







本文主要介绍如何使用Java运行时级别的注解配合反射来搭建框架,以下是构建sql表的简单例子虽然不能运用到实际中,但是阐明了搭建运行时框架的方法。源码已经上传至github,链接
如果你对注解的相关基础不了解,可以先阅读 Java注解(1)-基础
实现功能
先看一下要实现的效果,通过给数据类Bean添加相应的注解@Table ,@Column,就可以获取到创建表的sql语句
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
执行输出
- 1
- 1
自定义注解
由于我们搭建的是运行时框架,需要再运行时通过反射来进行,所以注解的级别必须设置成Runtime级别,这样运行时才能反射到相应的注解
通过下面的定义,我们就能在运行时动态获取@Table与@Retention两个注解与其对应的名称
- 定义对应表的注解
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- 定义对应字段的注解
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
运行时获取注解并转化
基础API
AnnotatedElement代表能够被注解的元素,如方法,成员变量,方法参数,包,类都是这个接口的实现,AnnotatedElement有方法如下表:
| 方法名 | 用法 |
|---|---|
| Annotation getAnnotation(Class annotationType) | 获取注解在其上的annotationType |
| Annotation[] getAnnotations() | 获取所有注解 |
| isAnnotationPresent(Class annotationType) | 判断当前元素是否被annotationType注解 |
| Annotation[] getDeclareAnnotations() | 与getAnnotations() 类似,但是不包括父类中被Inherited修饰的注解 |
返回的Annotation是注解的实例,可以反射Method获取需要的值,即是获取@Column或者@Table中name的值。
框架工具的实现
我们通过反射技术,运行时获取注解,从而得到Bean类对应的数据库的表的建表sql语句
获取表名
如下代码,先判断Bean类是否有注解@Table,如果有则获取@Table对象并得到name方法的值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
获取字段名与类型
逐个分析Bean的成员变量是否有被@Column注解,有则获取其对应的字段名与类型
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
生成建表sql语句
生成sql表语句比较简单,主要是把前两部份获取的表名与字段结合起来组合成sql语句
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
优势与缺点
用运行时注解来搭建框架相对容易而且适用性也比较广,搭建的框架使用起来也比较简单。对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping)框架通常使用运行时注解来搭建,但是在此基础上的框架因为需要用到反射,其效率相对与不高。所以因为效率考虑,许多框架不使用运行时注解来搭建而是用源码级别注解来搭建,当然,使用源码级别框架也是有代价的,由于它只能在预编译期间生成额外代码而无法运行时反射操作,复杂度相对较高而且灵活性也相对较低。如何使用源码级别注解框架来搭建会在下面。
源码级框架
上面介绍的运行时框架是在虚拟机运行程序时使用反射技术搭建的框架;而源码级框架是在javac编译源码时,生成框架代码或文件。因为源码级别框架发生过程是在编译期间,所以并不会过多影响到运行效率。因此,搭建框架时候应该优先考虑使用源码级别框架。
注解处理器
注解处理器能够在编译源码期间扫描Java代码中的注解,并且根据相关注解动态生成相关的文件。之后在程序运行时就可以使用这些动态生成的代码。值得注意的是,注解处理器运行在跟最终程序不同的虚拟机,也就是说,编译器为注解处理器开启了另外一台虚拟机来运行注解处理器。
步骤
要为工程添加一个注解处理器,需要以下几步
实现AbstractProcessor
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
生成注解处理器jar
对于eclipse,
jar的目录结构如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
META-INF中的文件需要自己手动创建,其中文件javax.annotation.processing.Processor里写明需要运行的处理器的类名,如
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
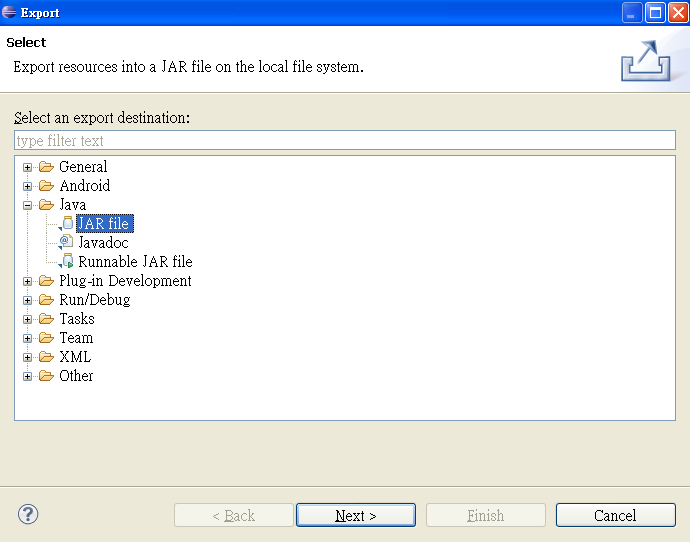
选中需要生成jar的工程,右击–>Export–>JarFile,如下图
对于Android studo
1.注解器模块配置如下
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
2.Android studio会自动生成为javax.annotation.processing.Processor,只需为注解器添加@AutoService注解,这样就可以自动生成META-INF内的文件,如下
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
指定注解器jar
这步主要是让编译器在编译时知道某些jar包是注解器jar,下面分命令行,eclipse和AndroidStudio三种情况分别介绍
- 命令行的方式
- 1
- 1
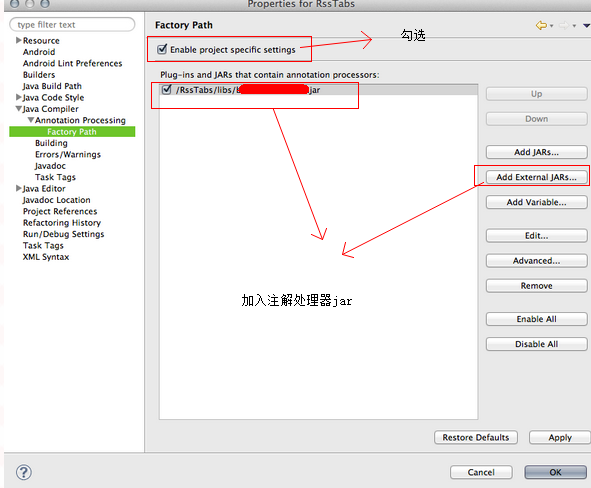
- eclipse的配置
第一步
第二步

- Android studio配置
工程的build.gradle:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
模块的build.gradle:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注解处理器接口
注解处理一般均需要重写以下四个方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
PS:java7之后,getSupported***()方法可以用一下注解代替
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
打印日志
注解处理器的打印日志全部应该交由Messager处理,并且需要在打印错误时利用异常抛出来终止处理器
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
扫描处理流程
注解处理器对工程代码的扫描是多次的,可以注意到AbstractProcessor的process()方法的输入参数有一个是RoundEnvironment,这个代表一次扫描的结果。
影响注解处理器执行顺序与逻辑的地方有三处
1.javax.annotation.processing.Processor中的书写顺序决定注册处理器的执行顺序
假设该文件中定义如下:
- 1
- 2
- 1
- 2
那么编译器每一轮扫描会先执行处理器ProcessorB,再执行处理器ProcessorA
2.AbstractProcessor中processor()方法的返回值决定是否要终结当前轮的处理
按照1中注册的顺序,假如ProcessorB中的process()方法返回true,则表示消费完这轮的注解扫描,将不再执行ProcessorA,只有当返回false时,才会接下来执行ProcessorB
3.没有输出文件跟输入文件时扫描结束
假设按照1中的注册顺序,ProcessorB中的process()方法返回true,并且ProcessorB在第一轮扫描会生成按文件GenerateB.java,则将在第三轮扫描后结束注解处理,过程如下
| 过程 | 输入文件 | 输出文件 |
|---|---|---|
| 第一轮 | 原工程 | GenerateB.java |
| 第二轮 | GenerateB.java | 无 |
| 第三轮 | 无 | 无 |
第三轮时编译器发现没有输出文件也没有输入文件,处理结束
PS:每个注解处理器在整个过程中都保持同一个实例
分包机制
注解处理器会生成一些代码文件,我们会写一些API调用这些代码。所以,源码级框架除了写注解处理器外,还要写一个API包。另外,由于源码级别的注解并不需要模块划分时候应该将注解处理器跟API分成两个模块来写,有利于缩小编译后体积。(以下简称其所在的包分别是处理器包 跟 API包 )
处理器包使用周期与API包不同:
- 处理器包:注解处理器只需要在目标工程编译时候执行,运行时不需要
- API包:API包因为会被目标工程运行时调用,所以在目标工程编译时和运行时都是需要的
由于这些不同,处理器包跟API包在工程中有不同的引用形式,如下
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
语言模型包的使用
Mirror
注解处理器因为操作的是源码,所以需要用到JAVA语言模型包,javax.lang.model及其子包都是Java的语言模型包。这个包是采用了Mirror设计,Java是一种可以自描述的语言,其反射机制就是一种自描述,传统的反射机制将自描述与其他操作合并在一起,Mirror机制将自描述跟其他操作隔离,自描述部分是Meta level,其他部分是Base level
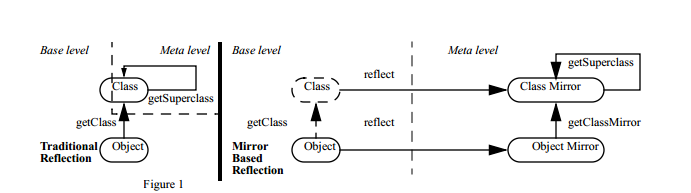
转化
Element代表语言元素,比如包,类,方法等,但是Element并没有包含自身的信息,自身信息要通过Mirror来获取,每个Element都指向一个TypeMirror,这个TypeMirror里有自身的信息。通过下面获方法取Element中的Mirror
- 1
- 1
TypeMirror类型是DeclaredType或者TypeVariable时候可以转化成Element
- 1
- 2
- 1
- 2
获取类型
获取Element或者TypeMirror的类型都是通过getKind()获取类型,但是返回值虽然不同,但是都是枚举。
- 1
- 2
- 1
- 2
针对具体类型,要避免用instanceof,因为即使同一个类getKind()也有不同的结果。比如TypeElemnt的getKind()返回结果可以是枚举,类,注解,接口四种。
源码中移动
比如一个类里面有方法,成员变量等,这个类相对于方法跟成员变量就是外层元素,而成员变量和方法相对于类就是内层元素。
Element是代表源码的类,源码中移动到其他位置必须是用Element,比如移动到当前元素的外层元素TypeElement
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
也可以使用getEnclosedElements()获取当前Element内层的所有元素。
类继承树结构中移动
TypeMirror是用来反应类本身信息的类,在继承树移动必须用到TypeMirror,比如查找某个类的父类
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
处理MirroredTypeException
编译器使用注解处理器来处理目标代码时候,目标源码还没有编译成字节码,所以任何指向目标源码字节码的代码都会发生MirroredTypeException。最常见的例子见下面
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 1
- 2
- 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注解处理器之所有MirroredTypeException,是因为此时类A还没有被编译成字节码,所以A.class不存在,解决这个问题需要异常,利用异常我能获取类A的名字等信息,但是却得不到A.class,如下















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









