






今天在群里看到有人分享清华大学的《DeepSeek:从入门到精通》Pdf,我觉得很多人可能都需要这个,所以今天就分享一下,如果对你有帮助最好。

手册放在这里了,需要手册的伙伴可以自取。 链接:https://pan.quark.cn/s/468bee0cbf6e
《DeepSeek:从入门到精通》手册总共104页,5万字左右。
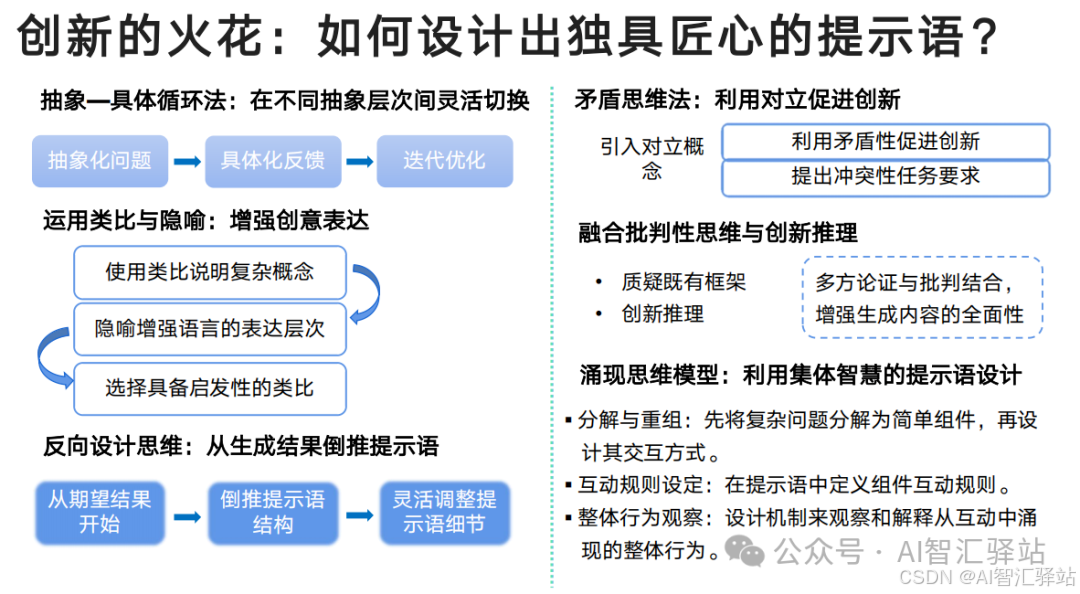
部分讲解内容: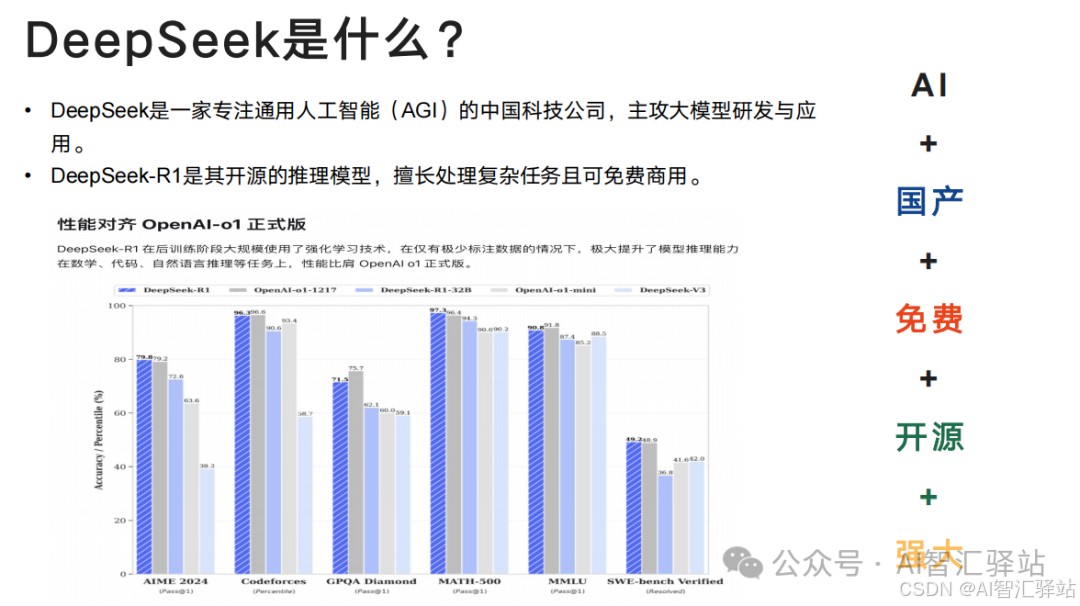
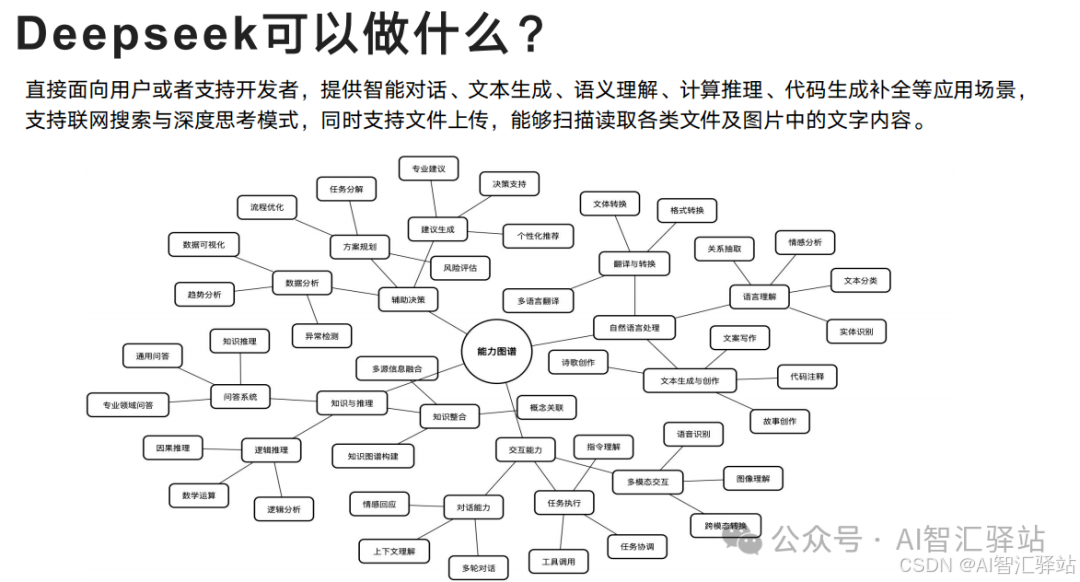
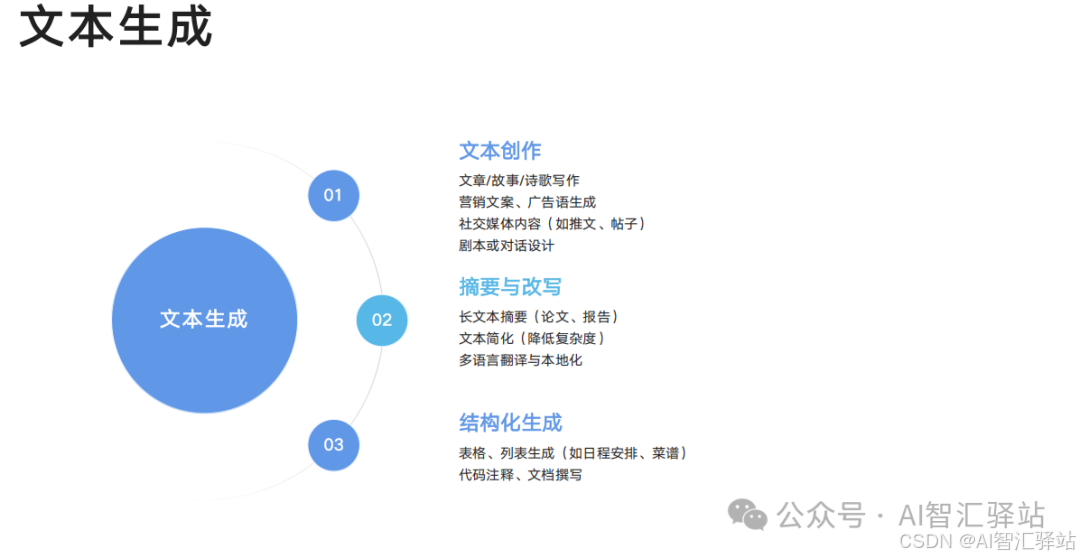



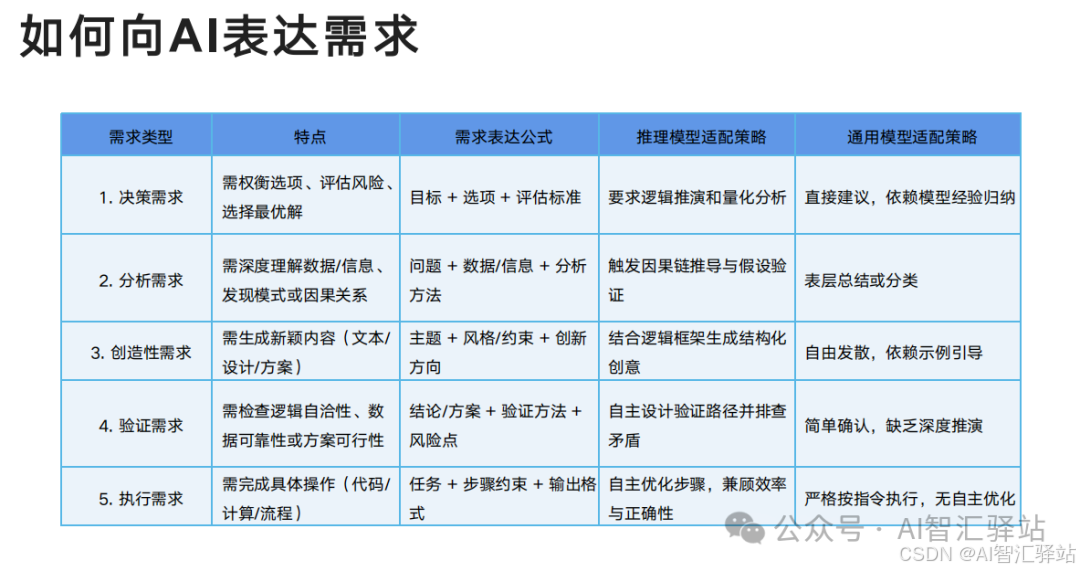


以上就是今天的分享了,如果你觉得我的分享对你有帮助,欢迎点赞、关注和分享**,鼓励我继续创作。**
往期相关文章推荐
最近我将2024年一些实用的AI工具都整理出来了,包含AI视频、AI绘画、AI音频、办公提效等等方向,总共80+AI工具,可以在下方链接查看。


















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









