定义了两种计算模式:CompleteMode,FinalMode,PartialMode。不同的计算模式下,所处理的输入值和输出值会有所差异,如下表所示:
| 计算模式 | 输入值 | 输出值 |
| CompleteMode | 原始数据 | 最终结果 |
| FinalMode | 中间结果 | 最终结果 |
| PartialMode | 原始数据 | 中间结果 |
我们还以之前的的SQL案例来说明下面的两种计算模型。
上文SQL如下所示:
SELECTdepartId,Sum( Salary )FROMstaff_GROUP BYdepartId
CompleteMode模式计算模型
这个模型聚合函数的整个计算过程只有一个阶段,如图所示:
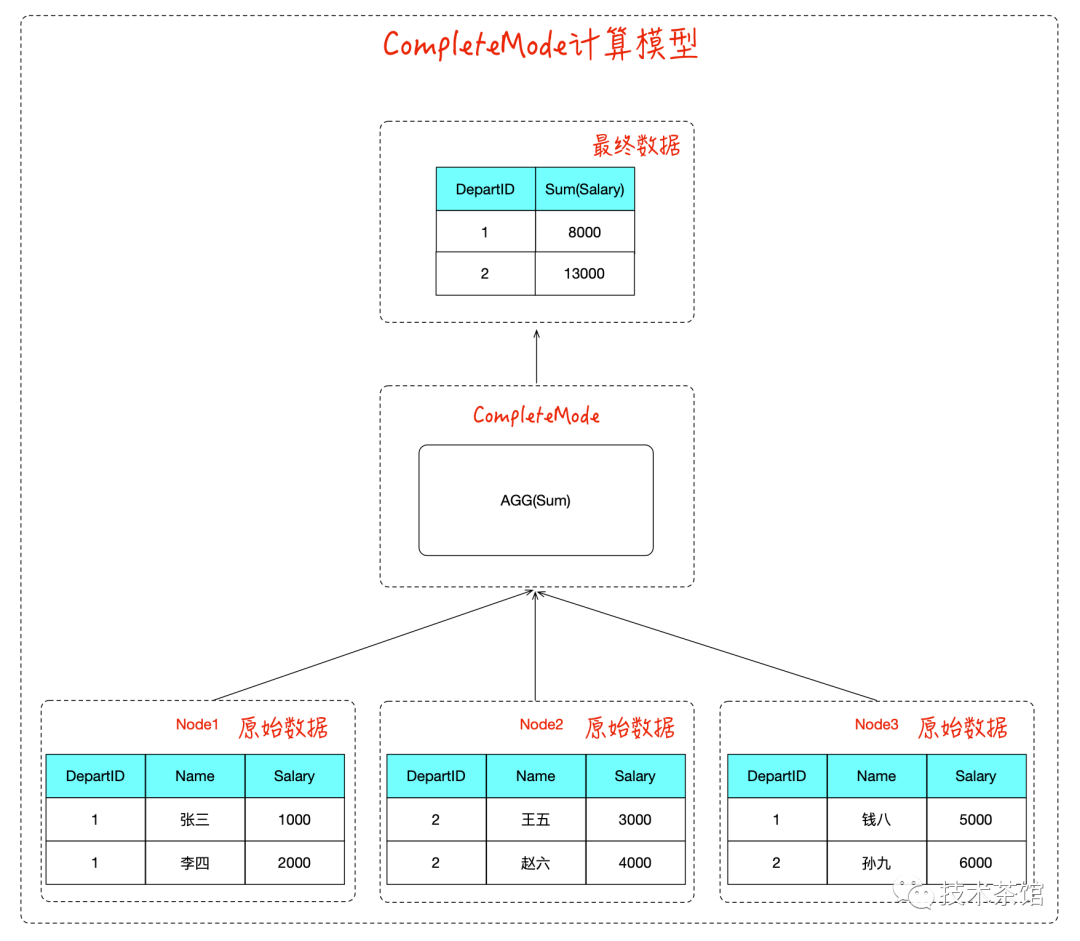
适用的场景如下:
比较适用于聚合列唯一值的数量相对比较多, 能聚合的数据比较少的场景下。
PartialMode到FinalMode模式计算模型
此时我们将聚集函数的计算过程拆成两个阶段进行,如图所示:
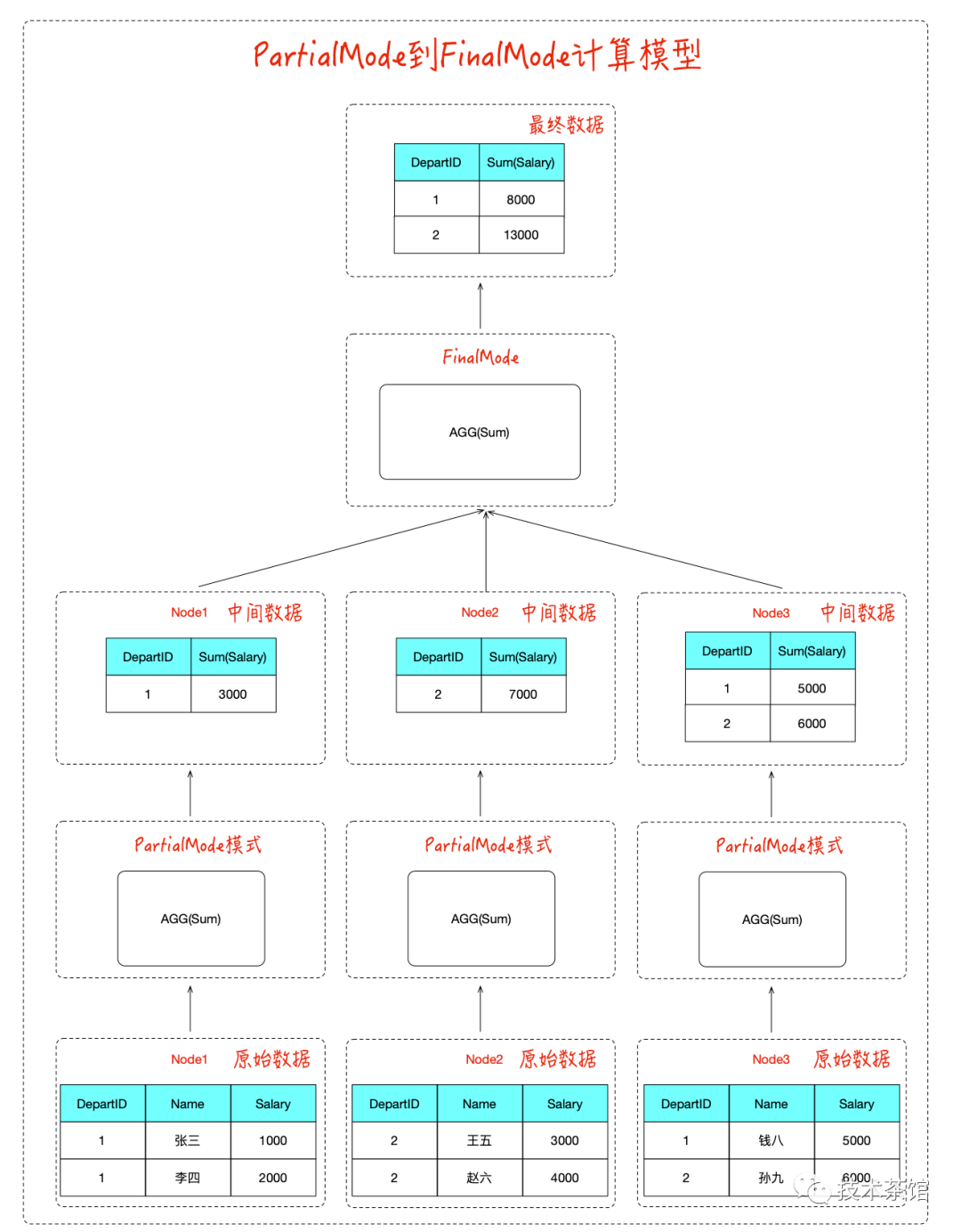
适用的场景如下:
这样做的好处是提前做了聚合运算,一部分数据已经聚合在一起,降低了网络传输数据的大小,从而提升了内存使用量和CPU利用率。
结论
本文主要介绍了数据库关于聚合功能常用的两种实现方式,Stream Aggregate和Hash Aggregate算法。并且描述了在分布式场景下聚合函数的计算模型。后续会讲解聚合函数与SIMD会碰撞出怎么样的火花,比较有代表性的是postgreSql Aggregate算法通过SIMD是如何实现的。
参考资料
- http://mysql.taobao.org/monthly/2017/01/06/
- https://juejin.im/post/6844903745029947399
- https://stackoverflow.com/questions/1471147/how-do-aggregates-group-by-work-on-sql-server/1471167#1471167
- https://techcommunity.microsoft.com/t5/sql-server/hash-aggregate/ba-p/383149
- http://mysql.taobao.org/monthly/2017/03/09/

微信公众号名称:技术茶馆
微信公众号ID : Night_ZW















 7765
7765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









