






查询优化基本思路
遇到数据库性能问题,一般从下面3个方面分析
- 操作系统(内存、CPU、I/O)
- 实例(数据库架构、DM_INI 参数)
- SQL(性能监控视图、SQL 日志)
操作系统性能诊断
LINUX常用性能监控命令
使用top命令查看CPU使用率(按shift+p可以使结果按照CPU利用率排序)
top - 17:40:37 up 21 days, 19:20, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 95 total, 1 running, 94 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.7 sy, 0.0 ni, 98.2 id, 0.5 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2046504 total, 89196 free, 797228 used, 1160080 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1076236 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2129 root 20 0 1013620 70988 12940 S 0.7 3.5 379:14.70 YDService
1603 dmdba 20 0 161976 2216 1564 R 0.3 0.1 0:00.01 top
8172 root 20 0 755496 15744 2632 S 0.3 0.8 114:02.19 barad_agent
30616 dmdba 20 0 608840 39652 5292 S 0.3 1.9 125:37.02 dmmonitor
1 root 20 0 191060 3948 2448 S 0.0 0.2 3:08.27 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.56 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 2:23.14 ksoftirqd/0
7 root rt 0 0 0 0 S 0.0 0.0 0:08.64 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 19:16.40 rcu_sched
使用iostat命令查看磁盘 I/O 使用情况
[dmdba@monitor ~]$ iostat
Linux 3.10.0-1160.88.1.el7.x86_64 (monitor) 07/25/2023 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.63 0.00 0.78 0.66 0.00 97.92
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 26.88 3.05 198.45 5750110 373907162
scd0 0.00 0.00 0.00 6226 0
使用dstat工具查看磁盘 I/O 使用情况
使用dstat更直观,默认收集CPU、IO等,每秒刷新一次
[dmdba@monitor ~]$ dstat
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
1 1 98 1 0 0|3130B 198k| 0 0 | 0 0 | 880 1466
1 1 98 1 0 0| 0 60k| 10k 4100B| 0 0 | 970 1555
2 2 97 1 0 0| 0 569k| 11k 4787B| 0 0 |1217 1975
1 1 98 1 0 0| 0 256k| 10k 4094B| 0 0 | 975 1594
1 1 97 1 0 0| 0 276k| 10k 5152B| 0 0 |1064 1781
1 1 99 1 0 0| 0 141k| 11k 4322B| 0 0 | 839 1427
1 1 99 0 0 0| 0 120k|9971B 2856B| 0 0 | 785 1320
1 1 99 1 0 0| 0 64k|9655B 2558B| 0 0 | 754 1251
1 1 99 0 0 0| 0 249k| 12k 5239B| 0 0 | 941 1545
1 1 98 1 0 1| 0 192k| 10k 3712B| 0 0 | 856 1456
1 1 89 11 0 0| 0 252k| 10k 2848B| 0 0 | 833 1351
1 1 98 1 0 0| 0 141k|9805B 3979B| 0 0 | 781 1313
使用free命令查看内存使用情况
[dmdba@monitor ~]$ free -g
total used free shared buff/cache available
Mem: 1 0 0 0 1 1
Swap: 0 0 0
[dmdba@monitor ~]$ free -m
total used free shared buff/cache available
Mem: 1998 780 136 0 1081 1048
Swap: 0 0 0
使用nmon工具监控系统一段时间的整体情况

数据库架构优化

数据库参数
根据数据库安装脚本中数据参数优化脚本进行优化(脚本地址:https://download.csdn.net/download/NinjaKilling/86406612)
数据库会话监控
查询活动会话数
SELECT COUNT(*) FROM V$SESSIONS WHERE STATE='ACTIVE';
已执行超过2秒的活动SQL
SELECT * FROM (
SELECT SESS_ID,SQL_TEXT,DATEDIFF(SS,LAST_SEND_TIME,SYSDATE) Y_EXETIME,SF_GET_SESSION_SQL(SESS_ID) FULLSQL,CLNT_IP
FROM V$SESSIONS WHERE STATE='ACTIVE')
WHERE Y_EXETIME>=2;
锁查询
SELECT O.NAME,L.* FROM V$LOCK L,SYSOBJECTS O WHERE L.TABLE_ID=O.ID AND BLOCKED=1;
阻塞查询
WITH LOCKS AS(
SELECT O.NAME,L.*,S.SESS_ID,S.SQL_TEXT,S.CLNT_IP,S.LAST_SEND_TIME FROM V$LOCK L,SYSOBJECTS O,V$SESSIONS S
WHERE L.TABLE_ID=O.ID AND L.TRX_ID=S.TRX_ID ),
LOCK_TR AS ( SELECT TRX_ID WT_TRXID,ROW_IDX BLK_TRXID FROM LOCKS WHERE BLOCKED=1),
RES AS( SELECT SYSDATE STATTIME,T1.NAME,T1.SESS_ID WT_SESSID,S.WT_TRXID,
T2.SESS_ID BLK_SESSID,S.BLK_TRXID,T2.CLNT_IP,SF_GET_SESSION_SQL(T1.SESS_ID) FULSQL,
DATEDIFF(SS,T1.LAST_SEND_TIME,SYSDATE) SS,T1.SQL_TEXT WT_SQL FROM LOCK_TR S,LOCKS T1,LOCKS T2
WHERE T1.LTYPE='OBJECT' AND T1.TABLE_ID<>0 AND T2.LTYPE='OBJECT' AND T2.TABLE_ID<>0
AND S.WT_TRXID=T1.TRX_ID AND S.BLK_TRXID=T2.TRX_ID)
SELECT DISTINCT WT_SQL,CLNT_IP,SS,WT_TRXID,BLK_TRXID FROM RES;
SQL优化
数据库的性能问题最终都要涉及到SQL优化
处理流程:
生成日志→日志入库→分析SQL→优化方案
生成SQL日志
设置SQL过滤规则,只记录必要的SQL,生产环境不要设成1
– 2 只记录DML语句 3 只记录DDL语句 22 记录绑定参数的语句
– 25 记录SQL语句和它的执行时间 28 记录SQL语句绑定的参数信息
SF_SET_SYSTEM_PARA_VALUE('SQL_TRACE_MASK','2:3:22:25:28',0,1);
同步日志会严重影响系统效率,生产环境必须设置为异步日志
SF_SET_SYSTEM_PARA_VALUE('SVR_LOG_ASYNC_FLUSH',1,0,1);
下面这个语句设置只记录执行时间超过200MS的语句
SF_SET_SYSTEM_PARA_VALUE('SVR_LOG_MIN_EXEC_TIME',200,0,1);
下面的语句查看设置是否生效
SELECT * FROM V$DM_INI WHERE PARA_NAME='SVR_LOG_ASYNC_FLUSH';
SELECT * FROM V$DM_INI WHERE PARA_NAME='SQL_TRACE_MASK';
SELECT * FROM V$DM_INI WHERE PARA_NAME='SVR_LOG_MIN_EXEC_TIME';
开启SQL日志
SP_SET_PARA_VALUE(1, 'SVR_LOG', 1);
关闭SQL日志
SP_SET_PARA_VALUE(1, 'SVR_LOG', 0);
SQL日志分析流程
用JAR包分析sql(JAR包下载地址:https://download.csdn.net/download/NinjaKilling/88098240)

200ms以上的sql汇总

1次以上的sql汇总
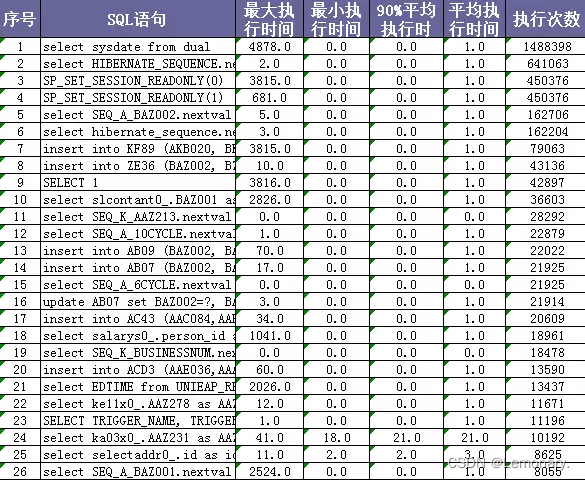
SQL汇总分析
优化目标
- List item
并发非常高
SQL特征:数量很少(5%),但是执行频率非常高,甚至达到每秒上百次,只要一慢,系统很可能瘫痪。优化级别:最优先处理。
- List item
并发一般
SQL特征:占大多数(80%),如果有慢的,对系统整体稳定性影响不大,但是会造成局部的某些操作慢。优化级别:次优先处理。
- 并发很少特别慢
SQL特征:数量少(15%),往往是很复杂的查询,可能一天就执行几次,对系统整体影响不大,但是优化难度很大。优化级别:最后处理。
确定目标SQL
如XX项目,入库生产SQL日志,汇总分析,最终找出待优化的3类目标SQL,如下图。接着就去做具体的SQL优化了。
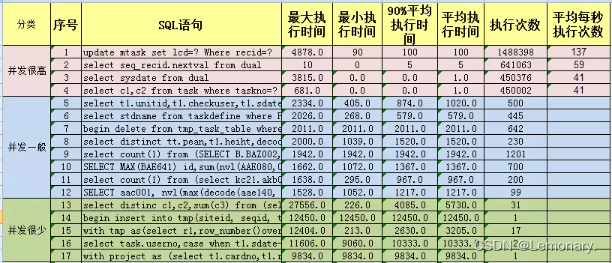
SQL优化思路
- 高并发SQL
- 单个SQL调到最快
普通索引
聚集索引
覆盖索引 - 优化应用,减少执行次数
应用做结果集缓存
优化应用逻辑,减少无用的执行
将SQL分散其他数据库节点
- 一般并发SQL
- 使用索引
单列索引
组合索引 - 改写SQL
left join等价改为inner join
避免隐式转换不走索引
将过滤条件上拉,走索引
用分析函数,减少表扫描
优化升级:
普通索引→聚集索引、覆盖索引→优化应用,减少执行次数
高并发SQL优化案例
XX项目刚上线,并发很大,IO、CPU都很高,数据库经常瘫痪。分析SQL日志,找出几条执行次数最多的SQL,如下图:

分析及优化:

效果:优化后系统比较稳定,IO、CPU降到原来的1/3,瘫痪次数大大减少。
SQL性能分析工具-ET
ET是DM7自带的分析工具,能统计SQL每个操作符的时间花费,从而定位到有性能问题的操作,指导用户去优化。
INI参数 ENABLE_MONITOR=1、 时,ET才能使用。
另需修改参数 MONITOR_SQL_EXEC、MONITOR_TIME
SP_SET_PARA_VALUE(1,'MONITOR_SQL_EXEC',1);
SP_SET_PARA_VALUE(1,'MONITOR_TIME',1);
创建测试表
CREATE TABLE T1 AS
SELECT LEVEL C1,LEVEL||'ABC' C2 FROM DUAL CONNECT BY LEVEL<=10000;
查询
SELECT * FROM T1 WHERE C2 LIKE '5000%';

得到执行号:37934,作为ET的参数
CALL ET(37934);
或者直接单击执行号
执行计划
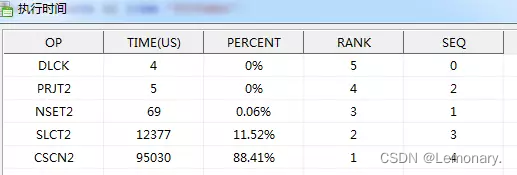
1 #NSET2: [1, 1, 60]
2 #PRJT2: [1, 1, 60]; EXP_NUM(3), IS_ATOM(FALSE)
3 #SLCT2: [1, 1, 60]; (T1.C2 >= 5000 AND T1.C2 < 5001)
4 #CSCN2: [1, 10000, 60]; INDEX33555585(T1)
优化建议:C2字段创建索引,更新统计信息,消除全表扫描。
CREATE INDEX IDX_C2_T1 ON T1(C2);
SP_COL_STAT_INIT_EX('SYSDBA','T1','C2',100);
优化后执行计划
1 #NSET2: [0, 1, 60]
2 #PRJT2: [0, 1, 60]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [0, 1, 60]; IDX_C2_T1(T1)
4 #SSEK2: [0, 1, 60]; scan_type(ASC), IDX_C2_T1(T1), scan_range[5000abc,5000abc]
阻塞与死锁
阻塞和死锁是拖慢系统性能的两大元凶。
二者有些差异:
- 死锁是相互堵塞;而阻塞是单向的
- 数据库自动识别死锁并解锁;而阻塞不能
- SQL日志中会记录死锁信息;而阻塞没有,需要人工分析
下图中记录了一条死锁信息:

阻塞产生的原因及解决思路:
- 相同数据的并发操作是主因,业务上尽量避免热点数据的批量操作,比如多个审核员同时从作业池中随机取10张单子,就很可能取到重复,造成阻塞。
- 慢SQL会使阻塞恶化,加大了阻塞的时间,应尽量优化SQL。
阻塞分析过程
- 监控阻塞会话,同时保证sql日志已经打开
with locks as(
select o.name,l.*,s.sess_id,s.sql_text,s.clnt_ip,s.last_send_time from v$lock l,sysobjects o,v$sessions s
where l.table_id=o.id and l.trx_id=s.trx_id ),
lock_tr as ( select trx_id wt_trxid,row_idx blk_trxid from locks where blocked=1),
res as( select sysdate stattime,t1.name,t1.sess_id wt_sessid,s.wt_trxid,
t2.sess_id blk_sessid,s.blk_trxid,t2.clnt_ip,SF_GET_SESSION_SQL(t1.sess_id) fulsql,
datediff(ss,t1.last_send_time,sysdate) ss,t1.sql_text wt_sql from lock_tr s,locks t1,locks t2
where t1.ltype='OBJECT' and t1.table_id<>0 and t2.ltype='OBJECT' and t2.table_id<>0
and s.wt_trxid=t1.trx_id and s.blk_trxid=t2.trx_id)
select distinct wt_sql,clnt_ip,ss,wt_trxid,blk_trxid from res;
-
监控到阻塞信息,并保留数据,供后面分析使用

可以看出事务[316624]被事务[316646]所阻塞,后面可以从sql日志中找到完整事务给应用分析 -
将SQL日志入库,表名为log_commit,表结构如下
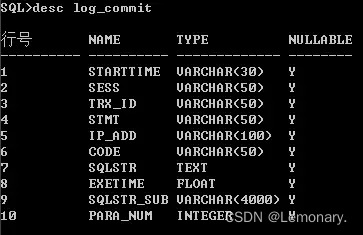
-
找出阻塞的两个事务,然后优化慢sql,同时反馈给应用去优化业务
等待的事务
select trx_id,starttime,sqlstr,exetime from log_commit where trx_id='316624';
阻塞的源头事务
select trx_id,starttime,sqlstr,exetime from log_commit where trx_id='316646';
DM7执行计划详解
什么是执行计划?
一条SQL语句在DM数据库中执行过程或访问路径的描述
如何查看执行计划?
通过EXPLAIN命令查看
EXPLAIN SELECT * FROM SYSOBJECTS;
1 #NSET2: [0, 1711, 396]
2 #PRJT2: [0, 1711, 396]; exp_num(17), is_atom(FALSE)
3 #CSCN2: [0, 1711, 396]; SYSINDEXSYSOBJECTS(SYSOBJECTS as SYSOBJECTS)
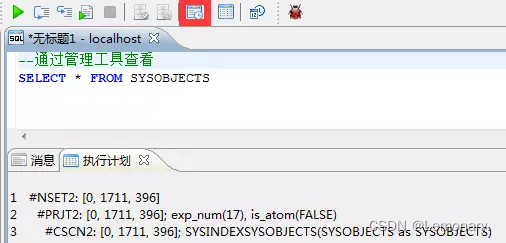
执行计划包含哪些重要信息?
- 一个执行计划由若干个计划节点组成,如上图中的1、2、3
- 每个计划节点中包含操作符(CSCN2)和它的代价([0, 1711, 396])等信息
- 代价由一个三元组组成[代价,记录行数,字节数]
- 代价的单位是毫秒,记录行数表示该计划节点输出的行数,字节数表示该计划节点输出的字节数
- 解读一下第三个计划节点:操作符是CSCN2即全表扫描,代价估算是0ms,扫描的记录行数是1711行,输出字节数是396个
常用操作符解读
准备测试表和数据
DROP TABLE T1;
DROP TABLE T2;
CREATE TABLE T1(C1 INT ,C2 CHAR(1),C3 VARCHAR(10) ,C4 VARCHAR(10) );
CREATE TABLE T2(C1 INT ,C2 CHAR(1),C3 VARCHAR(10) ,C4 VARCHAR(10) );
INSERT INTO T1
SELECT LEVEL C1,CHR(65+MOD(LEVEL,57)) C2,'TEST',NULL FROM DUAL
CONNECT BY LEVEL<=10000;
INSERT INTO T2
SELECT LEVEL C1,CHR(65+MOD(LEVEL,57)) C2,'TEST',NULL FROM DUAL
CONNECT BY LEVEL<=10000;
CREATE INDEX IDX_C1_T1 ON T1(C1);
SP_INDEX_STAT_INIT(USER,'IDX_C1_T1');
收集结果集:NSET
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
用于结果集收集的操作符,一般是查询计划的顶层节点
投影:PRJT
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
关系的“投影”(project)运算,用于选择表达式项的计算;广泛用于查询,排序,函数索引创建等
选择:SLCT
EXPLAIN SELECT * FROM T1 WHERE C2='TEST';
1 #NSET2: [1, 250, 156]
2 #PRJT2: [1, 250, 156]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [1, 250, 156]; T1.C2 = TEST
4 #CSCN2: [1, 10000, 156]; INDEX33556717(T1)
关系的“选择” 运算,用于查询条件的过滤。
简单聚集:AAGR
EXPLAIN SELECT COUNT(*) FROM T1 WHERE C1 = 10;
1 #NSET2: [0, 1, 4]
2 #PRJT2: [0, 1, 4]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [0, 1, 4]; grp_num(0), sfun_num(1)
4 #SSEK2: [0, 1, 4]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
用于没有group by的count sum age max min等聚集函数的计算
快速聚集:FAGR
EXPLAIN SELECT COUNT(*) FROM T1;
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [1, 1, 0]; sfun_num(1)
EXPLAIN SELECT MAX(C1) FROM T1;
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
#FAGR2: [1, 1, 0]; sfun_num(1)
用于没有过滤条件时从表或索引快速获取MAX/MIN/COUNT值;
DM数据库是世界上单表不带过滤条件下取COUNT值最快的数据库。
HASH分组聚集:HAGR
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C2;
1 #NSET2: [1, 100, 48]
2 #PRJT2: [1, 100, 48]; exp_num(1), is_atom(FALSE)
3 #HAGR2: [1, 100, 48]; grp_num(1), sfun_num(1)
4 #CSCN2: [1, 10000, 48]; INDEX33556717(T1)
用于分组列没有索引只能走全表扫描的分组聚集,C2列没有创建索引
流分组聚集:SAGR
EXPLAIN SELECT COUNT(*) FROM T1 GROUP BY C1;
1 #NSET2: [1, 100, 4]
2 #PRJT2: [1, 100, 4]; exp_num(1), is_atom(FALSE)
3 #SAGR2: [1, 100, 4]; grp_num(1), sfun_num(1)
4 #SSCN: [1, 10000, 4]; IDX_C1_T1(T1)
用于分组列是有序的情况下,可以使用流分组聚集,C1上已经创建了索引,SAGR2性能优于HAGR2
二次扫描:BLKUP
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
4 #SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
先使用二级别索引定位,再根据表的主键、聚集索引、rowid等信息定位数据行。
全表扫描:CSCN
EXPLAIN SELECT * FROM T1;
1 #NSET2: [1, 10000, 156]
2 #PRJT2: [1, 10000, 156]; exp_num(5), is_atom(FALSE)
3 #CSCN2: [1, 10000, 156]; INDEX33556710(T1)
CSCN2是CLUSTER INDEX SCAN的缩写即通过聚集索引扫描全表,全表扫描是最简单的查询,如果没有选择谓词,或者没有索引可以利用,则系统一般只能做全表扫描。在一个高并发的系统中应尽量避免全表扫描。
索引扫描:SSEK CSEK SSCN
EXPLAIN SELECT * FROM T1 WHERE C1=10;
1 #NSET2: [0, 1, 156]
2 #PRJT2: [0, 1, 156]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 156]; IDX_C1_T1(T1)
#SSEK2: [0, 1, 156]; scan_type(ASC), IDX_C1_T1(T1), scan_range[10,10]
创建索引
CREATE CLUSTER INDEX IDX_C1_T2 ON T2(C1);
EXPLAIN SELECT * FROM T2 WHERE C1=10;
1 #NSET2: [0, 250, 156]
2 #PRJT2: [0, 250, 156]; exp_num(5), is_atom(FALSE)
#CSEK2: [0, 250, 156]; scan_type(ASC), IDX_C1_T2(T2), scan_range[10,10]
创建复合索引
CREATE INDEX IDX_C1_C2_T1 ON T1(C1,C2);
EXPLAIN SELECT C1,C2 FROM T1;
1 #NSET2: [1, 10000, 60]
2 #PRJT2: [1, 10000, 60]; exp_num(3), is_atom(FALSE)
3 #SSCN: [1, 10000, 60]; IDX_C1_C2_T1(T1)
SSEK2是二级索引扫描即先扫描索引,再通过主键、聚集索引、ROWID等信息去扫描表
CSEK2是聚集索引扫描只需要扫描索引,不需要扫描表
SSCN是索引全扫描,不需要扫描表
嵌套循环连接
NEST LOOP原理:两层嵌套循环结构,有驱动表和被驱动表之分。选定一张表作为驱动表,遍历驱动表中的每一行,根据连接条件去匹配第二张表中的行。驱动表的行数就是循环的次数,这个很大程度影响了执行效率。
需注意的问题:
- 选择小表作为驱动表。统计信息尽量准确,保证优化器选对驱动表。
- 大量的随机读。如果没有索引,随机读很致命,每次循环只能读一块,不能读多块。使用索引可以解决这个问题。
使用场景: - 驱动表有很好的过滤条件
- 表连接条件能使用索引
- 结果集比较小
过滤列和连接列都没有索引,也可以走nest loop,但是该计划很差。右边的计划代价很大。
select /*+use_nl(t1,t2)*/* from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';

优化:创建索引并搜集统计信息
create index idx_t1_c2 on t1(c2);
create index idx_t2_c1 on t2(c1);
dbms_stats.gather_index_stats(user,'IDX_T1_C2');
dbms_stats.gather_index_stats(user,'IDX_T2_C1');
哈希连接
HASH JOIN的特点
- 一般没索引或用不上索引时会使用该连接方式
- 选择小的表(或row source)做hash表
- 只适用等值连接中的情形
原理
使用较小的Row source 作为Hash table和Bitmap。而第二个row source被hashed,根据bitmap与第一个row source生成的hash table 相匹配,bitmap查找的速度极快。
Hash连接比较消耗内存,如果系统有很多这种连接时,需调整以下3个参数:
- HJ_BUF_GLOBAL_SIZE
- HJ_BUF_SIZE
- HJ_BLK_SIZE
连接列没有索引
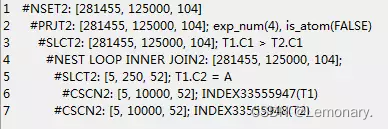
select * from t1 inner join t2 on t1.c1=t2.c1 where t1.c2='A';

不是等值连接,此时计划走nest loop
select * from t1 inner join t2 on t1.c1 > t2.c1 where t1.c2='A';
排序合并连接
MERGE SORT的特点
- 无驱动表之分,随机读很少
- 两个表都需要按照连接列排序,需要消耗大量的CPU和额外的内存
应用场景
通常情况下,merge sort join需要消耗大量的CPU和内存,效率都不会太高。如果存在相关索引可以消除sort,那么CBO可能会考虑该连接方式。
select /*+use_merge(t1 t2)*/ t1.c1,t2.c1 from t1 inner join t2 on t1.c1=t2.c1 where t2.c2='b';
创建如下索引,消除sort
create index idx_t1_c1c2 on t1(c1,c2);
create index idx_t2_c1 on t2(c1);

查询转换
什么是查询转换
查询转换是优化器自动做的,在生成执行计划之前,等价改写查询语句的形式,以便提升效率和产生更好的执行计划。它决定是否重写用户的查询,常见的转换有谓词传递、视图拆分、谓词推进、关联/非关联子查询改写等。
了解优化器查询转换的特性,会帮助我们更好的看懂执行计划,也会对我们优化sql起到指导的作用。优化器的查询转换有很多限制条件,我们可以根据类似的原理举一反三,进行手工的sql改写,从到得到更好的执行计划。
谓词传递
原理:根据A=B,B=C,可以推导出A=C
原始 sql
select * from t1 inner join t2
on t1.c2=t2.c2
where t1.c1=100 and t2.c1=t1.c1

CBO转换后,等价于下面的 sql
select * from t1 inner join t2
on t1.c2=t2.c2
where t1.c1=100 and t2.c1=t1.c1
and t2.c1=100 --谓词传递

视图拆分
视图定义
create or replace view v_t1
as select t1.c1+t2.c1 as c11,t2.c2,t1.c1 from t1,t2 where t1.c2=t2.c2;
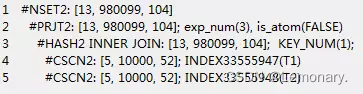
原始 sql
select a.c11,b.c2 from v_t1 a,t1 b
where a.c1=b.c1 and a.c1=100;
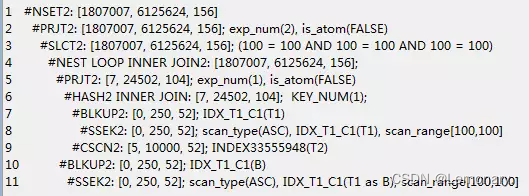
观察原始sql的执行计划,发现视图部分的子计划已经没有了。说明优化器进行等价改写,将视图的查询拆散了,和其他部分作为一个整体来生成计划。视图拆分有很多限制,如果视图查询中含有distinc、union、group by等操作,优化器就无法进行视图拆分。
谓词推进
原始sql,子查询x相当于一个内联视图
select * from (select c1,c2 from t1 where c2='C') x where c1=100;

观察执行计划,由于C2字段无索引,子查询X部分本应该走全表扫描,但是计划中却走了C1字段的索引。说明优化器对原始sql做了如下的等价改写,将条件c1=100推到子查询X中:
查询转换
select * from (select c1,c2 from t1 where c2='C' and c1=100) x;
非关联子查询的转换
原始 sql
select * from t1 where c1 in (select c1 from t2 ) and c2='A';

观察原始sql,T2的子查询是个非关联的子查询,完全可以把它生成一个独立的子计划。但是计划中T1和T2做了关联,说明优化器进行了如下的等价改写:
查询转换
select * from t1 where exists (select 1 from t2 where t1.c1=t2.c1) and c2='A';
相关INI参数:REFED_EXISTS_OPT_FLAG,影响 in 和 exists 子查询的转换。
外连接转换
原始 sql
select t1.c1,t2.c2 from t1 left join t2 on t1.c1=t2.c1 where t2.c1=100 and t1.c2='A';
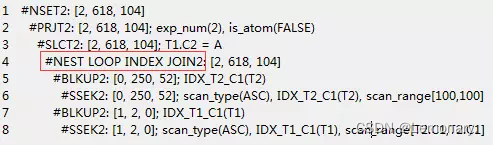
观察上面的计划发现,原始sql是外连接,计划中却变成了内连接。这是优化器根据sql语义判断,就是等价于下面的内连接:
select t1.c1,t2.c2 from t1 inner join t2 on t1.c1=t2.c1 where t2.c1=100 and t1.c2='A';
DM7索引与统计信息详解
统计信息
什么是统计信息?
统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息。比如,表的行数,块数,平均每行的大小,索引的高度、叶子节点数,索引字段的行数,不同值的大小等,都属于统计信息。
两种统计方式:
- 频率直方图:适用于取值范围比较少的列,例如有些字段的取值范围非常有限,比如人类的年龄,一般不可能超过120, 因此无论表中有多少记录,年龄字段的唯一值个数都不会超过120, 我们可以采样部分记录,统计出每个年龄(0-120)的记录数,可以使用120个(V, count)二元组作为元素的数组,来表示这个频率直方图。
- 等高直方图:频率直方图虽然精确,但是它只能处理取值范围较小的情况,如果字段的取值范围很大,那么就不可能为每一个值统计出它的出现次数,这个时候我们需要等高直方图。等高直方图是针对一个数据集合不同值 个数很多的情况,把数据集合划分为若干个记录数相同或相近的不同区间,并记录区间的不同值个数。每个区间的记录数比较接近,这就是所谓等高的含义。

构造测试环境
CREATE TABLE TEST_TJ(ID INT,AGE INT);
BEGIN FOR I IN 1..100000 LOOP
INSERT INTO TEST_TJ VALUES(MOD(I,9700),TRUNC(RAND * 120));
END LOOP;
COMMIT;
END;
创建系统包
SP_CREATE_SYSTEM_PACKAGES(1);
更新单列统计信息
DBMS_STATS.GATHER_TABLE_STATS(USER, 'TEST_TJ',null,100,false, 'FOR ALL COLUMNS SIZE AUTO'); --更新所有列
SP_COL_STAT_INIT_EX(USER,'TEST_TJ','ID',100); --更新单列
查看统计信息:频率直方图
DBMS_STATS.COLUMN_STATS_SHOW(USER, 'TEST_TJ','AGE');
- 类型:频率直方图
- ENDPOINT_VALUE样本值: 1
- ENDPOINT_HEIGHT 样本值的个数:819
SELECT COUNT(*) FROM TEST_TJ WHERE AGE=1; --819

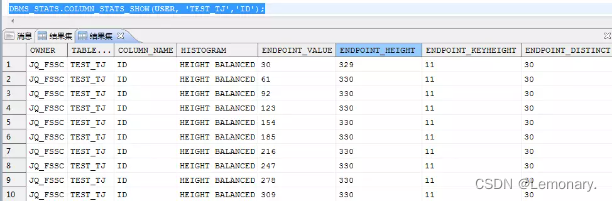
查看统计信息:等高直方图
DBMS_STATS.COLUMN_STATS_SHOW(USER, 'TEST_TJ','ID');
- 类型:等高直方图
- ENDPOINT_VALUE样本值: 30
- ENDPOINT_HEIGHT小于样本值大于前一个样本值的个数:329
- ENDPOINT_KEYGHT样本值的个数:11
- ENDPOINT_DISTINCT小于样本值大于前一个样本值之间不同样本的个数:30
SELECT COUNT(*) FROM TEST_TJ WHERE ID<30; --329
SELECT COUNT(*) FROM TEST_TJ WHERE ID=30; --11
SELECT COUNT(DISTINCT ID) FROM TEST_TJ WHERE ID<30; --30
统计信息对CBO影响非常重大,因此我们要及时更新统计信息。但是统计信息由于某些原因总存在一些缺陷, CBO也很难百分百估算正确。为更好理解CBO估算方式,我们必须要了解以下情形:
- 对于等高直方图,CBO会认为每个区间中的数据都是近似均匀分布的,实际上数据可能分布非常崎岖。
- 等高直方图区间越多,统计越精确,而实际上数量有限,最大为1000。
- 对于组合索引的多个列,统计信息只有每个列的独立分布情况,而无法知道列之间的关联分布。
下面用一个案例,来直观感受下统计信息本身的缺陷对优化器造成的负面影响。
案例
数据分布不均匀导致范围扫描时CBO估算不准确
数据准备
drop table t1;
--插入10万条,C1数据分布均匀
create table t1 as select level c1,level c2 from dual connect by level<=100000;
--插入2万条C1=100,使该值数量很大,造成C1分布不均匀
insert into t1 select 100,level from dual connect by level<=20000;
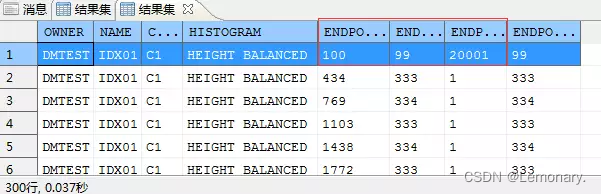
创建索引,查看统计信息
--给C1列创建索引
create index idx01 on t1(c1);
--搜集统计信息
dbms_stats.gather_index_stats(user,'IDX01');
--查看统计信息,100这个值有20001行
dbms_stats.index_stats_show(user,'IDX01');
--测试=值查询,估算正确
select * from t1 where c1=100;
执行计划
1 #NSET2: [13, 20001, 16]
2 #PRJT2: [13, 20001, 16]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [13, 20001, 16]; T1.C1 = 100
4 #CSCN2: [13, 120000, 16]; INDEX33555836(T1)
--测试范围查询
select * from t1 where c1 between 90 and 110;
此时估算行数错误,应该有20001行,不该走索引,计划不对
1 #NSET2: [0, 19, 16]
2 #PRJT2: [0, 19, 16]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [0, 19, 16]; IDX01(T1)
4 #SSEK2: [0, 19, 16]; scan_type(ASC), IDX01(T1), scan_range[90,110]
索引存储结构
了解索引的存储结构对于正确使用和优化索引有很大帮助。最常见的索引结构为Btree索引,下图是一个B树索引存储结构图。
B*树相关概念:
- 根节点
- 内节点
- 叶子节点
- 树高度h
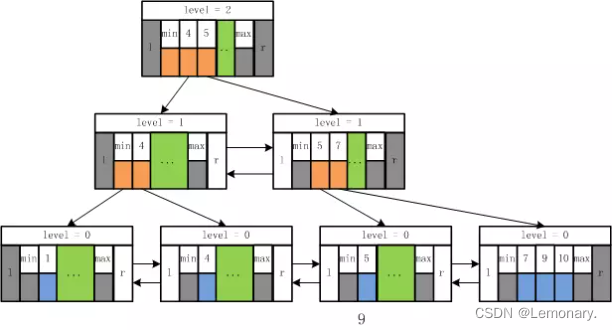
聚集索引:- 叶子节点存储的是数据块
非聚集索引:- 叶子节点存储的是主键值或聚集索引的值或rowid
从B树中访问每个叶子节点的成本都是h次IO,索引的访问效率只跟B树的高度有关系。
创建表 插入100万条数据
CREATE TABLE TEST_INDEX(ID INT,AGE INT);
BEGIN
FOR I IN 1..1000000 LOOP
INSERT INTO TEST_INDEX VALUES(MOD(I,9700),TRUNC(RAND * 120));
END LOOP;
COMMIT;
END;
创建索引
CREATE INDEX IDX_ID_TEST_INDEX ON TEST_INDEX(ID);
更新索引统计信息
SP_INDEX_STAT_INIT(USER,'IDX_ID_TEST_INDEX');
查看索引相关信息
SELECT B.NAME,A.T_TOTAL, --表总行数
A.BLEVEL+1 HEIGHT, --索引高度
A.N_LEAF_USED_PAGES, --叶子节点数
INDEX_USED_PAGES(B.ID)-
A.N_LEAF_USED_PAGES-1 BRANCH_PAGES –内节点数
FROM SYSSTATS A,SYSOBJECTS B
WHERE A.ID=B.ID
AND B.NAME IN('IDX_ID_TEST_INDEX');

创建索引的原则
在什么情况下使用B*树索引?
- 仅当要通过索引访问表中很少的一部分行(1%~20%)
索引用于访问表中的行(只占一个很小的百分比) - 如果要处理表中的多行,而且可以使用索引而不用表
索引用于回答一个查询:索引提供了足够的信息来回答整个查询,不需要去访问表
索引可以作为一个“较瘦”版本的表
原则1
根据索引查询只返回很少一部分行
创建表 插入10万条数据
CREATE TABLE TEST_INDEX(ID INT,AGE INT);
BEGIN
FOR I IN 1..100000 LOOP
INSERT INTO TEST_INDEX VALUES(MOD(I,9700),TRUNC(RAND * 120));
END LOOP;
COMMIT;
END;
创建索引
CREATE INDEX IDX_ID_TEST_INDEX ON TEST_INDEX(ID);
CREATE INDEX IDX_AGE_TEST_INDEX ON TEST_INDEX(AGE);
更新列统计信息
SP_COL_STAT_INIT_EX(USER,'TEST_INDEX','ID',100);
SP_COL_STAT_INIT_EX(USER,'TEST_INDEX','AGE',100);
返回少部分行 走索引
EXPLAIN SELECT * FROM TEST_INDEX WHERE ID=100;
1 #NSET2: [0, 11, 16]
2 #PRJT2: [0, 11, 16]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [0, 11, 16]; IDX_ID_TEST_INDEX(TEST_INDEX)
#SSEK2: [0, 11, 16]; scan_type(ASC), IDX_ID_TEST_INDEX(TEST_INDEX), scan_range[100,100]
返回大部分行 走全表扫描
EXPLAIN SELECT * FROM TEST_INDEX WHERE AGE>1 ;
1 #NSET2: [11, 98374, 16]
2 #PRJT2: [11, 98374, 16]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [11, 98374, 16]; TEST_INDEX.AGE > 1
4 #CSCN2: [11, 100000, 16]; INDEX33556678(TEST_INDEX)
原则2
索引作为一个较瘦版本的表
只需要扫描索引 不用扫描表
EXPLAIN SELECT TOP 10 * FROM TEST_INDEX ORDER BY AGE ;
1 #NSET2: [10, 10, 16]
2 #PRJT2: [10, 10, 16]; exp_num(3), is_atom(FALSE)
3 #TOPN2: [10, 10, 16]; top_num(10)
4 #BLKUP2: [10, 100000, 16]; IDX_AGE_TEST_INDEX(TEST_INDEX)
5 #SSCN: [10, 100000, 16]; IDX_AGE_TEST_INDEX(TEST_INDEX)
只需要扫描索引 不用扫描表
EXPLAIN SELECT COUNT(DISTINCT AGE) FROM TEST_INDEX;
1 #NSET2: [17, 1, 4]
2 #PRJT2: [17, 1, 4]; exp_num(1), is_atom(FALSE)
3 #AAGR2: [17, 1, 4]; grp_num(0), sfun_num(1)
4 #SSCN: [10, 100000, 4]; IDX_AGE_TEST_INDEX(TEST_INDEX)
组合索引列的顺序
- 最优先把等值匹配的列放最前面,范围匹配的放后面
- 其次把过滤性好的列放前面,过滤性差的放后面
- 查询时组合索引只能利用一个非等值字段
创建测试表
create table tab(c1 int,c2 char(1),c3 char(1),c4 int);
构造测试数据
insert into tab
select level c1,chr(mod(level,27)+65) c2,chr(mod(level,27)+65) c3,level c4
from dual
connect by level<=10000;
待优化语句如下:
SELECT * FROM TAB WHERE C1 BETWEEN 10 AND 20 AND C2 ='A' AND C3='B';
创建索引
CREATE INDEX IDX_C1_C2_C3_TAB ON TAB(C1,C2,C3);
CREATE INDEX IDX_C2_C3_C1_TAB ON TAB(C2,C3,C1);
查看执行计划
EXPLAIN SELECT * FROM TAB WHERE C1 BETWEEN 10 AND 20 AND C2 ='A' AND C3='B';
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C2_C3_C1_TAB(TAB)
#SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C2_C3_C1_TAB(TAB),scan_range[(A,B,10),(A,B,20)]
查看执行计划 可以看出这个索引只能利用C1列
EXPLAIN SELECT * FROM TAB INDEX IDX_C1_C2_C3_TAB TT WHERE C1 BETWEEN 10 AND 20 AND C2 ='A' AND C3='B';
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [0, 1, 112]; (TT.C2 = A AND TT.C3 = B)
4 #BLKUP2: [0, 25, 112]; IDX_C1_C2_C3_TAB(TT)
#SSEK2: [0, 25, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB(TAB as TT), scan_range[(10,min,min),(20,max,max))
关于不走索引的各种神话
案例1 条件列不是索引的首列
--创建表
CREATE TABLE TAB1(C1 INT,C2 CHAR(1),C3 CHAR(1),C4 INT);
--构造测试数据
INSERT INTO TAB1
SELECT LEVEL C1,CHR(MOD(LEVEL,27)+65) C2,CHR(MOD(LEVEL,27)+65) C3,LEVEL C4
FROM DUAL
CONNECT BY LEVEL<=10000;
COMMIT;
--创建索引
CREATE INDEX IDX_C1_C2 ON TAB1(C1,C2);
查看执行计划
EXPLAIN SELECT * FROM TAB1 WHERE C2='A';
1 #NSET2: [1, 250, 112]
2 #PRJT2: [1, 250, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [1, 250, 112]; TAB1.C2 = A
4 #CSCN2: [1, 10000, 112]; INDEX33556684(TAB1)
案例2 条件列上有函数或计算
正常情况
EXPLAIN SELECT * FROM TAB1 WHERE C1 = 123;
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
#SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(123,min,min),(123,max,max))
条件列上有函数
EXPLAIN SELECT * FROM TAB1 WHERE abs(C1) =123;
1 #NSET2: [137, 25000, 112]
2 #PRJT2: [137, 25000, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [137, 25000, 112]; exp11 = var1
#CSCN2: [137, 1000000, 112]; INDEX33556691(TAB1)
条件列上有计算
EXPLAIN SELECT * FROM TAB1 WHERE C1-1 = 123;
1 #NSET2: [137, 25000, 112]
2 #PRJT2: [137, 25000, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [137, 25000, 112]; TAB1.C1-1 = 123
#CSCN2: [137, 1000000, 112]; INDEX33556691(TAB1)
可以将计算过程挪到等号右边
EXPLAIN SELECT * FROM TAB1 WHERE C1 = 123+1
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
4 #SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(123+1,min,min),(123+1,max,max))
案例3 存在隐式类型转换
对条件列C1做了隐式的类型转换,将int类型转换为char类型
EXPLAIN SELECT * FROM TAB1 WHERE C1= '1234567890'
1 #NSET2: [137, 25000, 112]
2 #PRJT2: [137, 25000, 112]; exp_num(5), is_atom(FALSE)
3 #SLCT2: [137, 25000, 112]; exp_cast(TAB1.C1) = var1
#CSCN2: [137, 1000000, 112]; INDEX33556691(TAB1)
后面的常量小于10位,优化器对常量做了类型转换,这时可以走索引
EXPLAIN SELECT * FROM TAB1 WHERE C1= '123456789'
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
#SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(exp_cast(123456789),min,min),(exp_cast(123456789),max,max))
写SQL的时候数据类型最好匹配,不要让优化器来做这种隐式的类型转换
EXPLAIN SELECT * FROM TAB1 WHERE C1=1234567890
1 #NSET2: [0, 1, 112]
2 #PRJT2: [0, 1, 112]; exp_num(5), is_atom(FALSE)
3 #BLKUP2: [0, 1, 112]; IDX_C1_C2_C3_TAB1(TAB1)
4 #SSEK2: [0, 1, 112]; scan_type(ASC), IDX_C1_C2_C3_TAB1(TAB1), scan_range[(1234567890,min,min),(1234567890,max,max))
案例4 如果走索引会更慢
准备数据
--创建测试表
CREATE TABLE TX(ID INT, NAME VARCHAR(100));
--插入数据
BEGIN
FOR X IN 1 .. 100000 LOOP
INSERT INTO TX VALUES(X, 'HELLO');
END LOOP;
COMMIT;
END;
--创建索引 更新统计信息
CREATE INDEX TXL01 ON TX(ID);
SP_INDEX_STAT_INIT(USER,'TXL01');
返回记录较多 不走索引
EXPLAIN SELECT * FROM TX WHERE ID <50000;
1 #NSET2: [12, 49998, 60]
2 #PRJT2: [12, 49998, 60]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [12, 49998, 60]; TX.ID < 50000
#CSCN2: [12, 100000, 60]; INDEX33556697(TX)
返回记录较少 走索引
EXPLAIN SELECT * FROM TX WHERE ID < 500;
1 #NSET2: [8, 498, 60]
2 #PRJT2: [8, 498, 60]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [8, 498, 60]; TXL01(TX)
4 #SSEK2: [8, 498, 60]; scan_type(ASC), TXL01(TX), scan_range(null2,500)
案例5 没有更新统计信息
准备数据
--创建测试表
CREATE TABLE TY(ID INT, NAME VARCHAR(100));
--插入数据
BEGIN
FOR X IN 1 .. 100000 LOOP
INSERT INTO TY VALUES(X, 'HELLO');
END LOOP;
COMMIT;
END;
--创建索引
CREATE INDEX TYL01 ON TY(ID);
未更新统计信息
EXPLAIN SELECT * FROM TY WHERE ID < 500;
1 #NSET2: [12, 5000, 60]
2 #PRJT2: [12, 5000, 60]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [12, 5000, 60]; TY.ID < 500
#CSCN2: [12, 100000, 60]; INDEX33556699(TY)
更新统计信息
SP_INDEX_STAT_INIT(USER,'TYL01');
再查看执行计划
EXPLAIN SELECT * FROM TY WHERE ID <500;
1 #NSET2: [8, 498, 60]
2 #PRJT2: [8, 498, 60]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [8, 498, 60]; TYL01(TY)
4 #SSEK2: [8, 498, 60]; scan_type(ASC), TYL01(TY), scan_range(null2,500)
索引对DML语句的影响
天下没有免费的午餐,索引能提高查询性能,也能拖慢DML的效率。
下面在单机做了一个测试,在一个千万行的表上分别添加0~10个索引,记录更新一万行记录的时间,如下表:
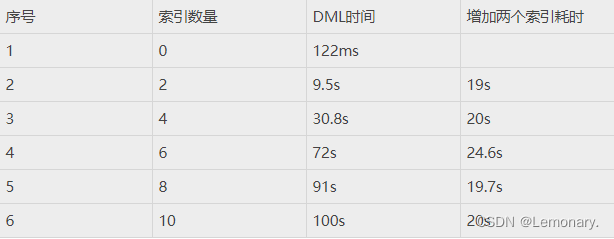
上面具体的数字没有意义,因为不同的硬件环境和参数,数据会不一样。但是通过比较能发现,索引越多,表上DML操作的速度越慢。所以使用索引一定要注意质量,可有可无的索引必须要删掉。另外,大批量更新数据时,允许的话可以先删除索引,更新完毕后再重建,这样效率会高一些。














 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









