







【背景】
由于本人在看豆瓣找房子的过程中经常看到一些【已转租】的帖子,一旦这样的帖子数量增多,将很大程度上影响到我们看帖的兴趣和找房的效率,所以希望贴主把无效的帖子删除,以维护豆瓣小组的良好环境。
【删贴方法】
本人研究了一下,删帖有两种方法:
1、找管理员(这个方法自行研究)
2、自己全部删除评论,然后帖子下面会出现“删除”按钮(下面详细讲讲如何快速删除大量评论)
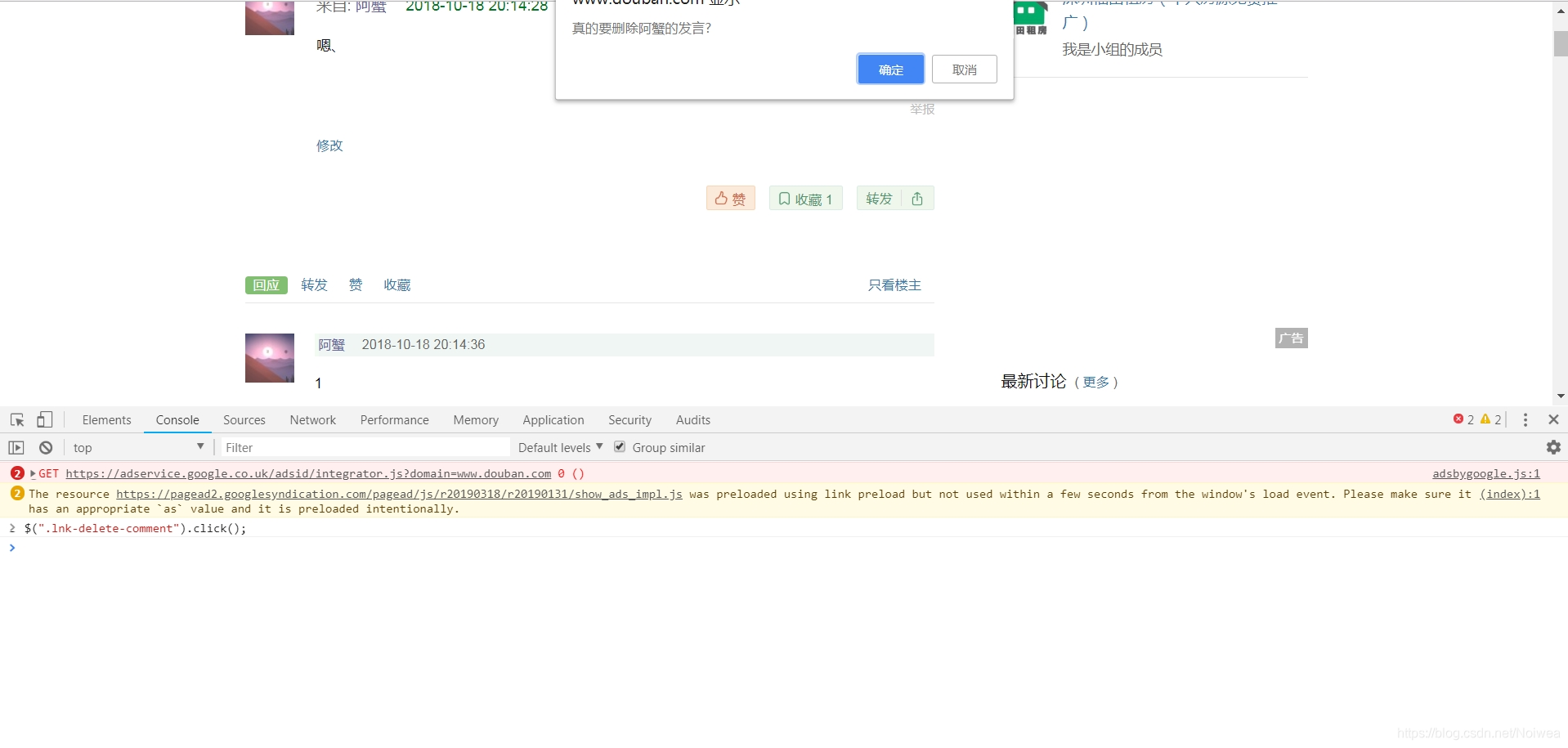
使用网页版Chrome浏览器打开要删除的帖子,键盘点击“F12”,找到“Console”窗口,在输入框中输入一段前端代码:
$(".lnk-delete-comment").click();
回车,会出现弹窗,然后一直按回车确认。如果有跳转页面就选择一个删除理由,回来之后继续上述操作。直到所有评论被删除。
(下面上图)

















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









