






最近发现一个免费AI工具,只需要上传一段30s左右的音频,就能完美地复制声音。

想象一下,只需短短30秒,你的声音就能被精确捕捉并复刻,无论是甜美的嗓音、深沉的磁性,还是独特的口音,都能被这个工具完美复制。
我尝试在网上找了一段李云龙的声音,用来合成一个新的音频模型,效果很不错!(生成的音频放在下面了)
简单介绍一下怎么做:
构建声音,支持上传音频或者录制音频,可以上传多个,可以选择私有模式
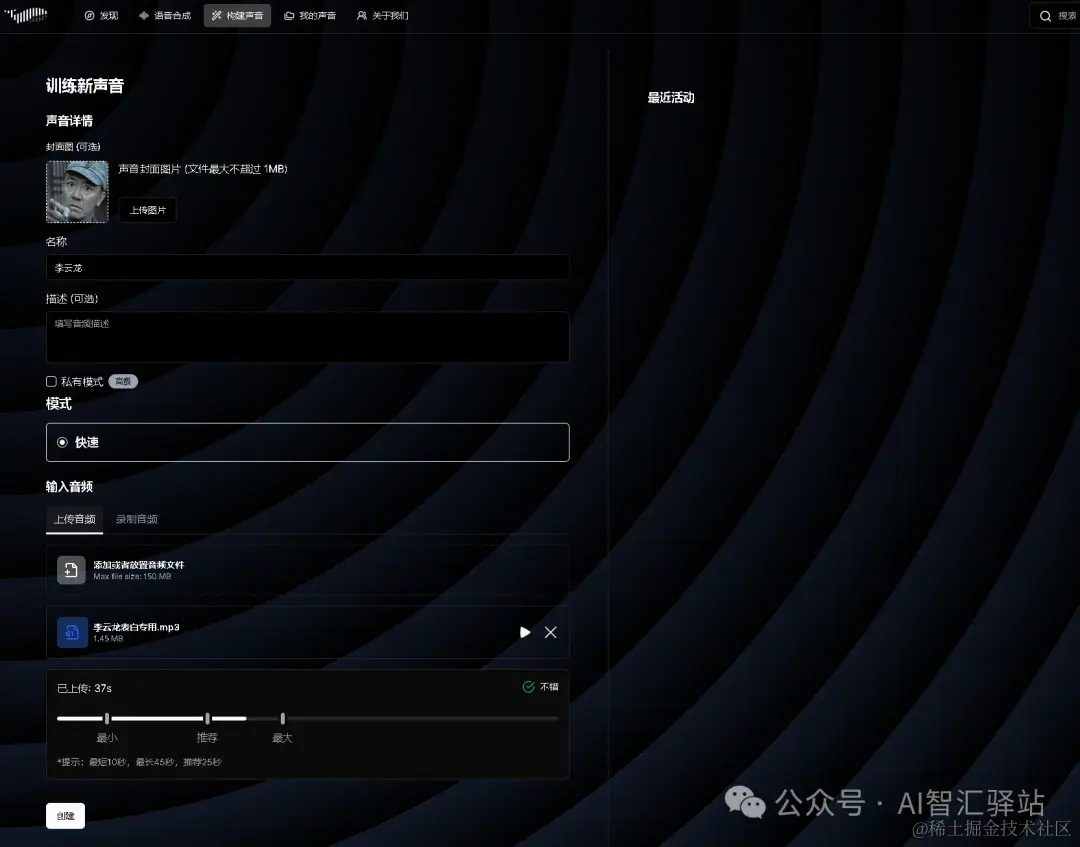
几秒就构建完成,然后就可以直接用

使用刚才构建好的声音,读取设定的文本,生成的音频在右侧显示
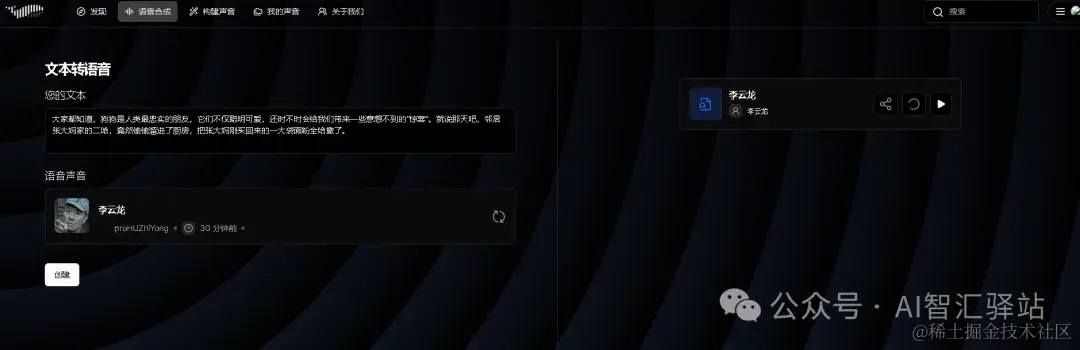
当然你也可以选择其他公开的声音

我这里生成了3个音频:
生成的音频:
总体效果还是挺好的,不过也能听出来,有些语气表达的并不是很好,当然这也是所有音频大模型的通病。
需要注意的是语音合成的文本输入有限制,大概是100个字,这样生成的语音就也会被限制在20s左右。
如果要读取长文本的可以考虑多次生成,再找其他工具整合起来。
感兴趣的可以去试试~
工具地址:
更详细的内容可以看这里:
如果你觉得这篇文章有用,记得点赞收藏关注哟
之前还介绍了一款适合画治愈系插图的AI工具,像下面这些图片都是用这款工具绘制的。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









