






1.SQL语句的执行过程
在客户端执行SELECT语句时,
1、客户端会把这条SQL语句发送给服务器端,由服务器端进程来处理该条语句。
即,数据库客户端是不会做任何其他操作。
2、服务器进程对该语句进行解析,主要通过以下步骤完成
查询库缓存区
服务器进程接收到SQL语句后,会先在数据库的高速缓存中查找是否存在相同语句的执行计划,若存在,则直接执行该SQL语句。
采用高速数据缓存可提高SQL语句的查询效率。优点:
① 从内存中读取数据要比从硬盘的数据文件中读取数据效率更高。
② 解析语句也需要时间。
语句合法性检查
在高速缓存中找不到对应的SQL语句时,服务器进程会检查该条语句的合法性。即语法上的检查。
语言含义检查
若SQL语句符合语法上的定义,服务器进程则会进一步对该语句中的字段、表等内容进行检查。即查看表、字段等是否在数据库中存在。
获得对象解析锁
当语法、语义均没问题后,系统会对需要查询的对象加锁。主要是为了保障数据的一致性,防止在查询过程中其他用户对该对象的结构做出修改。
数据访问权限的核对
以上操作均无问题后,服务器会检查连接的用户是否有权限访问该数据。
确定最佳执行计划
以上操作均无问题后,服务器进程会根据一定的规则,对该条语句进行优化。该优化是有限的。一般在应用软件开发过程中,需要对数据库的SQL语言进行优化,这个优化的作用远大于服务器进程的自我优化。
当服务器进程的优化器确定该条查询语句的最佳执行计划后,会将该条SQL语句和执行计划保存在高速缓存(Library Cache)中。
3、语句执行
SQL语句的执行分两种情况:
一是:所需的数据已在数据缓冲区,服务器进程直接将数据传递给客户端。
二是:所需数据不在缓冲区中,服务器进程则将从数据文件中查询相关数据,并将其放入数据缓冲区。
4、提取数据
SQL语句执行完成后,查询到的数据还是在服务器进程中,没被传送到客户端的用户进程中。因此,在服务器进程中,有一段专门负责数据提取的代码。作用就是将查询到的数据结果返回给客户端进程,从而完成整个查询操作。
一条SQL语句的具体执行过程,如下图所示:
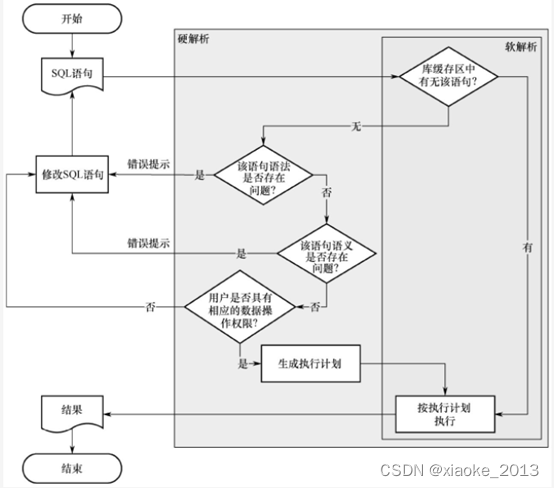
在DM8内部,当将一条语句提交到数据库中后,SQL引擎分三个步骤对其进行处理和执行:解析(parse)、执行(execute)和获取(fetch)。分别由SQL引擎的不同组件完成。
SQL引擎结构如下图:
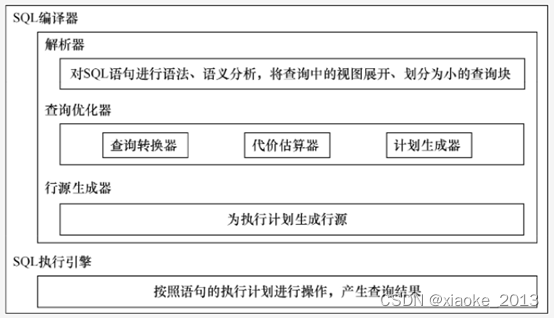
1.1 SQL编译器(SQL Compiler)
将语句编译到一个共享游标中。
由解析器(parser)、查询优化器(query optimizer)、行源生成器(row source generator)组成
1.1.1 解析器
用于分析SQL语句的语法、语义,并将查询中的视图展开、划分为小的查询块。
1.1.2 查询优化器
由查询转换器(Query Transform)、代价估算器(Cost Estimator)和计划生成器(Plan Generator)组成。
1.1.2.1 查询转换器:
查询转换指把经过语法、语义分析的查询块之间的连接类型、嵌套关系进行调整,生成一个更好地查询计划。
常用的查询转换技术包括过滤条件的下放、相关子查询的去相关性。
过滤条件下放:在连接查询中,把部分表的过滤条件下移,在连接之前先过滤,可以减少连接操作的数据量,提升语句性能。
相关子查询的去相关性:采用半连接的方式执行与子查询相关的外表和内表,放弃默认采取的嵌套连接方式,对性能有较大的提升。
查询转换器决定是否重写用户的查询(包括视图合并、子查询反嵌套),以生成更好地查询计划。
1.1.2.2 代价估算器:
使用统计数据来估算操作的选择率(Selectivity),返回数据集的势(Cardinality)和代价,并最终估算出整个执行计划的代价。
选择率:指满足条件的记录数占总记录数的百分比。选择率与查询谓词相关,与谓词的连接相关。一个谓词可以看作一个过滤器,过滤掉结果集中不满足条件的记录。
如果没有统计信息,优化器会依据过滤条件的类型来设置对应的选择率。
如果有统计信息,可以使用统计信息来估算选择率。例如,对于等值谓词,如果name列有N个不同值,选择率是1/N。
基数:指整个行集的行数。
代价:表示资源的使用情况。查询优化器使用磁盘I/O、CPU占用和内存使用情况作为代价计算的依据。
访问路径决定了从一个基表中获取数据所需要的代价。
连接代价:指访问两个连接的结果集代价与连接操作的代价之和。
1.1.2.3 计划生成器:
考虑可能的访问路径(Access Path)、关联方法和关联顺序,生成不同的执行计划,让查询优化器从这些计划中选择出一个代价最小的计划。
数据访问路径,指从数据库中检索数据的方法。例如:全表扫描、索引扫描(聚簇索引扫描和二级索引扫描)。
查询优化器通过分析可用的执行方式和查询所涉及的对象统计信息来生成最优的执行计划。如果存在HINT优化提示,优化器还需考虑优化提示的因素。
查询优化器的处理过程包含是三个步骤:
1、 优化器生成所有可能的执行计划集合
2、 优化器基于字典信息的数据分布统计值、执行语句涉及的表、索引和分区的存储特点来估算每个执行计划的代价。
代价:指SQL语句使用某种执行方式所消耗的系统资源的估算值。其中,系统资源消耗包括I/O、CPU使用情况、内存消耗等。
3、 优化器选择代价最小的执行方式作为该条语句的最终执行计划。
影响优化器选择访问路径的因素:语句中的提示(HINT)和统计信息。
用户可在执行语句中使用HINT来指定访问路径
统计信息会根据表中的数据分布情况决定采用哪个访问路径会产生最小的代价。
注意:上述查询优化器实际上指的是基于代价的优化器(Cost Based Optimizer,CBO),CBO也是当前采用的所有优化技术和调优技术的核心基础。
1.1.3 行源生成器
从查询优化器接收到优化的执行计划后,为该计划生成行源(row source)。
行源是一个可被迭代控制的结构体,能以迭代方式处理并生成一组数据行。
1.2 SQL执行引擎(SQL Execution Engine)
依照语句的执行计划进行操作,产生查询结果。
在每个操作中,SQL执行引擎会以迭代的方式执行行源,生成数据行。
2.执行计划
利用执行计划定位高负载或不合理的SQL语句等影响性能的问题,通过创建索引、修改SQL语句等操作来提高SQL语句的执行效率。
能够看懂执行计划是SQL语句优化的先决条件。
执行计划指对SQL语句在数据库中的执行过程或访问路径的描述。
2.1 执行计划查看
在SQL命令中,使用EXPLAIN语句可打印出语句的执行计划。


该计划的大致执行流程:
(1) CSCN2:扫描T2表的聚集索引,数据传递给父节点索引连接。
(2) NEST LOOP INDEX JOIN2:当左子节点有数据返回时,取右侧数据。
(3) SSEK2:利用T2表当前的D1值作为二级索引IDX_T1_C1定位查找的键,返回结果给父节点。
(4) NEST LOOP INDEX JOIN2:若右子节点有数据,则将结果传递给父节点PRJT2,否则继续去左子节点的下一条记录。
(5) PRJT2:计算表达式C1+1和D2的值。
(6) NSET2:输出最后结果
(7) 重复过程(1)~(4)直至左侧的CSCN2数据全部取完。
查看v$sql_node_name动态视图可查看执行计划的常用操作符。
如AAGR2表示简单聚集,CSCN2表示聚集索引扫描。
3.统计信息
统计信息主要是描述DM8中I/O读写速度等系统处理能力,以及表、索引等对象的大小、规模和数据分布状况的一类信息。
数据库系统收集相关统计信息的过程也叫动态采样分析。
在代价估算中,优化器根据系统处理能力、对象的大小以及需要读取的数据量等信息,估算语句从相关对象中读取所需数据需要花费的代价。这些信息主要来源于存储在系统中的统计信息。
统计分析分两类:系统统计信息和对象统计信息
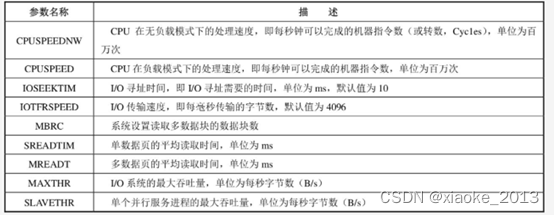
3.1 系统统计信息(System Statistics)
主要描述与系统硬件相关的某些特性,包括CPU转速、读取单数据页的I/O时间、读取多数据页的I/O时间,以及读取多数据页时平均每次读取的数据页的数量等。
系统处理能力是影响执行计划中操作代价的重要因素。
可使用DBMS_STAT中存储过程(GATHER_SYSTEM_STATS)来收集相关信息。
系统统计信息
3.2 对象统计信息
在估算对象的访问代价时,对象统计信息是优化器的重要参考数据。
对象统计信息又分为3类:表统计信息、索引统计信息和字段统计信息。
若表存在分区时,还包括表分区统计信息及子分区统计信息。
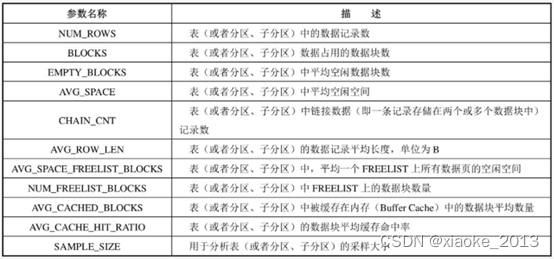
表统计信息
表统计信息可通过视图DBA/ALL/USER_TABLES查询,具体内容如下表
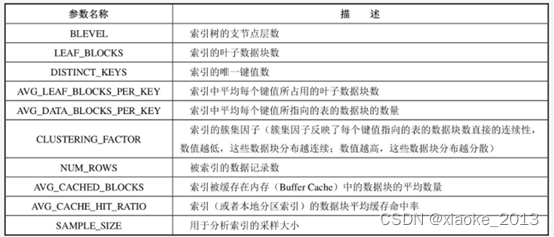
索引统计信息
索引统计信息可通过视图DBA/ALL/USER_INDEXES查询,具体内容如下表
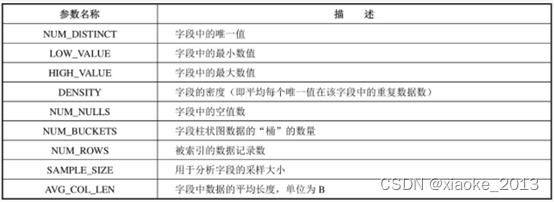
字段统计信息
字段统计信息可通过视图DBA/ALL/USER_TAB_COLS查询,具体内容如下表
统计信息会直接影响优化器选择那可执行计划,对于SQL查询语句中的单表查询和多表连接的执行计划,其相关的统计信息决定了如何选择执行计划。
3.3 统计信息的查看与更新
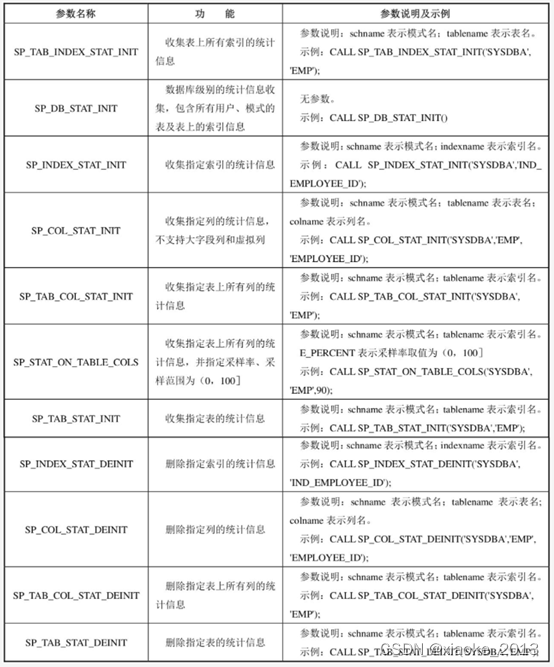
统计信息的收集和维护可通过DBMS_STATS包或SP_INDEX_STAT_INIT、SP_TAB_STAT_INIT等系统函数来实现。
可通过DESC DBMS_STATS查看DBMS_STATS包的相关描述信息。
SQL> DESC DBMS_STATS;
示例:
收集表的统计信息
SQL> call dbms_stats.gather_table_stats(‘user_name’,’table_name’);
INDEX_STATS_SHOW函数用于查看索引的统计信息。
SQL> call dbms_stats.index_stats_show(‘user_name’,’index_name’);
SP_*函数信息
4.SQL优化的基本步骤
确定优化目标
确定高负载的SQL语句
在DM8中,在搭建监控开关的前提下(ENABLE_MONITOR=1,MONITOR_TIME=1)。
查看v
l
o
n
g
e
x
e
c
s
q
l
或
v
long_exec_sql或v
longexecsql或vsystem_long_exec_sqls来确定高负载的SQL。
v
l
o
n
g
e
x
e
c
s
q
l
:显示执行时间较长的
1000
条
S
Q
L
语句。
v
long_exec_sql:显示执行时间较长的1000条SQL语句。 v
longexecsql:显示执行时间较长的1000条SQL语句。vsystem_long_exec_sqls:显示自服务器启动以来执行时间最长的20条SQL语句。
配置索引信息
使用查询优化向导工具,输入需要进行调整的SQL语句,经过分析后,工具将给出推荐创建或修改索引的提示。用户按需创建和修改相应索引即可。
5.SQL优化的基本方法
利用绑定变量提升性能
实验表明,数据量越大,查询次数越多,执行查询时绑定变量的优势越明显。
开发有效的SQL语句
避免使用OR子句
避免使用开头和结尾都为通配符的正则表达式
灵活使用伪表(SYSDUAL)
避免直接使用SELECT * FROM ……
避免使用功能相似的重复索引
使用COUNT()统计结果行数: count()统计包含NULL值,count(列名)不包含NULL值
使用EXPLAIN查看执行计划
UNION和UNION ALL的选择:UNION会过滤重复值,UNION ALL不会
优化GROUP BY … HAVING
使用优化器提示(HINT)
6.使用优化器提示(HINT)
HINT使优化器根据用户的需要生成指定的执行计划。但如果优化器无法生成相应的执行计划,那么该HINT将会被忽略。
HINT的常见格式如下:

注意:如果HINT的语法书写错误或指定的值不正确,DM8不会报错,而是直接忽略HINT继续执行。
可通过动态视图v$hint_ini_info查看DM8支持的HINT。
HINT参数分为两类:“OPT”和“EXEC”
OPT 表示分析阶段使用的参数
EXEC 表示运行阶段使用的参数,该阶段使用的参数对于视图无效。
索引提示
使用索引
DM8提供两种语法格式对表查询时使用指定的索引进行数据检索。
第一种
SQL> select * from table_name INDEX index_name where …… ;
第二种
SQL> select /+INDEX(table_name,index_name)/ * from table_name where …… ;
不使用索引
SQL> select /+NO_INDEX(table_name,index_name)/ * from table_name where …… ;
可以指定多个索引,一个语句中最多指定8个索引。
连接方式提示
USE_HASH函数:强制多个表之间使用指定顺序的哈希连接。

NO_USE_HASH函数

USE_NL函数:强制多个表之间使用嵌套循环连接。

NO_USE_NL函数

USE_NL_WITH_INDEX函数:当连接情况为左表+右表索引时,强制在两个表间使用索引连接。
NO_USE_NL_WITH_INDEX函数
USE_MERGE函数:强制在两个表间使用归并连接。归并连接所用的两个列都必须是索引列。
NO_USE_MERGE函数
SEMI_GEN_CROSS函数:优先采用半连接转换为等价的内连接,仅OPTIMIZER_MODE=1有效。
NO_SEMI_GEN_CROSS函数
USE_CVT_VAR函数:优先采用变量改写方式实现连接,适合驱动表数据量少而另一侧计划较复杂的常见,仅OPTIMIZER_MODE=1有效。
NO_USE_CVT_VAR函数
ENHANCED_MERGE_JOIN函数
连接顺序提示
如果期望表的连接顺序是T1/T2/T3,则在查询语句中加入如下提示:

统计信息提示

统计信息提示只针对基表设置,对视图和派生表等对象设置无效。
若表对象存在别名,则必须使用别名
行数只能使用整数,或整数K(千)、整数M(百万)、整数G(十亿)。
参考书籍《达梦数据库性能优化》
达梦社区地址:https://eco.dameng.com














 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









