










一、数组(核心)
(一)作用
一个对象,用来存储一些值,用数字作为索引操作对象
(二)常用方法
引用数组对象
语法:数组 [ 索引值 ]
注:读取索引不存在,则返回undefined
获取数组长度
使用length属性获取数组长度
语法:数组 . length
常用数组方法
. length()
修改数组长度
length大于原长,多余部分空出来;若length小于原长,多出部分被删除
. push()
向数组的末尾添加一或多个元素,并返回数组长度
参数:要添加的元素
. unshift()
向数组头部添加一或多个元素,并返回数组长度
参数:要添加的元素
. pop()
删除数组的最后一个元素,并返回删除元素的值
. shift()
删除数组的第一个元素,并返回删除元素的值
. slice()
从数组中提取指定元素,并封装到一个新数组并返回
参数:
- 参数1:开始提取索引值(必写)
- 参数2:结束提取索引值(必写)
注:若索引值为负数,则从后往前计算
. splice()
可以删除、修改、添加数组中指定元素
参数:
- 参数1:开始删除索引值(必写)
- 参数2:要删除的数量(必写)
- 参数3及后续参数:可传递新元素,自动插入在开始删除索引值前面
. concat()
连接两个或多个数组,并返回新数组,不影响原数组
. join()
将数组转化成一个字符串,并返回字符串
若有参数,则以参数连接数组各个元素组成字符串
. toString()
将数组转换为字符串,并返回字符串
. toLocaleString()
将数组转换为本地字符串
. reverse()
反转数组,影响原数组
. sort()
给数组排序,按照Unicode编码排序,影响原数组
若需升序排序,可在sort()中添加一回调函数,若返回一大于0的数,则元素交换,若等于0,元素位置不变,若小于0,则元素交换位置,即:需升序,返回a-b,需降序,返回b-a
. every()
检测数组中是否所用元素都满足条件,若是,则返回true,反之返回false
参数:所需满足的回调函数
. some()
若数组中有一元素满足条件,则返true,反之返回false
参数:所需满足的回调函数
. fill()
填充数组
参数:
- 参数1:填充元素
- 参数2:开始索引位置值
- 参数3:结束索引 位置值
. filter()
返回数组只能够满足回调函数的元素、
. find()
返回数组中符合条件的第一个元素
, findIndex()
返回数组中符合条件的第一个元素的索引值
. forEach()
遍历数组,对数组每一元素使用回调函数
. includes()
判断数组中是否含有指定的值,若用返回true,反之返回false
. indexOf()
返回数组中指定元素的位置,若没有则返回-1
. lastIndexOf()
返回数组中指定元素最后一次出现的位置,从后往前找
. copyWithin()
从数组指定位置复制元素到指定位置
参数:
- 参数1:复制的元素
- 参数2:开始位置
- 参数3:结束位置
. entries()
返回数组的迭代对象
. keys()
从数组中创建一个包含数组键的可迭代对象
. form()
将伪数组转换成真数组
isArray()
判断对象是否为数组,若是返回true,反之返回false
二、栈
(一)特点
先进后出,后进先出
只允许在一端进行操作(栈顶),另一端为栈尾
向栈中插入新元素称为进栈、入栈或压栈,将新元素放在栈顶元素的上面,使他称为新的栈顶元素
在一个栈中删除一个元素为退栈、出栈
(二)栈的实现
(基于数组实现)
function Stack(){
this.items=[];
}(三)常见操作
push(element):栈顶位置添加新元素
pop():移除栈顶元素,并返回被移除的元素
peek():返回栈顶元素(不会移除)
isEmpty():判断栈是否为空,为空返回true,否则返回false
size():返回去栈内元素个数//元素入栈
Stack.prototype.push=function(element){
this.items.push(element);
};
//移除栈顶元素
Stack.prototype.pop=function(){
return this.items.pop();
};
//查看栈顶元素
Stack.prototype.peek=function(){
return this.items[length-1];
};
//判断栈是否为空
Stack.prototype.isEmpty(){
return this.items.length==0;
}
//返回栈元素个数
Stack.prototype.size=function(){
return this.items.length;
}三、队列
(一)特点
先进先出
允许在一端添加元素,在另一端删除元素
(二)队列的实现
(基于数组实现)
function Quque(){
this.items=[];
}(三)常见操作
enquque(element):向队列尾部添加一或多个元素
dequque():删除队列第一个元素,并返回被删除的元素
front():返回队列的第一个元素(队列不做任何修改)
isEmpty():判断队列是否为空,为空则返回true,反之返回false
size():返回队列长度//向队列尾部添加元素
Quque.prototype.enquque=function(element){
this.items.push(element);
}
//删除
Quque.prototype.dequque=function(){
return this.items.shift();
}
//查看第一个元素
Quque.prototype.front=function(){
return this.items[this.items.length-1];
}
//判断队列是否为空
Quque.prototype.isEmpty=function(){
return this.items.length==0;
}
//返回队列长度
Quque.prototype.size=function(){
return this.items.length;
}(四)优先级队列
(一)特点
普通队列在插入元素后放在队列后端,并且处理完前面的数据才会处理后面的数据,但是优先级队列会在插入元素的时候考虑数据的优先级,和其他数据进行比较,了比较完成后会得出这个元素在队列中的正确位置
(二)实现
//封装优先级队列
function PriorityQuque(){
var items;
//封装一个构造函数,用于保存元素和元素的优先级
function QuqueElement(element,priority){
this.element=element;
this.priority=priority;
}
}//插入方法
this.enquque=function (element,priority){
//根据传入元素,创建新的QuqueElement
const ququeElement=new QuqueElement(element,priority);
//获取传入元素的正确位置
if(this.isEmpty()){
items.push(ququeElement);
}else{
const added=false;
for(var i=0;i<items.length;i++){
//数字越小,优先级越高
if(ququeElement.priority<items[i].priority){
items.splice(i,0,ququeElement);
added=true;
break;
}
}
//遍历所有的元素,优先级都大于插入的元素时,插在队列的最后面
if(!added){
items.push(ququeElement);
}
}
}五、链表
(一)单向链表
(一)作用
用于存储一系列元素
(二)优点
链表的元素在内存总不必是连续的空间
链表每个元素由一个存储元素本身的节点和一个指向下一个元素的引用
(三)与数组相比的优缺点
优点
- 内存空间不是必须连续的,可实现灵活的内存动态管理
- 链表创建时不用确定大小,而且大小可以无限延时下去
- 链表在插入和删除时,时间复杂度可以达到O(1),效率较高
缺点
- 访问任意一个位置时,都要重头开始访问(无法跳过第一个元素)
- 无法通过下标来访问元素
(四)封装
//封装链表类
function LinkedList(){
//内部类:节点类
function Node(data){
this.data=data;
this.next=null;
}
//属性
this.head=null;
this.length=0;//节点数
}(五)常见操作
append(element):向链表尾部添加新元素
insert(position,element):向链表指定位置添加元素
get(position):获取对应位置上的元素
indexOf(element):返回元素在链表中的索引,如果没有则返回-1
update(position):修改某个位置的元素
removeAt(position):删除指定位置的一项元素
remove(element):从链表中删除一项
isEmpty():判断链表是否为空,为空返回true,反之返回false
size():返回链表长度
toString():由于链表使用了Node类,就需要重新写继承自JavaScript对象默认的toString方法,值输出原元素的值//append方法
LinkedList.prototype.append=function(data){
//创建新结点
var newNode=new Node(data);
//判断是否为空
if(this.length==0){
this.head=newNode;
}else{
var current=this.head;
while(current){
current=current.next;
}
//最后一个节点指向空
current.next=null;
}
this.length+=1;
}
//toTring方法
LinkedList.prototype.toString=function(){
var current=this.head;
var ListString="";
while(current){
ListString+=current.data+" ";
current=current.next;
}
return ListString;
}
//insert方法
LinkedList.prototype.insert=function(position,data){
//越界判断
if(position<0||position>this.length){
return false;
}
//创建节点
var newNode=new Node();
//判断插入位置是否为第一个
if(position==0){
newNode.next=this.head;
this.head=newNode;
}else{
var index=0;
var current=this.head;
var previous=null;
while(index++<position){
previous=current;
current=current.next;
}
newNode.next=current;
previous.next=newNode;
}
this.length+=1;
return true;
}
//get方法
LinkedList.prototype.get=function(position){
//越界判断
if(position<0||position>=this.length){
return null;
}
//获取对应的data
var index=0;
var current=this.head;
while(index++<position){
current=current.next;
}
return current.data;
}
//indexOf方法
LinkedList.prototype.indexOf=function(data){
var index=0;
var current=this.head;
while(current){
if(current.data==data){
return index;
}
index+=1;
current=current.next;
}
return -1;
}
//update方法
LinkedList.prototype.updata=function(position,element){
//越界判断
if(position<0||position>=this.length){
return false;
}
//查找
var index=0;
ivar current=this.head;
while(index++<position){
current=current.next;
}
current.data=element;
return true;
}
//removeAt方法
LinkedList.prototype.removeAt=function(position){
//判断越界
if(position==0||position>=this.length){
return null;
}
//判断删除的是否为第一个
if(position==0){
this.head=this.head.next;
}else{
var index=0;
var current=this.head;
var previous=null;
while(index++<position){
previous=current;
current=current.next;
}
previous.next=current.next;
}
this.length-=1;
return current.data;
}
//remove方法
LinkedList.prototype.remove=function(data){
//获取data在链表中的位置
var position=this.indexOf(data);
//根据节点位置删除结点
return this.removeAt(position);
}
//isEmpty方法
LinkedList.prototype.isElempty=function(){
return this.length==0;
}
//size方法
LinkedList.prototype.size=function(){
return this.length;
}(二)双向链表
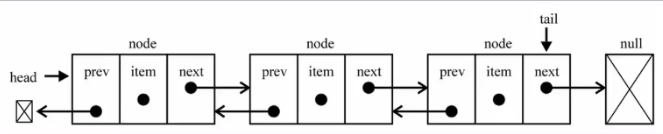
(一)特点
既可以从头遍历到尾,又可以从尾遍历到头
一个节点既有向前链接的引用,又有向后链接的引用
可以使用一个head和一个tail分别指向头部和尾部
每个节点由三部分组成:前一个节点的指针(prev)、保存的元素(item)、后一个节点的指针(tail)
双向链表的第一个节点的prev==null
双向链表的最后一个节点的tail==null
(二)缺点
每次插入删除的时候需要处理四个引用,实现比较困难
相对于单链表来说,内存空间比更大一些
(三)封装
function DoublyLinkedList(){
//内部类
function Node(data){
this.data=data;
this.prev=null;
this.next=null;
}
//属性
this.head=null;
this.tail=null;
this.length=0;
//常见操作
}(四)常见操作
append():向链表尾部添加新元素
insert(position,element):向指定位置添加新元素
get(position):获取指定位置的元素
indexOf(element):返回元素在链表中的索引,若没有返回-1
update(position,element):修改某个位置的元素
removeAt(position):删除链表特定位置的元素
remove(element):删除链表元素
isEmpty():判断链表是否为空,为空返回true,反之返回false
size():返回链表长度
toTring():由于链表使用了Node类,就需要重新写继承自JavaScript对象默认的toString方法,值输出原元素的值
forwardString():返回正向遍历的节点字符串形式
backWordString():返回反向遍历的节点字符串形式//apped方法
DoublyLinkedList.prototype.append=function(data){
//创建新节点
var newNode=new Node(data);
//判断添加的是否为第一个节点
if(this.length==0){
this.head=newNode;
}else{
var current=this.head;
while(current.next){
current=current.next;
}
//让最后节点的next指向新结点
current.next=newNode;
}
this.length+=1;
}
//toString方法
DoublyLinkedList.prototype.toString=function(){
returnthis.backwardString();
}
//forwardString方法
//从后往前
DoublyLinkedList.prototype.fowardString=function(){
var current=this.tail;
var resulrString="";
while(current){
resultString+=current,data+" ";
current=current.prev;
}
return resultString;
}
//backWordString方法
//从前往后
DoublyLinkedList.prototype.backwardString=function(){
var current=this.head;
var resultString="";
while(current){
resultString+=current.data+" ";
current=current.next;
}
return resultString;
}
//insert方法
DoublyLinkedList.prototype.insert=function insert(position,data){
if(position<0||this.length){
return false;
}
//根据dta 创建新结点
var newNode=new Node(data);
//判断原来的链表是否为空
if(this.length==0){
this.head==0;
this.tail==0;
}else{
//判断position是否为0
if(position==0){
this.head.prev=newNode;
newNode.next=this.head;
this.head=newNode;
}else if(position==this.length){
newNode.prev=this.tail;
this.tail.next=newNode;
this.tail=newNode;
}else{
var current=this.head;
var index=0;
while(index++<position){
current=current.next;
}
newNode.next=current;
newNode.prev=current.prev;
current.prev.next=newNode;
current.prev=newNode;
}
}
this.length+=1;
}
//get方法
DoublyLinkedList.prototype.get=function get(position){
if(position<0||position>this.length){
retuan null;
}
var current=this.head;
var index=0;
while(index++<position){
current=current.next;
}
return current.data;
}
//indexOf方法
DoublyLinkedList.prototype.indexOf=function indexOf(data){
var current=this.head;
var index=0;
while(current){
if(current.data=data){
return index;
}
current=current.next;
index++;
}
return -1;
}
//update方法
DoublyLinkedList.prototype.updata=function updata(position,newdata){
if(position<0||position>=this.length){
return false;
}
var current=this.head;
var index=0;
while(index++<position){
current=current.next;
}
current.data=newdata;
return true;//表示修改成功
}
//removeAt方法
DoublyLinkedList.prototype.removeAt=function removeAt(position){
if(position<0||position>=this.length){
return null;
}
//判断节点是否为1
var current=this.head;
if(this.lenth==1){
this.head=null;
this.tail=null;
}else{
if(position==1){//判断删除的节点是否是第一个
this.head.prev.next=null;
this.head=this.head.next;
}else if(position==this.length-1){//判断删除的节点是否是最后一个
current=this.tail;
this.tail.prev.next=null;
this.tail=this.tail.prev;
}else{
var index=0;
while(index++<position){
current=current.next;
}
current.prev.next=current.next;
current.next.prev=current.prev;
}
}
this.length-=1;
return current.data;
}
//remove方法
DoublyLinkedList.prototype.remove=function remove(element){
//根据data获取下标志
var index=this.indexOf(element);
//根据index删除对应信息
return this.removeAt(index);
}
//isEmpty方法
DoublyLinkedList.prototype.isEmpty=function isEmpty(){
return this.length==0;
}
//size方法
DoublyLinkedList.prototype.size=function size(){
return this.length;
}
//返回链表的第一个元素
DoublyLinkedList.prototype.getHead=function getHead(){
return this.head.data;
}
//返回链表的最后一个元素
DoublyLinkedList.prototype.getTail=function getTail(){
return this.tail.data;
}
六、集合
(一)特点
元素无序、不能重复
(特殊的数组,也用于元素的存储)
(二)封装
//封装集合类
function Set(){
//属性
this.items={};
//方法
}(三)常见操作
add(value):向集合添加新元素
remove(value):删除集合元素
has(value):判断元素是否在集合中,若在返回true,反之返回false
clear():删除集合中所有元素
size():返回集合包含元素的数量]
values():返回一个包含集合中所有值得数组//add方法
Set.prototype.add=function add(value){
//判断当前对象是否包含属性
if(this.has(value)){
return false;
}
//将当前元素添加到集合中
this.items[value]=value;
return true;
}
//has方法
Set.prototype.has=function has(value){
return this.items.hasOwnProperty(value);
}
//remove方法
Set.prototype.remove=function remove(value){
//判断集合中是否含有该元素
if(!this.has(value)){
return false;
}
delete this.items[value];
return true;
}
//clear方法
Set.prototype.clear=function clear(){
this.items={};
}
//size方法
Set.prototype.size=function size(){
return Object.keys(this.items).length;
}
//获取集合中所有元素
Set.prototype.values=function values(){
return Object.keys(this.value);
}(四)集合间的操作
(一)并集
对于给定的两个集合,返回一个包含两个集合中所有元素的新集合
Set.prototype.union=function (otherSet){
//this:集合对象A
//otherSet:集合对象B
//创建新集合
var unionSet=new Set();
//将集合A中所有的元素添加到新集合中
var values=this.values();
for(var i=0;i<values.length;i++){
unionSet.add(value[i]);
}
//取出B中所有元素,判断是否要添加到新集合中
values=otherSet.values();
for(var i=0;i<value.length;i++){
unionSet.add(value[i]);
}
//返回新数组
return unionSet;
}(二)交集
对于给定的两个集合,返回一个包含两个集合中公共元素的新集合
Set.prototype.union=function (otherSet){
//this:集合对象A
//otherSet:集合对象B
//创建新集合
var unionSet=new Set();
//将集合A中所有的元素添加到新集合中
var values=this.values();
for(var i=0;i<values.length;i++){
unionSet.add(value[i]);
}
//取出B中所有元素,判断是否要添加到新集合中
values=otherSet.values();
for(var i=0;i<value.length;i++){
unionSet.add(value[i]);
}
//返回新数组
return unionSet;
}(三)差集
对于给定的两个集合,返回一个所有存在于第一个集合且不存在于第二个集合的元素的新集合
Set.prototype.difference=function(otherSet){
//this:集合A
//otherSet:集合B
//创建新集合
var differenceSet=new Set();
//取出集合A中的元素,判断是否存在于集合B中,不存在时,添加到新集合中
var values=this.values();
for(var i=0;i<values.length;i++){
var item=values[i];
if(!otherSet.has(item)){
differenceSet.add(item);
}
}
//返回新数组
return differerceSet;
}(四)子集
验证一个给定集合是否是另一个集合的子集
Set.prototype.subSet=function(otherSet){
//this:集合A
//otherSet:集合B
//遍历集合A中所有的元素,如果发现,集合A中的元素,在集合B中不存在,那么返回false
//如果遍历完了集合,依然没有返回false,那么返回true
var values=this.values();
for(var i=0;i<values.length;i++){
var item=values[i];
if(!otherSet.has(item)){
return false;
}
}
return true;
}七、树
(一)介绍
由n个节点构成的有限集合,用于存储数据
(二)优点
插入、查询、删除的效率较高
(三)树的术语
- 节点的度(Degree):节点的子树个数
- 树的度:树的所有节点总最大的度数
- 叶节点(leaf):度为0的节点(也称为叶子节点)
- 父节点:有子树的节点是其子树的根节点的父节点
- 子节点:若A节点是B节点的父节点,则称B节点是A节点的子节点(也称为孩子节点)
- 兄弟节点:具有同一个父节点的各个节点彼此是兄弟节点
- 路径和路径长度:从节点n1到nk的路径为一个节点序列n1,n2,...,nk,ni是ni+1的父节点。路径所包含边的个数称为路径的长度
- 节点的层次:规定根节点在1层,其他任一节点的层数是父节点的层数+1
- 树的深度:树中所有节点的最大层次是这棵树的深度
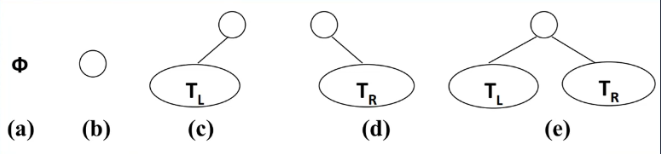
(四)二叉树
(一)定义
如果树中每个节点最多只能有两个节点,则称为二叉树
二叉树可以为空,即没有节点
若不为空,则它是由根节点和左子树和右子树组成
二叉树的五种形态:
(二)特性
一个二叉树的第i层的最大节点数为:2^(i-1),i>=1
深度为k的二叉树有最大节点总数为:2^k-1,k>=1
对于任何给非空二叉树,若n0表示叶节点的个数,n2是度为2的非叶节点个数,那么两者满足关系:n0=n2+1

(五)二叉搜索树
又称为二叉排序树、二叉查找树,可以快速的找到给定关键词的数据项,并且可以快速的插入和删除数据项
(一)性质
-
二叉搜索树也是一颗二叉树,可以为空
-
非空左子树的所有键值小于其根节点
-
非空右子数的所有键值大于其根节点
-
左、右子数本身也都是二叉搜索树
(二)封装
function BinarySearchTree(){
function Node(key){
this.key=key;
this.left=null;
this.right=null;
}
//性质
this.root=null;
//方法
}(三)常见操作
insert(key):向树中插入一个新的键
search(key):在树中查找一个键,若存在则返回true,反之返回false
min():返回树中最小值
max():返回树中最大值
remove(key):删除树中某个键//insert方法
BinarySearchTree.prototype.insert=function(key){
//根据key创建节点
var newNode=new Node(key);
//判断节点是否有值
if(this.root==null){
this.root=newNode;
}else{
this.insertNode(node,newNode);
}
}
//递归实现插入
BinarySearchTree.prototype.insertNode=function(node,newNode){
if(newNode.key<node.key){
//向左查找
if(node.left==null){
node.left=newNode;
}else{
this.insertNode(node.left,newNode);
}
}else{
//向右查找
if(node.right==null){
node.right=newNode;
}else{
this.inserNode(node.right,newNode);
}
}
}
//search方法
BinarySearchTree.prototype.search=function(key){
var node=this.root;
while(node!=null){
if(k<node.key){
node=node.left;
}else if(key>node.key){
node=node.right;
}else{
return true;
}
}
return false;
}
//max方法
BinarySearchTree.prototype.max=function(){
//获取节点
var node=this.root;
var key=null;
while(node!=null){
key=node.key;
node=node.right;
}
return key;
}
//min方法
BinarySearchTree.prototype.min=function(){
var node=this.root;
var key=null;
while(node!=null){
key=node.key;
node=node.left;
}
return key;
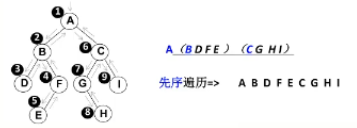
}(四)先序遍历
遍历过程:根节点、左子树、右子树(即:中左右)
BinarySearchTree.prototype.preOrderTraverse=function preOrderTraverse() {
let res = [];
this.preOrder(this.root, res);
return res;
}
BinarySearchTree.prototype.preOrder=function preOrder(node, res) {
if (node) {
res.push(node.key);
this.preOrder(node.left, res);
this.preOrder(node.right, res);
}
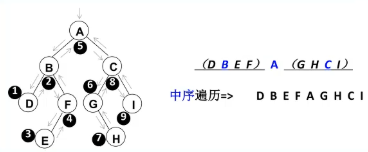
}(五)中序遍历
遍历过程:左子树、根节点、右子树(即:左中右)
BinarySearchTree.prototype.inOrderTraverse=function inOrderTraverse() {
let res = [];
this.inOrder(this.root, res);
return res;
}
BinarySearchTree.prototype.inOrder=function inOrder(node, res) {
if (node) {
this.inOrder(node.left, res);
res.push(node.key);
this.inOrder(node.right, res);
}
}(六)后序遍历
遍历过程:左子树、右子树、根节点(即:左右中)
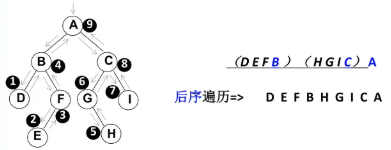
BinarySearchTree.prototype.postOrderTraverse=function postOrderTraverse() {
let res = [];
this.postOrder(this.root, res);
return res;
}
BinarySearchTree.prototype.postOrder=function postOrder(node, res) {
if (node) {
this.postOrder(node.left, res);
this.postOrder(node.right, res);
res.push(node.key);
}
}(七)删除结点
1、情况一:没有子节点
相对简单,若父节点的left和right都不为null,将其设置为null即可,若删除的为根节点,则只需将根节点的left和right设置为null即可
2、情况二:有一个子节点
需要找到三个结点:要删除的节点A,A的父节点,A的子节点;让A的父节点与A的子节点相连即可。若A链接的是父节点的left,则让父节点的left与子节点相连,若A链接的是父节点的right,则让父节点的right与自己的相连即可
3、情况三:有两个子节点
这种情况相对复杂,但是也不难,两种处理方式:
- 若要删除的节点A,则需找到A的左子树中最大的节点,来替换A节点,其余节点自动补齐;
- 若要删除的节点A,则需找到A的右子树中最大的节点,来替换A节点,其余节点自动补齐;
BinarySearchTree.prototype.remove=function(key){
//1.寻找要删除的节点
//定义变量保存信息
var current=this.root;
var parent=this.root;
var isLeftChild=true;//记录删除的是不是left
//开始查找
while(current.key!=key){
parent=current;
if(key<current.left){
isLeftChild=true;
current=current.left;
}else{
isLeftChild=false;
current=current.right;
}
//找到最后还是没有找到对应节点
if(current==null){
return false;
}
}
//2.根据对应情况删除结点
//2.1删除的结点没有叶子节点(没有子节点)
if(current.left==null&¤t.right==null){
if(current==this.root){
this.root=null;
}else if(isLeftChild){
parent.left=null;
}else{
parent.right=null;
}
}
//2.2删除的节点有一个子节点
else if(current.right==null){
if(current==this.root){
this.root=current=left;
}
else if(isLeftChild){
parent.left=current.left;
}else{
parent.right=current.left;
}
}else if(current.left=null){
if(current=this.root){
this.root=current.right;
}
else if(isLeftChild){
parent.left=current.right;
}else{
parent.right=current,right;
}
}
//2.3删除的节点有两个子节点
else{
//获取后继节点
var successor=this.getSuccessor(current);
//判断是否为根节点
if(current==this.root){
this.root=successor;
}else if(isLeftChild){
parent.left=successor;
}else{
parent.right=sucessor;
}
//将删除结点的左节点
successor.left=current.left;
}
}
//找后继的方法
BinarySearchTree.prototype.getSuccessor=function(delNode){
//定义变量,保存找到的后继
var successor=delNode;
var current=delNode.right;
var successorParent=delNode;
//循环查找
while(current!=null){
successorParent=successor;
successor=current;
current=current.left;
}
//判断寻找的后继结点是否直接就是delNOde的right节点
if(successor!=delNode.right){
successorParent=successor.right;
successor.right=delNode.right;
}
return successor;
}(八)二叉搜索树的缺点
当插入的数据是有序的数据时,会造成麻烦
(九)二叉树的查找效率
log n
八、图
(一)定义
图论是数学的一个分支,在概念上,树是图的一种
以图为研究对象,研究顶点和边组成的图形的数学理论和方法
主要研究事物之间的关系,顶点代表事物,边代表两个事物之间的关系
生活案例:地铁、人际关系网、村庄关系网等等
(二)特点
一组顶点:通常用V(Vertex)表示
一组边:通常用E(Edge)表示
边是顶点和顶点之间的连线
边有有向(A-->B)和无向(A--B)
(三)图的常见术语
- 顶点:表示图中的一个点
- 边:顶点和顶点之间的连线
- 相邻顶点:由一条边链接在一起的顶点称之为相邻顶点
- 度:一个顶点的度就是相邻顶点的数量
- 简单路径:不包含重复的顶点
- 回路:第一个顶点和最后一个顶点相同
- 无向图:所有的边都没有方向
- 有向图:图中的边是有方向的
- 无权图:边没有携带权重
- 有权图:边有一定的权重
(四)图的表示
(一)邻接矩阵表示法
让每个节点和一个整数相关联,用整数作为数组的下标值
使用二维数组表示顶点之间的连接
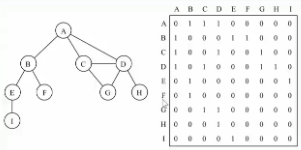
在二维数组中,0表示没有连线,1表示有连线
通过二维数组可以很快的找到一个顶点和那些顶点有连线
通常顶点到自己的连线用0表示,即A - A,B - B
(二)邻接表
由每个顶点以及顶点相邻的顶点列表组成
可以用数组、链表、哈希表、字典存储
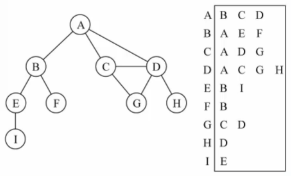
如果要表示和A顶点有关的顶点(边),A和B/C/D有边,即可通过A找到对应的数组、链表、字典,在取出即可
(五)封装图
function Graph(){
//属性:顶点(数组)/边(字典)
this.vertexes=[];//顶点
this.edges=new Dictionay();//边
//方法
}//添加顶点
Graph.prototype.addVertex=function(v){
this.vertexes.push(v);
this.edges.set(v,[]);
}
//添加边
Graph.prototypr.addEdge=function(v1,v2){
//添加为无向图
this.edges.get(v1).push(v2);
this.edges.get(v2).push(v1);
}
//toString方法
Graph.prototype.toString=function(){
//定义字符串保存最终结果
var resultString="";
//遍历所有顶点,以及顶点对应的边
for(bar i=0;i<this.vertexes.length;i++){
resiltString+=this.vertexes[i]+'->';
var vEdges=this.edges.get(this.vertexes[i]);
for(var j=0;j<vEdges.length;j++){
resuleString+=vEdges[j]+" ";
}
//换行
resuleString+="\n";
}
return resultString;
}(六)图的遍历
需要将图中每一个顶点访问一遍,并且不能有重复的访问
(一)方法
广度优先搜索
深度优先搜索
(均需要明确指定第一个被访问的顶点)
(二)思想
1、BFS:基于队列,入队列的顶点先被探索
2、DFS:基于栈或使用递归,通过将顶点存如栈中,顶点是沿着路径被探索的,存在新的相邻顶点就去访问
可以使用颜色反应状态
- 白色:该顶点还没有被访问
- 灰色:该顶点被访问过,但是没有被探索过
- 黑色:该顶点被访问过,且被探索过
//初始化颜色
Graph.prototype.initializeColor=function(){
var colors=[];
for(var i=0;i<this.vertexes.length;i++){
colors[this.vertexes[i]]="white";
}
sreturn colors;
}(三)广度优先搜索
会从指定的一个顶点开始遍历图,先访问其所有相邻点,就像一次访问图的一层(先宽后深访问顶点)
图解BFS

实现
Graph.prototype.bfs=function(initv,handler){//参数:传入的顶点,处理方式
//初始化颜色
var colors=this.initializeColor();
//创建队列
var queue=new Queue();
//将顶点添加到队列中
queue.enqueue(initv);
//循环从队列中提取元素
while(!queue.isEmpty()){
//从队列中提取一个顶点
var v=queue.dequeue();
//获取和顶点相连的另外顶点
var vList=this.edges.get(v);
//将v的颜色改为gray
colors[v]='gray';
//遍历所有节点并加入到队列中
for(var i=0;i<vList.length;i++){
var e=vList[i];
if(colors[e]=='white'){
colors[e]='gray';
queue.enqueue(e);
}
}
//访问顶点
handler(v);
//将顶点设置成黑色
colors[v]="black";
}
}(四)深度优先搜索
会从图的第一各指定顶点开始遍历图,沿着路径直到这条路径最后被访问了,接着原路回退并探索下一条路径

Graph.prototype.dfs=function(initv,handler){
//初始化颜色
var colors=this.initializeColor();
//从某个顶点开始访问
this.dfsVisit(initV,colors,handler);
}
Graph.prototype.dfsVisit=function(v,colors,handler){
//将颜色设置成灰色
colors[v]='gray';
//处理v顶点
handler(v);
//访问v相连的顶点
var vList=this.edges.get(v);
for(var i=0;i<vList.length;i++){
var e=vList[i];
if(colors[e]=='white'){
this.dfsVisit(e,colors,handler);
}
}
//将v设置成黑色
colors[v]="black";
}














 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









