







JavaScript中的树
在使用数组存储时,根据下标值访问效率会很高,但是当想要使用元素来查找时,比较好的方法是对数组先排序,之后二分查找。
由此所带来的问题是查找时需要大量的操作,效率就比较低了
而链表对于插入与删除的操作效率虽然很高,但是查找效率依然很低,需要从头至尾访问一遍链表,直到找到。
而对于哈希表,一方面空间利用率不高,而且哈希表中的元素是无序的,不能按照固定的顺序来遍历哈希表中的元素
相比上面的结构,树结构的优点则更突出
- 树的定义:
- 树(Tree): n(n≥0)个结点构成的有限集合
- 当n=0时,称为空树
- 对于任一棵非空树(n> 0),它具备以下性质
- 树中有一个称为“根(Root)”的特殊结点,用 r 表示
- 其余结点可分为m(m>0)个互不相交的有限集T1,T2,… ,Tm,其中每个集合本身又是一棵树,称为原来树的“子树(SubTree)”
- 注意:
- 子树之间不可以相交
- 除了根结点外,每个结点有且仅有一个父结点
- 一棵N个结点的树有N-1条边
- 树的术语
- 1.结点的度(Degree):结点的子树个数
- 2.树的度:树的所有结点中最大的度数. (树的度通常为结点的个数N-1)
- 3.叶结点(Leaf):度为0的结点. (也称为叶子结点)
- 4.父结点(Parent):有子树的结点是其子树的根结点的父结点
- 5.子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点
- 6.兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点
- 7.路径和路径长度:从结点n1到nk的路径为一个结点序列n1 , n2,… , nk, ni是 ni+1的父结点。路径所包含边的个数为路径的长度
- 8.结点的层次(Level):规定根结点在1层,其它任一结点的层数是其父结点的层数加1
- 9.树的深度(Depth):树中所有结点中的最大层次是这棵树的深度
- 树(Tree): n(n≥0)个结点构成的有限集合
二叉树
二叉树定义:
- 二叉树可以为空, 也就是没有结点
- 若不为空,则它是由根结点和称为其左子树TL和右子树TR的两个不相交的二叉树组成
二叉树特性:
- 一个二叉树第 i 层的最大结点数为:2^(i-1), i >= 1
- 深度为k的二叉树有最大结点总数为: 2^k - 1, k >= 1
- 对任何非空二叉树 T,若n0表示叶结点的个数、n2是度为2的非叶结点个数,那么两者满足关系n0 = n2 + 1
特殊的二叉树
-
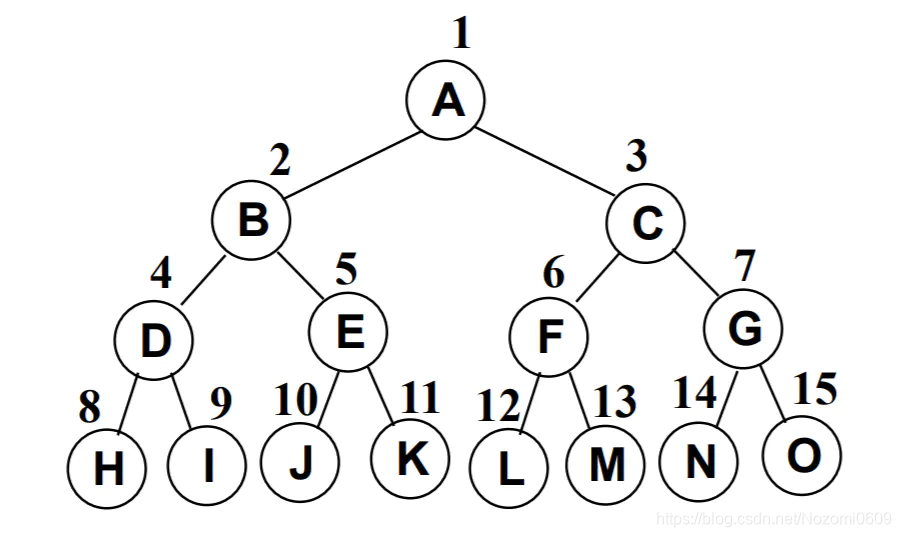
完美二叉树(Perfect Binary Tree) , 也称为满二叉树(Full Binary Tree)
在二叉树中, 除了最下一层的叶结点外, 每层节点都有2个子结点, 就构成了满二叉树
-
完全二叉树(Complete Binary Tree)
-
除二叉树最后一层外, 其他各层的节点数都达到最大个数
-
且最后一层从左向右的叶结点连续存在, 只缺右侧若干节点
-
完美二叉树是特殊的完全二叉树
-
二叉树的存储
数组存储
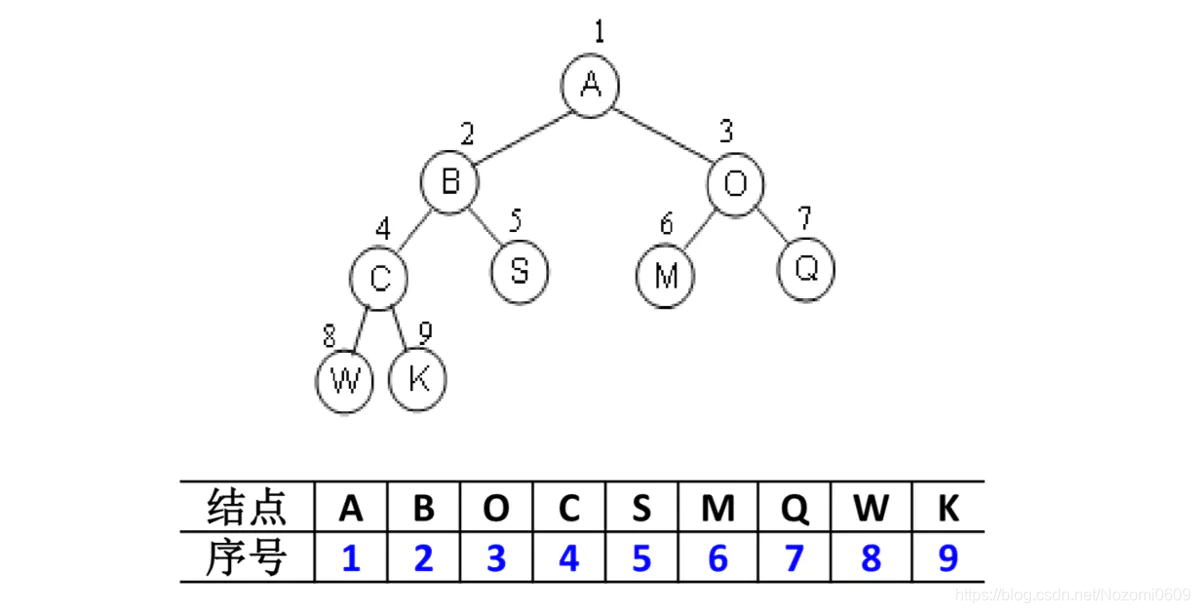
- 完全二叉树: 按从上至下、从左到右顺序存储
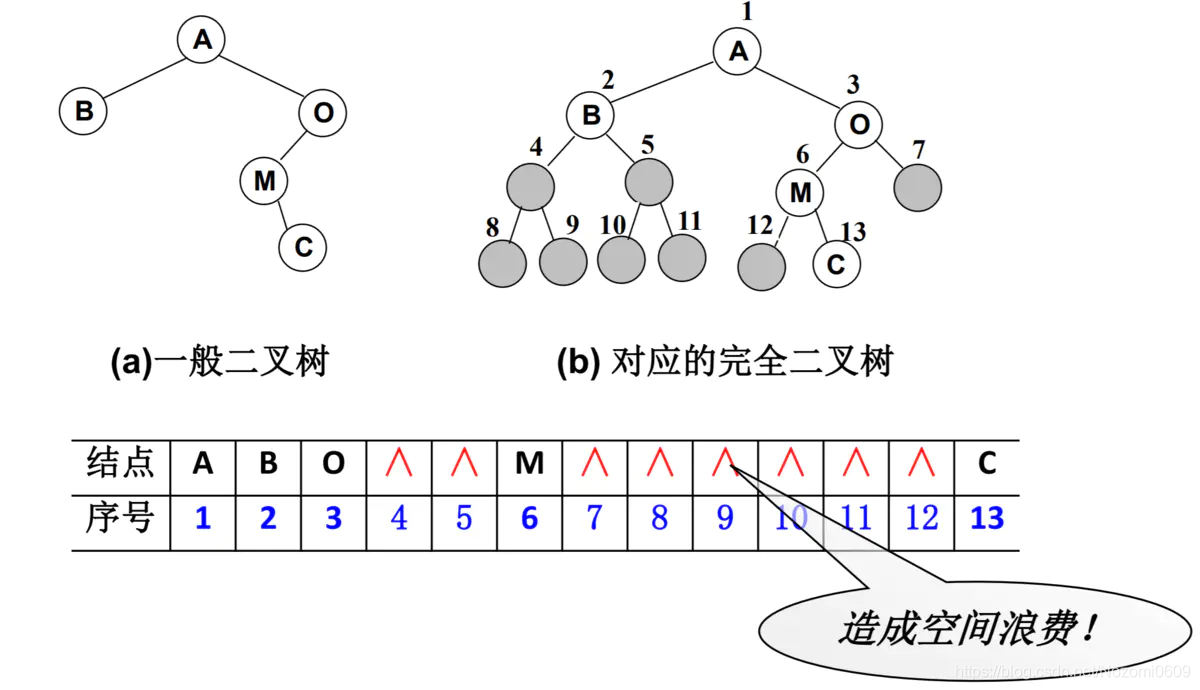
- 非完全二叉树:
- 非完全二叉树要转成完全二叉树才可以按照上面的方案存储,但会造成空间浪费
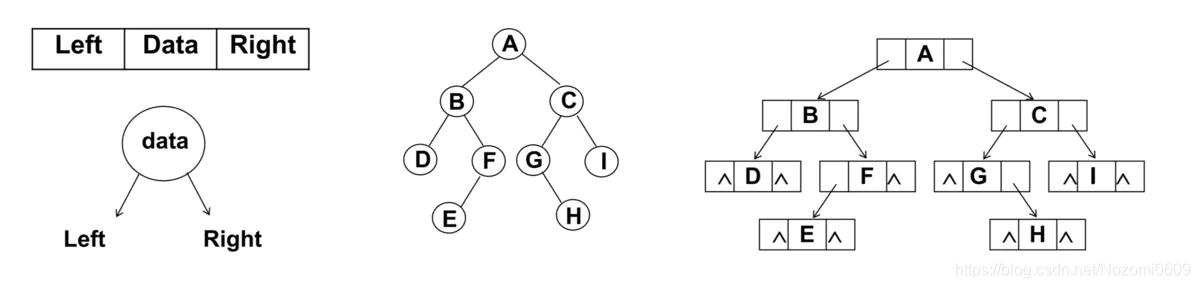
链表存储
- 二叉树最常见的方式还是使用链表存储
- 每个结点封装成一个Node, Node中包含存储的数据, 左结点的引用, 右结点的引用














 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









