







目录
概述
现在是一个数据时代,人人都在谈“大数据”,不管身处什么行业,企业都开始注重自己的数据,想要好好利用这些数据。但现实情况是,很多数据都分布在企业不同的系统中,如企业的客户管理系统、生产系统、销售系统、采购系统、订单系统、仓储系统和财务系统等,所有数据被封存在各系统中,让完整的业务链上孤岛林立,信息的共享和反馈难,使企业无法适应当今快速多变、全球化竞争的市场环境,企业的生存和发展将面临极大的挑战。企业要想实现精细化管理,挖掘大数据背后隐藏的价值,那就必须打破数据孤岛的情况。那行业内又是怎么做的呢?
目前行业的痛点和解决方案
案例纯属虚构,如有雷同纯属巧合。
数据孤岛的产生
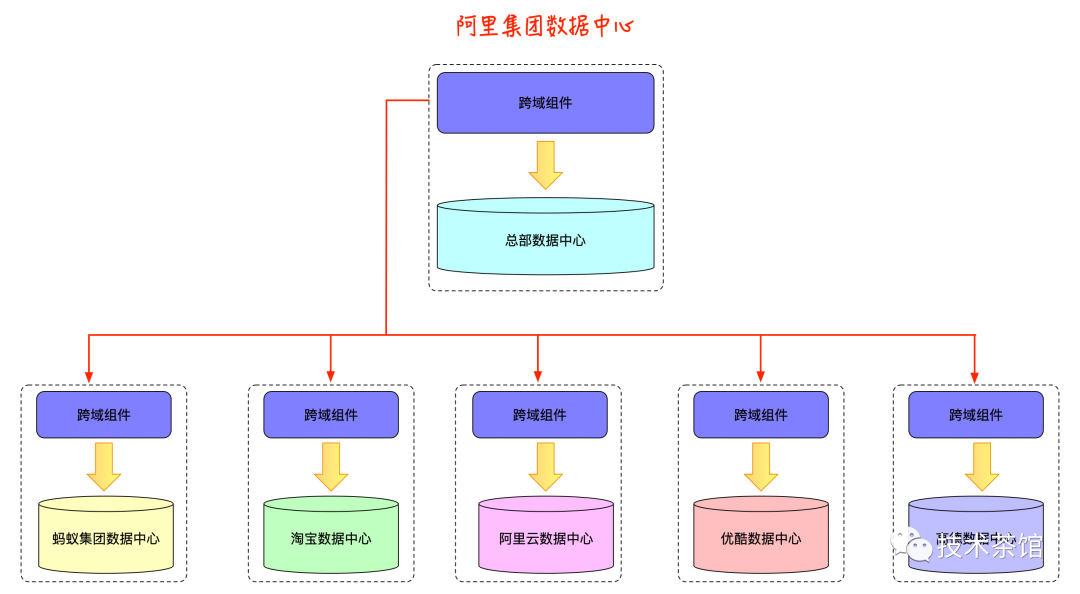
举个例子,就目前阿里涉及到的产业来说,每天会产生大量的数据信息,这些数据信息都是各个子公司来单独管理的,那么这些各个公司独立的数据,是没有办法给阿里更好的挖掘潜力客户和商品的推广的。如下图所示:
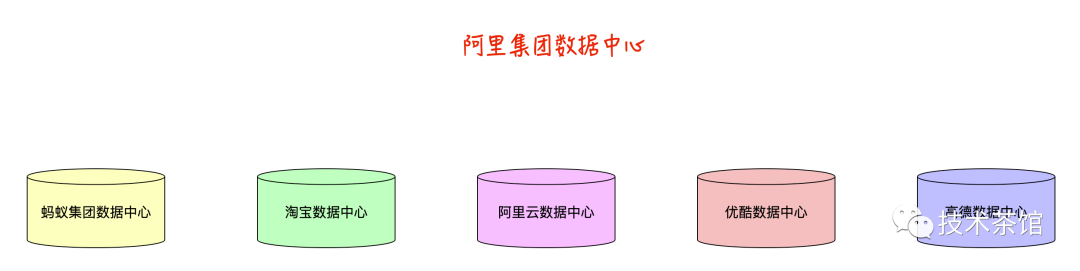
各个子公司的数据都是独立的,并且都有大量有用的数据,这样就形成了一座座数据孤岛。那么如何解决这个问题呢?
数据孤岛的解决方案
数据的物理集中
非常容易想到的是,引入了总部数据中心,各个子公司把数据都汇总给了总部数据中心,业务人员通过总部的数据中心进行客户分析和挖掘。如下图所示:
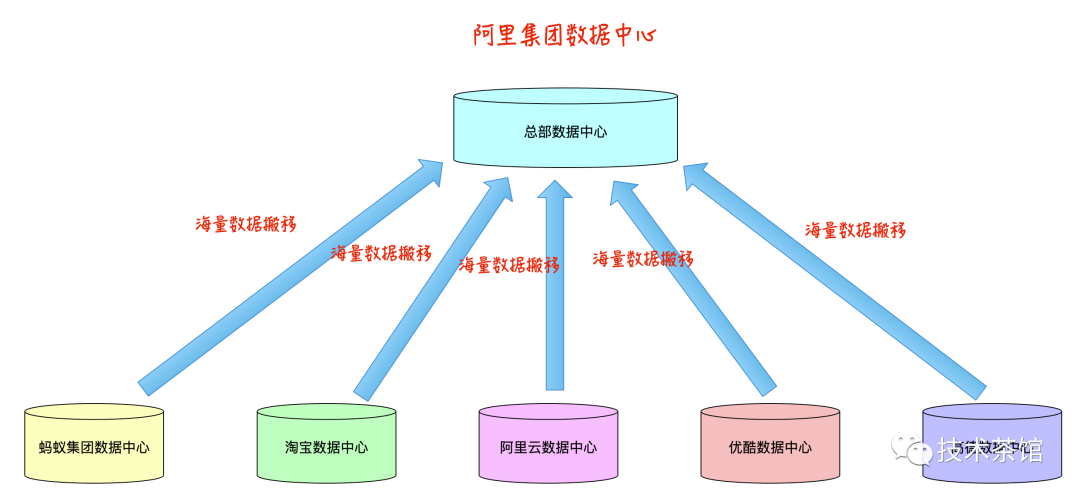
这样的实现也会产生如下问题问题
- 各个子公司每日产生大量的数据,都要通过网络传送给总部的数据中心,总部需要的物理资源非常多,用来存放各个子公司产生的数据。
- 子公司每日产生的数据,用非常好的带宽也不一定能够传输完。
- 子公司也需要物理资源存储本地产生的数据。
- 运维成本特别高,运维的压力基本都压在了总部数据中心上。
- 业务人员通过总部的数据中心查询数据,通常不能查询到各个子公司的最新数据,数据查询不及时。影响业务扩展。
- 计算资源非常浪费,基本都是总部进行计算,各个省份的物理资源通常不参与计算。
数据的逻辑集中
那么针对于上述物理集中产生的问题,有没有方案来解决的,答案肯定是有的。如下图所示
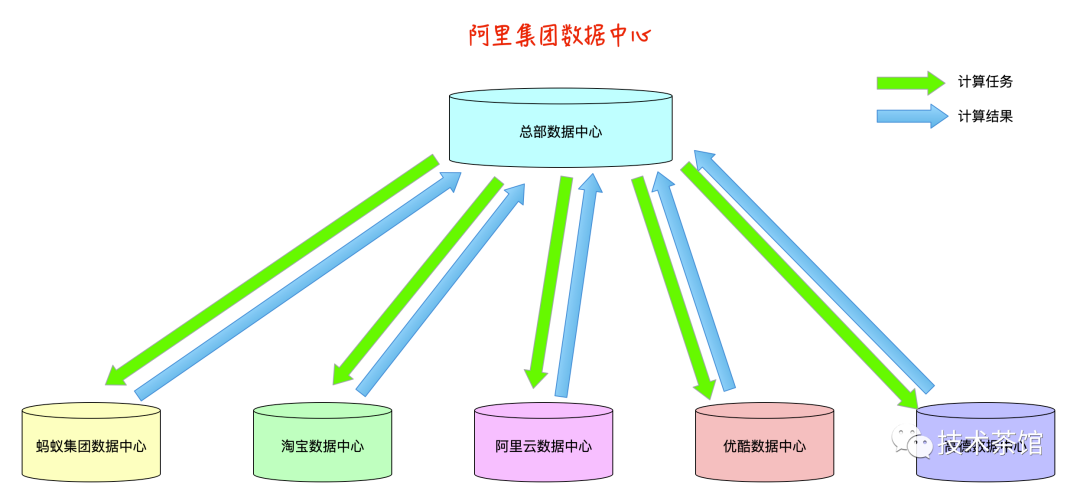
总部数据中心系统可以把业务人员查询的请求拆分成各个子公司的计算任务,通过网络把具体的任务传递过去,子公司的数据中心计算完后的结果再返回给总部数据中心系统,数据中心再反馈给业务人员。
这样各个子公司就不用把所有数据传递给总部、并且运维成本分散到了各个数据中心,各个数据中心的计算性能得到了有效的发挥。
这样我们解决了数据孤岛的问题,实现了数据共享、互利共赢的局面。那么下一个问题产生了,每一个子公司都是有属于自己的核心数据的,各个子公司也有可能属于竞争关系是吧,那么子公司的数据隐私性如何得到保证?
数据的隐私性
如上面说到的子公司的数据隐私性如何保证呢?答案也是肯定的。如下图所示
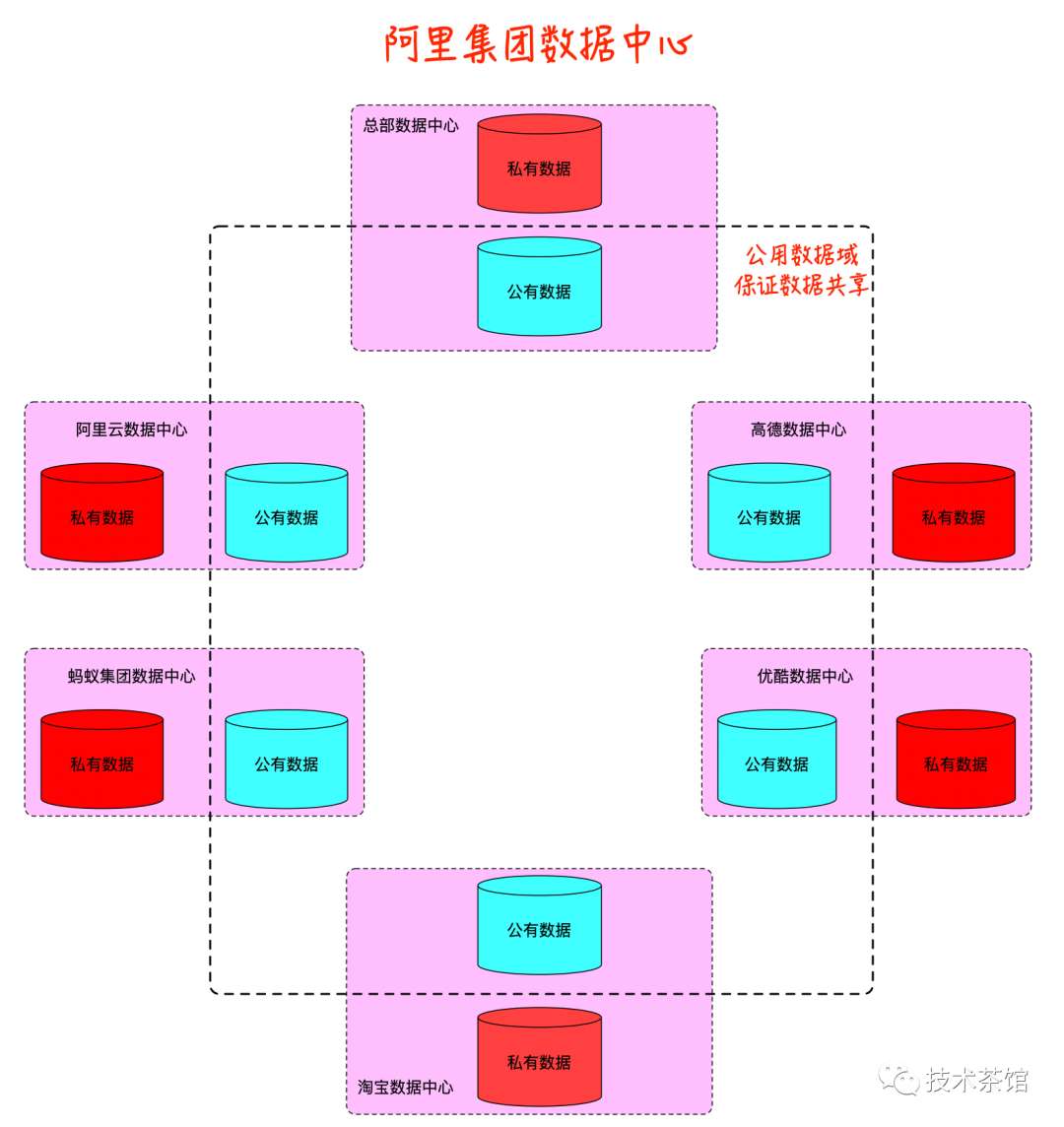
设计思想参考公有云和私有云的设计思想,有如下特点:
- 数据域拆分为私有数据域和公有数据域。
- 数据以总部逻辑集中,物理上分散到各个子公司。
- 总部统一管控, 总部进行全面的数据治理。
- 子公司使用公有数据域的全部数据,进行业务创新。
- 子公司的私有数据保持隐私性,继续开展原有的工作。
那么针对于上述,我们如何实现呢?
架构设计
大数据平台分层架构
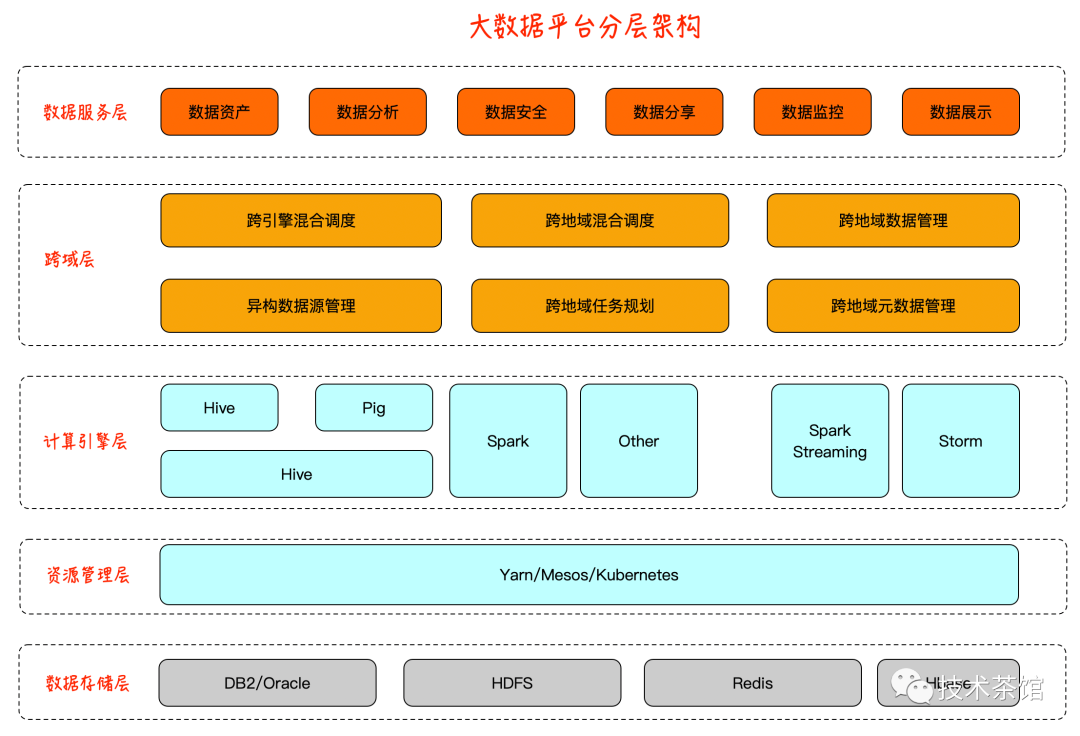
俗话说一切不能落地的设计,都是耍流氓。那么上述的设计我们如何实现呢?方案的落地,往往比方案的设计要复杂的多的多。
跨域功能的设计
跨域功能拆解成下面的子功能进行实现。如下所示
- 跨地域任务规划
- 跨地域混合调度
- 跨地域数据管理
- 跨地域元数据管理
那么看到跨域组件这些职责,有没有感觉很熟悉,除了跨地域这个特性,其他的都是标准数据库具备的功能。那么数据库只要加上跨地域是不是就可以了。例如举一个用户下发SQL,数据库执行的例子
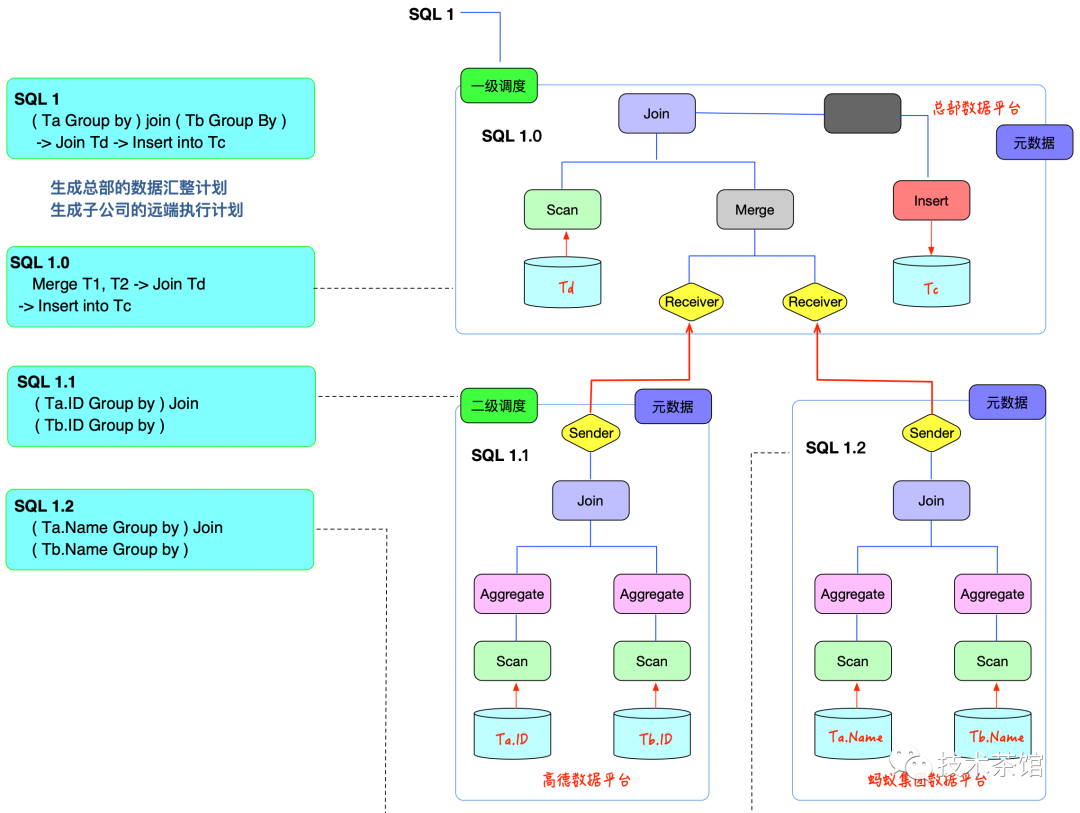
上述图的含义是总部业务人员想把各个子公司中的Ta表和Tb表聚集起来,然后使用关联操作进行数据加工,最后和总部的Td表再加工一次,最后加工完的数据,存放到Tc表中。这样各个子公司的数据有效的被利用了起来。数据库实现步骤如下
- 数据库接收到用户的SQL,通过元数据,分析语法中涉及到的数据源在哪里有数据。
- 拆解用户下发的SQL,转化成子SQL任务下发给子公司。
- 子公司接收到子SQL任务,进行查询加工操作。
- 加工后的数据传递给总部。
- 总部接收到子公司的数据后与本地数据再次进行查询加工操作。
- 最后加工出来的结果放到总部数据库中。
跨域功能解决了数据孤岛的问题,那么下面我们看看数据的隐私性如何保证?
数据域的设计
跨域组件会把数据分为私有数据域和公有数据域,子数据中心的业务人员把想要共享的数据放到公有数据域上面,跨域组件会把表的定义和表所在的位置广播给其他的数据中心,其他的数据中心会把表的定义和表所在的位置放到自己本地的元数据路由表中。如下图所示:
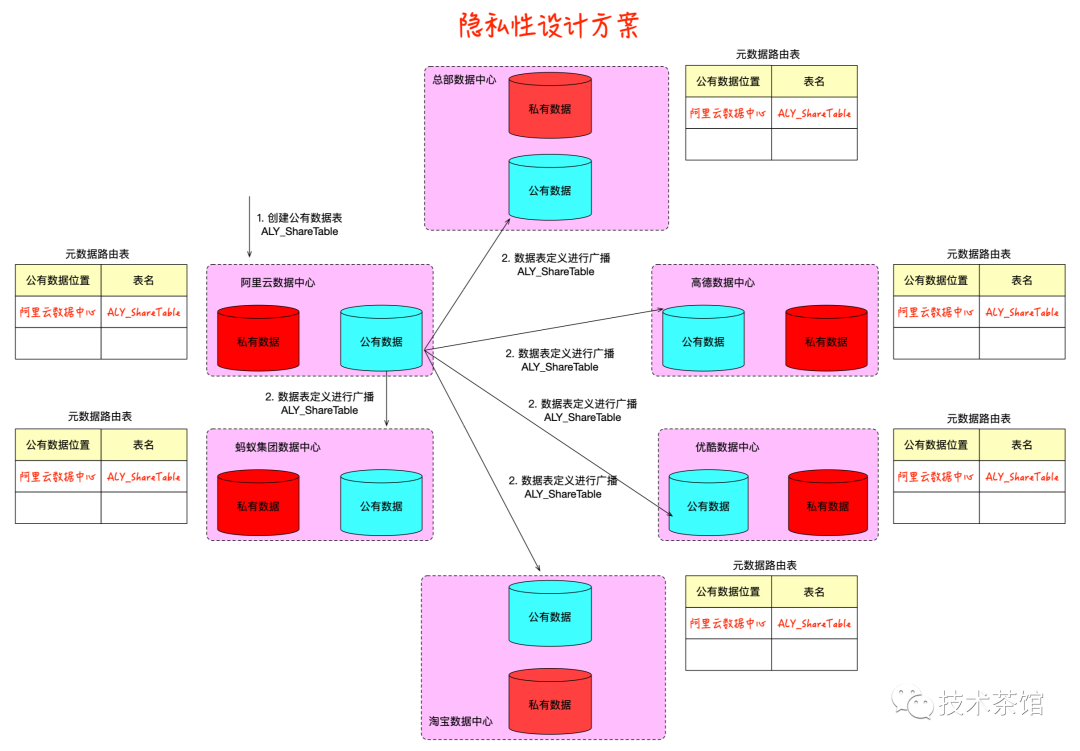
业务人员在其他数据中心查询公有数据域中的数据时,跨域组件会根据自己本地的元数据路由表,把相应的任务转发给具体的数据中心处理。数据中心把结果再返回回来。
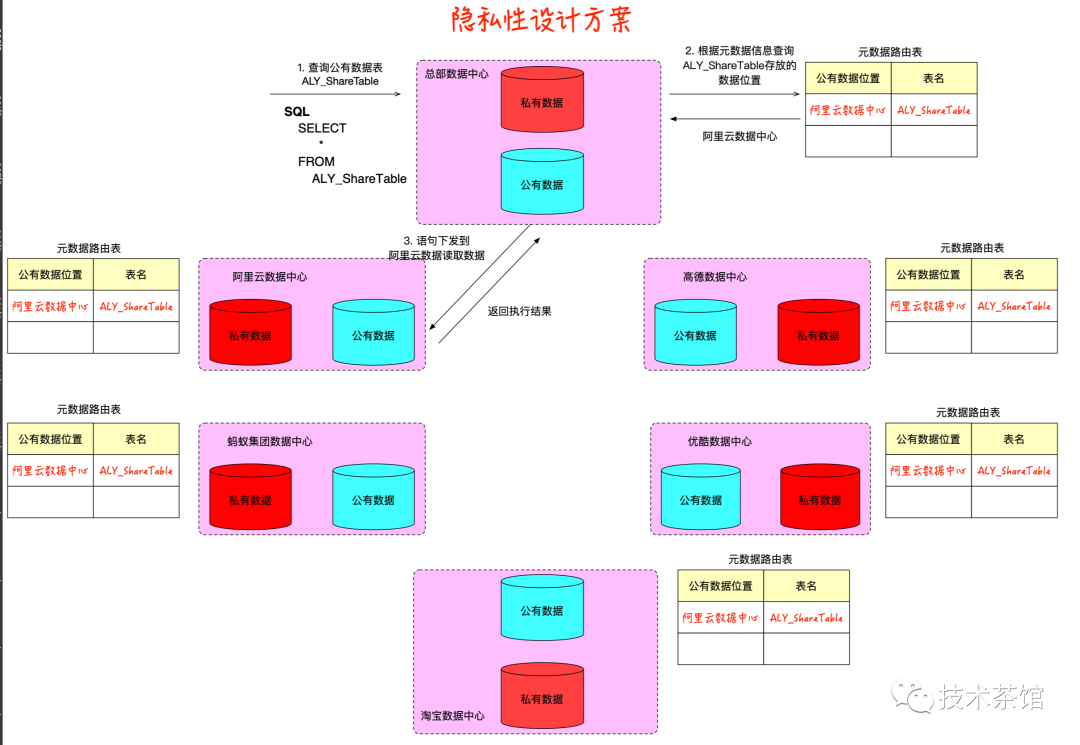
数据的隐私性通过这个方案可以保证,但是过程中发现,各个数据中心使用的数据源是不一样的,例如有些数据中心采用的是HBase方案、Oracle方案、Mysql方案,Hive方案。那么我们如何解决呢?
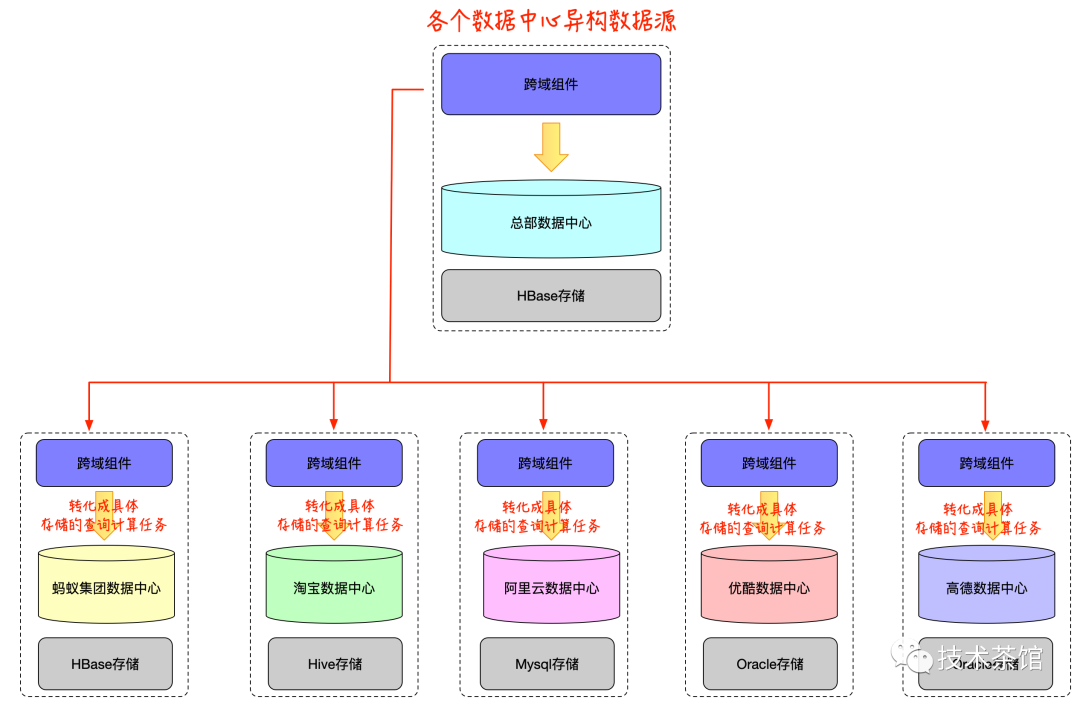
异构数据源的管理
子公司的数据中心接受到总部发送过来的查询计算的计划后,通过本地元数据信息知道查询任务中涉及的存储引擎是什么,转化成具体的存储引擎执行任务,再交给具体的存储引擎去执行。这样就把异构的数据源的计算引擎进行了整合,避免了数据落地,就可以进行多种计算引擎交叉的分析。如下图所示:
结论
我们可以通过数据库的现有功能,非常方便的搭建出一套大数据平台架构。并把各个计算引擎进行整合,让客户的操作复杂程度大大的降低了。并把数据库中存储的数据划分为两个数据域,公有数据域和私有数据域,让企业更好的利用自身的数据进行数据挖掘和分析。并且打破数据孤岛的情况。
参考资料
- http://www.cirrodata.com/product/mdc

微信公众号名称:技术茶馆
微信公众号ID : Night_ZW


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









