







1.输入一个字符串,将该字符串中下标为偶数的字符组成新串并通过字符串格式化方式显示。
a = input("请输入一个字符串:")
b =a[1::2]
print("老串为:%a,新串为:%a"%(a,b))

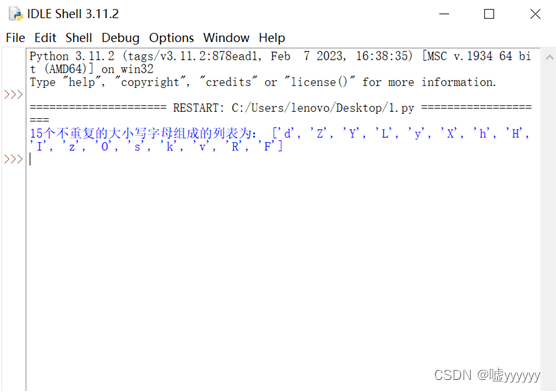
2.编写程序,生成一个由15个不重复的大小写字母组成的列表。
import random
import string
list = []
while len(list) <= 15:
a = random.choice(string.ascii_letters)
if a not in list:
list.append(a)
print("15个不重复的大小写字母组成的列表为:",list)
3.给定字符串"site sea suede sweet see kase sse ssee loses",匹配出所有以s开头、e结尾的单词。
import re
a = 'site sea suede sweet see kase sse ssee loses'
b = re.findall(r's[^0-9]e',a)
print("所有以s开头,e结尾的单词为:",b)

4.生成15个包括10个字符的随机密码,密码中的字符只能由大小写字母、数字和特殊字符“@”“$”“#”“&”“_”“~”构成。
import string
import random
a = string.ascii_letters + string.digits + "@$#&_~"
for i in range(15):
b = "".join([random.choice(a) for i in range(10)])
print("随机密码"+str(i+1)+":",end=" ")
print(b,end=" ")
print()

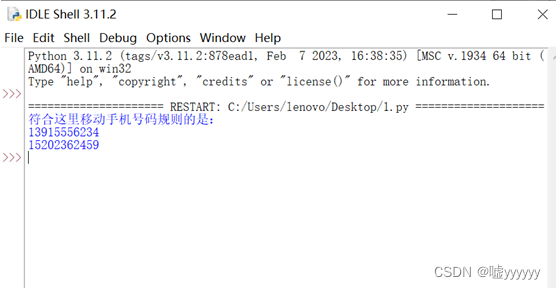
5.给定列表x=[“13915556234”,“13025621456”,“15325645124”,“15202362459”],检查列表中的元素是否为移动手机号码,这里移动手机号码的规则是:手机号码共11位数字;以13开头,后面跟4、5、6、7、8、9中的某一个;或者以15开头,后面跟0、1、2、8、9中的某一个。
import re
x=["13915556234", "13025621456", "15325645124", "15202362459"]
a=r'^(13[4-9]\d{8})|(15[01289]\d{8})$'
print("符合这里移动手机号码规则的是:")
for i in x:
if re.findall(a,i):
print(i)
【实验总结】
1.字符串编码
(1)Python3支持两种类型字符串:str类型(支持Unicode编码)和bytes类型,而且str类型和bytes类型可以相互转换。
(2)通过help(str),发现str类里有一个encode()方法。str类型的字符串可以通过该方法编码成为bytes类型的字符串。通过help(bytes),发现bytes类恰好有个decode()方法。bytes类型的字符串可以通过该方法解码成为str类型的字符串。另外,我们还会发现str类和bytes类拥有几乎一模一样的方法列表,除了encode()和decode()。
(3)可以使用bytes(string, encoding[, errors]) 和str(bytes_or_buffer[, encoding[, errors]])完成两种类型的相互转换。
(4)Python3.x完全支持中文字符,解析器默认采用 UTF-8解析源程序,无论是数字字符、英文字母、汉字都按一个字符来对待和处理。
(5)在Python3.x中可以使用中文作为标识符。
2. 字符串构造
(1)单引号或双引号构造字符串
在用单引号或双引号构造字符串时,要求引号成对出现。
如:‘Python World!’、‘ABC’、“what is your name?”,都是构造字符串的方法。
‘string"在Python中不是一个合法的字符串。
(2)单双引号构造字符串的特殊用法
如果代码中的字符串包含了单引号,且不用转义字符,那么整个字符串就要用双引号来构造,否则就会出错。
如果代码中的字符串包含了双引号,且不用转义字符,那么整个字符串要用单引号来构造。
(3)字符串中引号的转义
转义字符以“\”开头,后接某些特定的字符或数字。
(4)三重引号字符串
三重引号字符串是一种特殊的用法。三重引号将保留所有字符串的格式信息。如字符串跨越多行,行与行之间的回车符、引号、制表符或者其他任何信息,都将保存下来。在三重引号中可以自由的使用单引号和双引号。
3. 字符串格式化
(1)%符号格式化字符串
字符串格式化涉及到两个概念:格式和格式化,其中格式以%开头,格式化运算符用%表示用对象代替格式串中的格式,最终得到1个字符串。
① 字符串格式的书写
[ ]中的内容可以省略;
简单的格式是%加格式字符,如%f、%d、%c等;
当最小宽度及精度都出现时,它们之间不能有空格,格式字符和其他选项之间也不能有空格,如%8.2f。
②最小宽度和精度
最小宽度是转换后的值所保留的最小字符个数。
精度(对于数字来说)则是结果中应该包含的小数位数。
③进位制和科学计数法
把一个数转换成不同的进位制,也可按科学计数法进行转换。
(2)format()方法格式化字符串
format()方法是通过{}和:来代替传统%方式。
format方法格式化时,可以使用位置参数,根据位置来传递参数;也可以通过索引值来引用位置参数,只要format方法相应位置上有参数值即可,参数索引从0开始;也可以使用序列,通过format方法中序列参数的位置索引和序列中元素索引来引用相应值;也可以用“*序列名称”的形式作为format方法的参数,通过位置依次将序列中的元素传递到目标字符串中。
可以使用关键参数的形式,也可用“**字典名”的形式将字典中的元素作为参数。
(3)Formatted String Literals格式化字符串
带’f’前缀,类似于format()方法格式化字符串。
4. 字符串截取
字符串的截取就是取出字符串中的子串。截取有两种方法:一种是索引str[index]取出单个字符;另一种是切片str[[start]:[end]:[step]]取出一片字符。切片方式与列表部分介绍的一样。
字符串中字符的索引跟列表一样,可以双向索引。
5. 字符串常用方法
(1)center()、ljust()、rjust()
格式:
center(self, width, fillchar=’ ‘, /)
ljust(self, width, fillchar=’ ‘, /)
rjust(self, width, fillchar=’ ', /)
说明:
width:指定宽度;
fillchar:填充的字符,默认为空格。
功能:
返回一个宽度为width的新字符串,原字符串居中(左对齐或右对齐)出现在新字符串中,如果width大于字符串长度,则使用fillchar进行填充。
(2)lower()、upper()
lower()方法将大写字母转换为小写字母,其他字符不变,并返回新字符串。upper()方法将小写字母转换为大写字母,其他字符不变,并返回新字符串。经常用这两种方法解决有关不区分大小写问题。
(3)capitalize()、title()、swapcase()
capitalize()方法将字符串首字母转换为大写形式,其他字母转换为小写形式。title()方法将每个单词的首字母转换为大写形式,其他部分的字母转换为小写形式。swapcase()字符将大小写互换。均返回新字符串,原字符串对象不做任何修改。
(4)islower()、isupper()、isdigit()
功能:测试字符串是否为小写、大写、数字。如果是,则返回True;否则返回False。
(5)find()、rfind()
格式:
S.find(sub[, start[, end]])
S.rfind(sub[, start[, end]])
说明:
sub:字符串(子串);
start:开始位置;
end:结束位置。查找范围start开始,end结束,不包括end。
功能:
在一个较长的字符串S中,在[start,end)范围内查找并返回子串sub首次出现的位置索引,如果没有找到则返回-1。默认范围是整个字符串。其中find()方法从左往右查找,rfind()方法从右往左查找。
(6)index()、rindex()
格式:
S.index(sub[, start[, end]])
S.rindex(sub[, start[, end]])
功能:
在一个较长的字符串S中,查找并返回在[start,end)范围内子串sub首次出现的位置索引,如果不存在则抛出异常。默认范围是整个字符串。其中index()方法从左往右查找,rindex()方法从右往左查找。
(7)count()
格式:S.count(sub[, start[, end]])
功能:在一个较长的字符串S中,查找并返回[start,end)范围内子串sub出现的次数,如果不存在则返回0。默认范围是整个字符串。
(8)split()
功能:以指定字符为分隔符,从左往右将字符串分割开来,并将分割后的结果组成列表返回。
如果字符串中的某种字符出现0次或多次,可以利用split()方法,根据该字符把字符串分离成多个子串组成的列表。
(9)join()
join()方法可用来连接序列中的元素,并在两个元素之间插入指定字符,返回一个字符串。
(10)replace()
replace(old,new,count=-1)方法查找字符串中old子串并用new子串来替换。参数count默认值为-1,表示替换所有匹配项,否则最多替换count次。返回替换后的新字符串。
(11)maketrans()、translate()
maketrans()方法生成字符映射表,translate()方法是根据字符映射表替换字符。这两种方法联合起来使用可以一次替换多个字符。
(12)strip()
strip()方法去除字符串两侧的空白字符或指定字符,并返回新字符串。
6. 字符串string模块
字符串string模块定义了Formatter类、Template类、capwords函数和常量,熟悉string模块可以简化某些字符串的操作。
7.正则表达式
正则表达式是一个特殊的字符序列,利用事先定义好的一些特定字符以及它们的组合组成一个“规则”,检查一个字符串是否与这种规则匹配来实现对字符的过滤或匹配。正则表达式是字符串处理的有力工具,但是并不是Python独有的,其他语言也有。
Python中,re模块提供了正则表达式操作所需要的功能。
大多数字母和字符一般都会和自身匹配。如果在字符串前面加了r,表示对字符串不进行转义。有些字符比较特殊,它们和自身并不匹配,而是表明应和一些特殊的东西匹配,或者会影响重复次数。这些特殊的字符我们称之为元字符。
re模块中findall()方法以列表的形式返回所有能匹配的子串,如果没有找到匹配的,则返回空列表。
正则表达式元字符:
① “.”:表示除换行符以外的任意字符
与“.”类似(但不相同)的一个符号是“\S”,表示不是空白符的任意字符。注意是大写字符S。
②“[]”:指定字符集
常用来指定一个字符集,例如:[abc]、[a-z]、[0-9];
元字符在方括号中不起作用,例如:[akm$]和[m.]中元字符都不起作用;
方括号内的“^”表示补集,匹配不在区间范围内的字符,例如:[^3]表示除3以外的字符。
③“^”:匹配行首,匹配以^后面的字符开头的字符串
④“$”:匹配行尾,匹配以$之前的字符结束的字符串
⑤“\”:反斜杠后面可以加不同的字符以表示不同的特殊意义
\b匹配单词头或单词尾;
\B与\b相反,匹配非单词头或单词尾;
\d匹配任何十进制数;相当于[0-9];
\D与\d相反,匹配任何非数字字符,相当于[^0-9];
\s匹配任何空白字符,相当于[\t\n\r\f\v];
\S与\s相反,匹配任何非空白字符,相当于[^\t\n\r\f\v];
\w匹配任何字母、数字或下画线字符,相当于[a-zA-Z0-9_];
\W与\w相反,匹配任何非字母、数字和下画线字符,相当于[^a-zA-Z0-9_];
也可以用于取消所有的元字符:\、[。
这些特殊字符都可以包含在[]中。如:[\s,.]将匹配任何空白字符、“,“或”.”。
⑥“”:匹配位于之前的字符或子模式的0次或多次出现
⑦“+”:匹配位于+之前的字符或子模式的1次或多次出现
⑧“?”:匹配位于?之前的0个或1个字符
⑨“{m,n}”:表示至少有m个重复,至多有n个重复。m,n均为十进制数
忽略m表示0个重复,忽略n表示无穷多个重复。
{0,}等同于*;{1,}等同于+;{0,1}与?相同。但是如果可以的话,最好使用*、+、或?。















 1637
1637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









