







图的定义
顶点:在图中常常将数据元素称为顶点(vertex)。
图(graph):图是由顶点的有穷的非空集合和顶点之间边的集合组成的。
无向图:如果图的任意两个顶点之间的边都是无向边,则称该图为无向图;反之称之为有向图。
有向图:见上。
邻接:在无向图中,对于任意两个顶点v和u,如果存在边(v,u),则称呼v和u互为邻接点(adjacent);在有向图中,对于任意两个顶点v和u,如果存在边< v,u>,则称v**邻接到u,顶点u邻接自v,在不混淆的情况下,通常称呼u是v的邻接点**。
依附:在无向图中,对于任意两个顶点v和u,如果存在边(v,u),则称呼边(v,u)依附于(adhere)顶点v和顶点u。
无向完全图: 如果任意两个顶点之间都存在边的话,就称该图为无向完全图。
- 含有n个顶点的无向完全图有nx(n-1)/2条边。
有向完全图:如果任意两个顶点之间都存在方向相反的两条弧的话,就称该图为有向完全图。
- 含有n个顶点的有向完全图有nx(n-1)条边。
顶点的入度:就是以该顶点作为弧头的弧的个数。
顶点的出度:就是以该顶点作为弧尾的弧的个数。
网:边上带权的图称为网或者网图。
路径(Path):对无向图G=(V,E),若从顶点vi经过若干条边能到达vj,称顶点vi和vj是连通的,又称顶点vi到vj有路径。
- 在图中,路径可能不唯一。
路径长度:路径上边或有向边(弧)的数目称为该路径的长度。
简单路径:在一条路径中,若没有重复相同的顶点,该路径称为简单路径。
回路(Cycle) :第一个顶点和最后一个顶点相同的路径称为回路(环)。
- 在图中,回路可能不唯一。
简单回路:在一个回路中,若除第一个与最后一个顶点外,其余顶点不出现重复的回路称为简单回路(简单环)。
连通图:在无向图中,若任意两个顶点之间都存在有路径,那么称该图是连通图。
连通分量:在无向图中,非连通图的极大连通子图称为连通分量,“极大”的含义就是说包括所有连通的顶点和这些顶点相关联的所有的边。
强连通图:在有向图中,若任意两个顶点之间都存在有路径,那么称该有向图是强连通图。
连通分量:在有向图中,非连通图的极大强连通子图称为强连通分量,“极大”的含义就是说包括所有连通的顶点和这些顶点相关联的所有的边。
详细的定义可以见阳光日志的博客:
图的存储
图的几种常见的存储结构。
邻接矩阵
基本思想
对于有n个顶点的图,用一维数组vertex[n]存储顶点信息,用二维数组arc[n][n]存储顶点之间关系的信息。该二维数组称为邻接矩阵。在邻接矩阵中,以顶点在vertex数组中的下标代表顶点,邻接矩阵中的元素arc[i][j]存放的是顶点i到顶点j之间关系的信息。
详细的定义可以见阳光日志的博客:
邻接表
基本思想
对图的每个顶点建立一个单链表,存储该顶点所有邻接顶点及其相关信息。每一个单链表设一个表头结点。
详细的定义可以见阳光日志的博客:
结构体
vertex为数据域,存放顶点的信息;
firstedge是指针域,指向表中第一个结点;
adjvex为邻接点域,存放该顶点的邻接点在顶点表中的下标;
next为指针域,指向边表中的下一个结点。
// 边表结点
struct ArcNode {
int adjvex;
ArcNode *next;
};
// 顶点表结点
template <class DataType>
struct VertexNode {
DataType vertex;
ArcNode *firstedge;
};图的遍历操作
图的遍历是图中最基本的操作。
图的遍历我们一般是采用一个标记数组(visited[])来标记图中顶点的被访问情况的,标记数组的初始值是0,被访问的顶点的在标记数组中对应位置的值为1.
深度优先遍历
深度优先遍历和树的前序遍历有点类似。
逻辑
- 访问顶点v
- 从v的为访问的邻接点中选取一个顶点w,从w出发进行深度优先遍历
- 重复上述两步,直至图中所有的和v有路径相通的顶点都被访问。
主要代码:
DFSTraverse()中的形参是顶点的在数组中的下标。
备注: 这里使用的是邻接矩阵来实现的,邻接表的有兴趣的各位自己实现。
其中visited[]是一个数组,具体定义如下:
const int MaxSize = 20;
int visited[MaxSize] = {0};初始化过程是:
for (int i=0;i < MaxSize; i++) {
visited[i] = 0;
}深度优先遍历的核心代码:
template <class DataType>
void MGraph<DataType>::DFSTraverse(int v) {
cout<<vertex[v];
visited[v] = 1;
for (int j = 0;j < vertexNum; j++) {
if (arc[v][j] > 0 && visited[j] == 0) {
DFSTraverse(j);
}
}
}广度优先遍历
广度优先遍历和树的层序遍历有点相似,都是使用队列的方式进行遍历。
逻辑
- 访问顶点v
- 依次访问v的各个未被访问的邻接点v1,v2…vk;
- 分别从v1,v2…vk出发依次访问他们未被访问的邻接点,并使“先被访问顶点的邻接点”先于“后被访问顶点的邻接点”被访问。直至图中所有与顶点v有路径想通的顶点都被访问到。
主要代码
BFSTraverse()中的形参是顶点的在数组中的下标。
备注: 这里使用的是邻接矩阵来实现的,邻接表的有兴趣的各位自己实现。
其中visited[]是一个数组,具体定义如下:
const int MaxSize = 20;
int visited[MaxSize] = {0};初始化过程是:
for (int i=0;i < MaxSize; i++) {
visited[i] = 0;
}深度优先遍历的核心代码:
template <class DataType>
void MGraph<DataType>::BFSTraverse(int v) {
int Q[MaxSize];
int front = -1;
int rear = -1;
cout<<vertex[v];
visited[v] = 1;
Q[++rear] = v;
while (front != rear) {
v = Q[++front];
for (int j = 0;j < vertexNum; j++) {
if (arc[v][j] > 0 && visited[j] == 0) {
cout<<vertex[j];
visited[j] = 1;
Q[++rear] = j;
}
}
}
}图的实现代码
# include <iostream>
# include <limits.h>
# include <string>
# include <sstream>
# include <cstdlib>
using namespace std;
const int MaxSize = 20;// 图中最多的顶点的个数
int visited[MaxSize] = {0};
template <class DataType>
class MGraph {
public:
MGraph(DataType a[], int n, int e);// 构造函数
~MGraph() {}// 析构函数
void DFSTraverse(int v);// 深度优先遍历
void BFSTraverse(int v);// 广度优先遍历
void TSP(int v);
private:
int findMIN(int visited[],int v);// 找出权值最小的边
DataType vertex[MaxSize];// 存放图中顶点的数组
int arc[MaxSize][MaxSize];// 存放图中边的数组
int vertexNum,arcNum;// 图的顶点数和边数
int s[MaxSize];
int head;// 保存的顶点
void printVisted(int visited[]);// 打印输出
};
/**
* 打印输出
* @param visited[] 标记数组
**/
template <class DataType>
void MGraph<DataType>::printVisted(int visited[]) {
cout<<"visited为:"<<endl;
cout<<"---------------"<<endl;
for (int i = 0;i < vertexNum; i++) {
cout<<visited[i]<<" ";
}
cout<<endl<<"---------------"<<endl;
}
/**
* 找出权值最小的边
* @param visited[] 标记数组
* @param v 顶点
**/
template <class DataType>
int MGraph<DataType>::findMIN(int visited[],int v) {
int temp;
for (int i = 0;i < vertexNum; i++) {
if (visited[i] != 1) {
temp = i;
}
}
for (int i = 0;i < vertexNum; i++) {
if (i != v && visited[i] != 1) {
if (arc[v][temp] > arc[v][i]) {
temp = i;
}
}
}
return temp;
}
/**
* TSP问题——找出最短路径
* @param v 顶点
**/
template <class DataType>// v = 0
void MGraph<DataType>::TSP(int v) {
head = v;
int i,j,k;
int s[vertexNum];
int visited[vertexNum];
for (i = 0;i < vertexNum; i++) {
s[i] = -1;
visited[i] = 0;
}
s[0] = v;
visited[v] = 1;// 10000
printVisted(visited);
int num = 1;
while (num < vertexNum) {
int temp = findMIN(visited, s[num-1]);// 10000 10010 10110 10111 11111
cout<<"num = "<<num<<endl;
cout<<temp<<endl;
s[num] = temp;
num++;
visited[temp] = 1;
printVisted(visited);
}
cout<<endl;
for (i = 0; i < vertexNum; ++i)
{
cout<<vertex[s[i]]<<" ";
}
cout<<endl;
}
/**
* 构造函数
* @param a[] 顶点的名称
* @param n 顶点数
* @param e 边数
**/
template <class DataType>
MGraph<DataType>::MGraph(DataType a[],int n,int e) {
int i,j,k,weight;
vertexNum = n;
arcNum = e;
for (i = 0;i < vertexNum; i++) {
vertex[i] = a[i];
}
for (i = 0;i < vertexNum; i++) {
for (j = 0;j < vertexNum; j++) {
arc[i][j] = 0;
}
}
for (k = 0;k < arcNum / 2; k++) {
cout<<"Please enter the number of two vertices(former -> later):";
cin>>i>>j;
cout<<"Please enter the weight :";
cin>>weight;
arc[i][j] = weight;
arc[j][i] = weight;
}
for (i = 0;i < vertexNum; i++) {
for (j = 0;j < vertexNum; j++) {
if (arc[i][j] == 0)
arc[i][j] = INT_MAX;
}
cout<<endl;
}
//system("cls");
cout<<"show the arc[vertexNum][vertexNum]:"<<endl;
for (i = 0;i < vertexNum; i++) {
for (j = 0;j < vertexNum; j++) {
cout<<arc[i][j]<<"\t\t";
}
cout<<endl;
}
}
/**
* 深度优先遍历
* @param v 顶点
**/
template <class DataType>
void MGraph<DataType>::DFSTraverse(int v) {
cout<<vertex[v];
visited[v] = 1;
for (int j = 0;j < vertexNum; j++) {
if (arc[v][j] > 0 && visited[j] == 0) {
DFSTraverse(j);
}
}
}
/**
* 广度优先遍历
* @param v 顶点
**/
template <class DataType>
void MGraph<DataType>::BFSTraverse(int v) {
int Q[MaxSize];
int front = -1;
int rear = -1;
cout<<vertex[v];
visited[v] = 1;
Q[++rear] = v;
while (front != rear) {
v = Q[++front];
for (int j = 0;j < vertexNum; j++) {
if (arc[v][j] > 0 && visited[j] == 0) {
cout<<vertex[j];
visited[j] = 1;
Q[++rear] = j;
}
}
}
}
int main() {
char ch[] = {'A','B','C','D','E'};
MGraph<char> MG(ch,5,20);
for (int i=0;i < MaxSize; i++) {
visited[i] = 0;
}
cout<<"深度优先遍历序列是:";
MG.DFSTraverse(0);
cout<<endl;
for (int i=0;i < MaxSize; i++) {
visited[i] = 0;
}
cout<<"广度优先遍历序列式:";
MG.BFSTraverse(0);
cout<<endl;
cout<<"最短路径是:";
MG.TSP(0);
cout<<endl;
return 0;
}最小生成树
定义
设G = (V,E)是一个无向连通网,生成树上各边的权值之和称为该生成树的代价,在G的所有生成树中,代价最小的生成树称为最小生成树。
Prim
Kruskal
最短路径
在非网图中,最短路径就是值两个顶点之间经历的边数最少的路径,路径上的第一个顶点称为源点,最后一个顶点称为终点。
Dijkstra
该算法是求单源点最短路径问题。
主要思想
选定一个源点,不断寻找距离源点最近的顶点,直到经过所有的顶点。
示意图
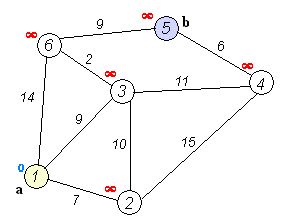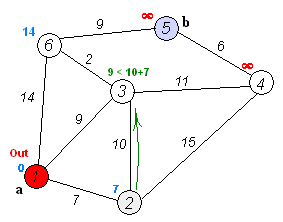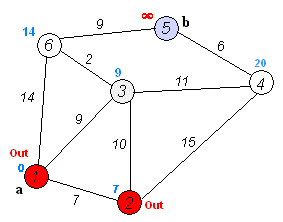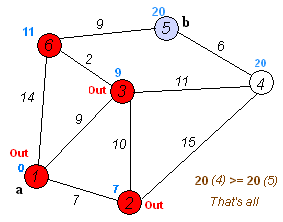
- 备注:图片来源于 —— 华山大师兄的最短路径—Dijkstra算法和Floyd算法
存储结构
- 图的存储结构:因为在算法执行过程中,需要快速的求得任意两个顶点之间边上的权值,所以,图采用邻接矩阵存储。
- 辅助数组dist[n]:元素dist[i]表示当前所找到的从原点v到重点vi的最短路径长度。
- 初态为:若从v到vi有弧,则dist[i]为弧上的权值;
- 否则,置dist[i]为无穷大(备注,在编码中是将其设置为该类型的最大值,比如int类型的设置为int类型的最大值)
- 辅助数组path[n]:元素path[i]是一个串,则path[i]为“vvi”,否则置path[i]为空串。
- 数组s[n]:存放源点和已经生成的重点(即集合S),初态为只有一个源点v。
伪代码
- 初始化数组dist、path和s;
- while(s中的元素个数< n)
- 在dist[n]中求最小值,其编号为k;
- 输出dist[k]和path[k];
- 修改数组dist和path;
- 将顶点k添加到数组s中;
Floyd
该算法用于求每一对顶点之间的最短路径的问题。
主要思想
核心思想是在两个顶点之间不断循环查找是否存在不直接通过两点之间的直达路径而是选择经过其他顶点路径的路径长度小于直达的路径长度。
存储结构
- 图的存储结构:因为在算法执行过程中,需要快速的求得任意两个顶点之间边上的权值,所以,图采用邻接矩阵存储。
- 辅助数组dist[n][n]:存放在迭代过程中求得的最短路径长度。初始值为图的邻接矩阵。其中dist[n][n]:是从顶点vi到vj的中间顶点的编号不大于k的最短路径的长度。
- 辅助数组path[n]:元素path[i]是一个串,则path[i]为“vvi”,否则置path[i]为空串。















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









