







文章目录
- 进程线程相关
- open-jdk
- JVM
- 框架
- 通讯协议
- tcp为什么不二次握手就建立连接?
- 其他
- hash冲突如何解决?
- HTTP get请求可以带请求体么?
- 死锁
- spring如果一个@transation声明的事务调用另外一个没声明@transation事务能回滚么? todo
- 并发和并行
面试过程中遇到了很多问题,之前看了源码,但并未带着问题去看.现在开始带着问题去看源码.里面有一些问题是自己提问的.另外涉及到源码的都附了源码解析链接(不错,是我写的).
KO!!! 感觉就像使用费曼学习法一样,每次面试都能提高自己.
进程线程相关
进程,线程,迁程,协程,用户线程,内核线程还有轻量级线程区的区别是啥?为啥轻量级?



windows才有线程概念,linux是没有的,因为进程就能工作很好,后来为了迎合大众口味,研发出了轻量级进程(可以理解为线程).
进程,分配资源的.
线程,独立运行和调度的
迁程,比线程更小.
协程是啥?
- 协程全称为协同程序,又称作微线程。它与多线程情况下的线程比较类似。协程有自己的堆栈、局部变量和指令指针,通过,多个协程共享全局变量等很多信息。其思想是,一系列相互依赖的协程依次使用CPU,每次只有一个协程运行,其他协程处于休眠状态。协程实际上是在一个线程当中,每个协程对CPU进行分时访问。
线程和协程的主要区别:
- 在多处理器的情况下,多线程程序可以同时运行多个线程;而协同程序需要通过协作来完成,在任一时刻只有一个协同程序在运行。
进程状态模型
二状态进程模型

五状态进程模型

多道和单道程序系统中,进程分别是啥? todo
线程间通信机制有哪些?
-
共享内存
在java中使用这种机制进行线程通信,所以在使用起来会应用到锁机制,或者CAS自旋机制 -
消息传递
-
使用事件对象通信
Windows环境下32位汇编语言程序设计(罗云彬)

进程之间通信
管道
ps -aux | grep XXX
有名管道 (namedpipe)
消息队列
共享内存
信号量
信号
跨机房通信
RPC,HTTP,TCP,webService
open-jdk
ThreadLocal
ThreadLocal内部实现?
threadLocal获取当前线程的ThreadMap,然后将this和value存储在此.
为何存在内存泄漏问题?

内存泄漏的根本原因是强引用和弱引用的生命周期不一致造成的.ThreadLocal作为一个虚引用的key,当被GC回收时,但是value,被当前线程的ThreadLocalMap持有,只要当前线程不销毁,或者没调用get/set方法(调用get/set时,会清除null为key的数据),就一直持有
最严重的的情况是使用了线程池或者静态声明ThreadLocal,大大延长了二者的生命周期.没能及时回收null数据,所以内存泄漏咯

ArrayList
并发修改抛出异常?
当采用迭代器遍历的时候,利用mod和迭代器的expectedModCount记录修改次数,根据迭代器和ArrayList的修改次数判断是否并发修改,从而快速失败
HashMap
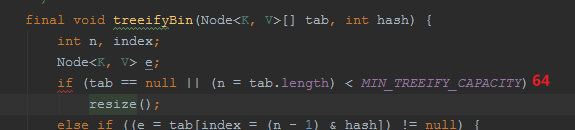
什么时候采用红黑树?
当桶里面存的链表个数>8,同时数组长度>64,的时候采用红黑树
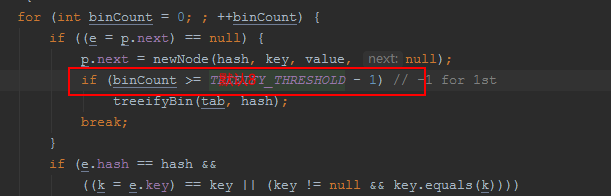
默认加载因子0.75

默认容量16,加载扩容的大小12

key一样时,覆盖旧的value
可以存null,索引0
为什么每次扩容后,是2的幂次方?
是因为在使用2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了实现均匀分布。

为什么扩容后,相同的在原位置保存,而不同的则当前索引+之前原位置索引保存?
//因为这里的扩容都是扩容一倍,也就是01000扩容后变成10000
// 当e.hash & oldCap == 0,说明hash<当前容量,也就是落在0~1000范围内,哪怕扩容后,进行&操作也是一样的索引值
//!=0,则说明第一e.hash落在0~1000范围内,第二包含1000这个位置.而1000是之前扩容前的容量,所以最新的地址为扩容前容量+当前索引
//原位置保存
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//存储索引在扩容的那部分
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
为啥用尾插法?
jdk7因为头插法存在环形问题
而jdk8,使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了
为什么线程不安全?

在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。
hashcode如何计算? TODO
为什么红黑树?平衡二叉树不行么?
红黑树牺牲查找性能,提高了操作删除效率.
AVL树用于自平衡的计算牺牲了插入删除性能,但是因为最多只有一层的高度差,查询效率会高一些。
AVL树比红黑树保持更加严格的平衡。AVL树中从根到最深叶的路径最多为~1.44 lg(n + 2),而在红黑树中最多为~2 lg(n + 1)。
因此,在AVL树中查找通常更快,但这是以更多旋转操作导致更慢的插入和删除为代价的。因此,如果您希望查找次数主导树的更新次数,请使用AVL树。
AVL以及RedBlack树是高度平衡的树数据结构。它们非常相似,真正的区别在于在任何添加/删除操作时完成的旋转操作次数。
两种实现都缩放为a O(lg N),其中N是叶子的数量,但实际上AVL树在查找密集型任务上更快:利用更好的平衡,树遍历平均更短。另一方面,插入和删除方面,AVL树速度较慢:需要更高的旋转次数才能在修改时正确地重新平衡数据结构。
对于通用实现(即先验并不清楚查找是否是操作的主要部分),RedBlack树是首选:它们更容易实现,并且在常见情况下更快 - 无论数据结构如何经常被搜索修改。一个例子,TreeMap而TreeSet在Java中使用一个支持RedBlack树。
HashSet
put的value是PRESENT


LinkedHashMap和HashMap区别?
内部维护一个双向链表,所以访问时,不需要像hashMap一样,遍历索引按照添加顺序访问,效率提升.
遍历的时候,默认按照添加的顺序遍历
当accessOrder为true时,采用LUR算法,最近访问的元素设置到尾部.
其他基于hashMap
ConcurrentHashMap
什么时候扩容?
- 单节点容量>=8且容量<64,则扩容一倍
- 当数组中元素达到了sizeCtl的数量的时候,则会调用transfer方法来进行扩容
没有实现对map进行加锁来执行独占访问,因为采用了分段锁,所以无法使用客户端加锁来创建新的原子操作,如若没有则添加之内操作.
JDK1.8放弃分段锁
段Segment继承了重入锁ReentrantLock,有了锁的功能,每个锁控制的是一段,当每个Segment越来越大时,锁的粒度就变得有些大了。
分段锁的优势在于保证在操作不同段 map 的时候可以并发执行,操作同段 map 的时候,进行锁的竞争和等待。这相对于直接对整个map同步synchronized是有优势的。
缺点在于分成很多段时会比较浪费内存空间(不连续,碎片化); 操作map时竞争同一个分段锁的概率非常小时,分段锁反而会造成更新等操作的长时间等待; 当某个段很大时,分段锁的性能会下降。
jdk1.8的map实现
和hashmap一样,jdk 1.8中ConcurrentHashmap采用的底层数据结构为数组+链表+红黑树的形式。数组可以扩容,链表可以转化为红黑树。
为什么不用ReentrantLock而用synchronized ?
减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。
多个线程又是如何同步处理的呢?
- 同步处理主要是通过Synchronized和unsafe两种方式来完成的。
- 在取得sizeCtl、某个位置的Node的时候,使用的都是unsafe的方法,来达到并发安全的目的
当需要在某个位置设置节点的时候,则会通过Synchronized的同步机制来锁定该位置的节点。 - 在数组扩容的时候,则通过处理的步长和fwd节点来达到并发安全的目的,通过设置hash值为MOVED
- 当把某个位置的节点复制到扩张后的table的时候,也通过Synchronized的同步机制来保证现程安全
ThreadPoolExecutor
执行过程
- 当前工作线程个数<核心大小添加新线程工作
- 核心池都在运行状态,添加到队列中
- 核心池没处于运行状态或者队列已满,试着创建线程最大线程数新开一个新线程处理
- 如果创建新线程失败了,说明线程池被关闭或者线程池完全满了,拒绝任务

线程池状态?


线程池何时销毁空闲线程?
当线程任务执行结束,阻塞队列(设置超时则执行poll,超时返回null,没设置则take,一直阻塞获取任务)里面没有任务.会执行后置



Thread
守护线程
坦克大战里面的坦克(守护线程).家(用户线程)都被炸了,坦克也得凉凉.
线程礼让,yield
运行到一半的线程能否被强制杀死?
答案是不能,虽然我们可以用stop(),destroy()这些函数强制杀死他,但是这些函数,官方不建议使用,强势杀死线程会导致线程中所用的资源,例如文件描述符,网络连接以及持有的同步锁等不能正常关闭。
关闭线程的合理的方法是什么?
等待线程执行完毕
如果是不断循环运行的线程,需要利用线程间通信机制,通知线程退出
线程状态切换
六状态线程模型

注意,当线程wait时,操作系统层面线程waiting状态,jvm层面不会变化,依旧runnable状态.
RUNNABLE 可运行状态 是操作系统中就绪状态和运行状态 (这里找到官方描述:处于 runnable 状态下的线程正在 Java 虚拟机中执行,但它可能正在等待来自于操作系统的其它资源,比如处理器。 )
在java中,runnable将ready和running二种状态合并在一起,BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分
- wait/nofity 是通过JVM里的 park/unpark
机制来实现的,在Linux下这种机制又是通过pthread_cond_wait/pthread_cond_signal 来实现的;当线程进入到wait状态的时候其实是会放弃cpu的,也就是说这类线程是不会占用cpu资源。 - notify()或者notifyAll()调用时并不会真正释放对象锁, 必须等到synchronized方法或者语法块执行完才真正释放锁.
JVM
为啥8:1:1
GC是统计学测算出当内存使用超过98%以上时,内存就应该被minor gc时回收一次。但是实际应用中,我们不能较真的只给 他们留下2%,换句话说当内存使用达到98%时才GC 就有点晚了,应该是多一些预留10%内存空间,这预留下来的空间我们称为S区(有两个s区 s1 和 s0),S区是用来存储新生代GC后存活下来的对象,而我们知道新生代GC算法使用的是复制回收算法。
所以我们实际GC发生是在,新生代内存使用达到90%时开始进行,复制存活的对象到S1区,要知道GC结束后在S1区活下来的对象,需要放回给S0区,也就是对调(对调是指,两个S区位置互换,意味着再一次minor gc 时的区域 是eden 加,上一次存活的对象放入的S区),既然能对调,其实就是两个区域一般大。这也是为什么会再有个10%的S0区域出来。这样比例就是8:1:1了!!(80%:s1:s0=80%:10%:10%=8:1:1)这里的eden区(80%) 和其中的一个 S区(10%) 合起来共占据90%,GC就是清理的他们,始终保持着其中一个 S 区是空留的,保证GC的时候复制存活的对象有个存储的地方。
收集器区别
串行收集器:单线程执行,适合单核CPU
并行收集器:吞吐量回收器,并行执行年轻代垃圾回收,多条垃圾收集器并行工作,此时用户线程依然处于等待状态.适用于多核处理器或多线程硬件上运行数据量较大应用
并发收集器:并发回收,缩短垃圾回收暂停时间,适用响应时间>吞吐时间应用,用户线程与垃圾收集线程同时执行,但不一定并行,可能交替,但会降低应用程序性能
CMS收集器:并发标记清除收集器,适用于缩短垃圾回收暂停时间并且负担得起与垃圾回收共享处理器资源的应用(JDK7默认)
G1收集器:适用于大容量内存的多核服务器,可以满足垃圾回收暂停时间目标的同时,以最大可能性实现高吞吐,(JDK1.7引入,JDK9默认)
CMS/G1以及其他收集器执行流程
如何选择垃圾回收器
数据量小,或者运行单核且没有暂停时间要求,串行收集器Serial
考虑系统峰值性能,没有暂停时间要求,并行 Parallel
响应时间>吞吐,并发 ZGC,CMS,G1
判断对象是否存活常用算法
判断对象是否存活常用算法
引用计数算法:给对象添加一个引用计数器,每当有一个地方引用它时,计数器值+1,当引用失效时,计数器值-1.
任何时刻计数器都为0的对象就是不可能在被使用。
效率高,但很难解决对象之间的相互循环引用的问题
根搜索算法
通过一系列名为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链
当一个对象到GC Roots没有任何引用链相连(用图论的话来说就是从GC Roots到这个对象不可达)时,
则证明此对象是不可用的,
java语言中,作为GC Roots的对象包括下面几种
1:虚拟机栈(栈帧中的本地变量表)中的引用的对象
2:方法去中的类静态属性引用的对象
3:方法区中的常量引用的对象
4:本地方法栈中jni(即一般说的native方法)的引用的对象
5所有被同步锁(synchronized关键字)持有的对象。
6:·反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
垃圾回收算法
点击这里具体描述
标记清除
标记复制
标记整理
分代收集算法
内存模型

为什么程序计数器,栈和本地方法栈是线程独有的?
程序计数器记录的是下一个指令所在地址,用于恢复程序逻辑跳转,这个是跟程序绑定的,也就是某个执行进程,所以线程独有
方法栈,因为生命周期比较短,方法执行结束就销毁,所以线程执行完就over了,也就不需要存储如栈,常量池里面了.
方法区,常量池,和堆线程共享?
常量池存储的是常量,生命周期比较长
方法区记录了类的信息,接口,方法,静态变量,成员变量的信息这些信息才能确定如何执行方法,和获取字段信息,这个类不会只被一个线程获取信息,所以共享咯
堆存储的是具体的对象,只要谁具有引用,谁就可以调用.所以与线程无关.
内存分配执行过程
XX:+PrintGCDetails -verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:SurvivorRatio=8 -XX:+UseSerialGC
-Xms20M -Xmx20M:限制堆大小20M
-Xmn10M :分配给新生代,剩余的10M分配给老年代
-XX:SurvivorRatio=8:决定了新生代中的Eden区与Survivor区的空间比例时8:1
-XX:+UseSerialGC:使用Serial+Serial Old的收集器组合进行内存回收
存储对象时,先存储到Eden+Survivor中,也就是容量9/10*10M,存储容量超过Eden+Survivor,进行一次Minor GC,
将对象存储另外一个Survivor中,如果存储成功对象年龄设为1,对象在Survivor区中每熬过一次Minor GC,年龄增加一岁,当他的年龄达到一定程度(默认15),晋升到老年代。
无法完全放入Survivor区,就会向老年代借用内存存放对象,以完成Minor GC,在触发Minor GC时,虚拟机会先检测之前晋升到老年代内存的平均大小是否大于老年代的剩余内存,如果大于,则将Minor GC变为一次Full GC,如果小于,则查看虚拟机是否允许担保失败
如果允许担保失败则Minor GC,否则Full GC
volatile
实现原理

之所以无法保证安全,是因为在累加阶段,如果有另外一个线程获取数据,执行了操作,然后更新内存时,会覆盖.

可见当添加了volatile,反汇编后多了一个lock指令,这个指令就是用来内存屏障的,防止指令重排序.
synchronized


实现原理


Java虚拟机的指令集中有monitorenter和monitorexit两条指令来支持synchronized关键字的语义
关于这两条指令的作用,参考JVM规范中描述:
monitorenter :
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows:
• If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor.
• If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count.
• If another thread already owns the monitor associated with objectref, the thread blocks until the monitor’s entry count is zero, then tries again to gain ownership.
这段话的大概意思为:
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
- 如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
- 如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
- 如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
monitorexit:
The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref.
The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.
这段话的大概意思为:
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
当在方法声明上加入synchronized,虚拟机可以从方法常量池中的方法表结构中的ACC_SYNCHRONIZED访问标志得知一个方法是否被声明为
同步方法。


JVM就是根据该标示符来实现方法的同步的:当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。 其实本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。
CAS底层代码实现? 超详细,深入汇编
首先分析java原子自增怎么实现的

可见是基于Unsafe类实现的.


发现compareAndSwapInt是本地方法.

找到unsafe.cpp,然后发现compareAndSwapInt对应的实现在Unsafe_CompareAndSwapInt


这个cmpxchg基于系统的实现,有很多.

我就随便找一个linux的看看

ABA问题
执行CAS时,假设A查询库存为N,在将N修改为M途中,有B线程修改了N为M,C线程修改M为N,这个时候A利用下列SQL执行依旧会成功,因为N没有改变,但是实际上N改变了
update store set num=$num_new where id=$id and num=$num_old
针对这个问题添加一个版本号就行了
update store set num=$num_new where id=$id and version=$version
java原子类也会遇到这个问题,AtomicStampedReference添加了对版本号的支持
synchronized和cas适用场景?
资源竞争频繁用sync,否则cas.
因为sync进行线程阻塞和唤醒时,会切换到内核模式,以及消耗额外CPU
而CAS基于硬件CPU指令集实现,不需要进入内核,不需要切换线程,操作自旋几率较少,可以获得更好的性能
对于资源竞争严重的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源
synchronized在jdk1.6之后,依靠 Lock-Free,基本思路是自旋后阻塞,在线程冲突较少的情况下,可以获得和CAS类似的性能,而线程冲突严重的情况下,性能远高于CAS
ReentrantLock和synchronized 的区别?
相似点
- 加锁
- 等待
- 唤醒
- 可重入
性能比较
- sync1.6后进行了优化,借助CAS思想,性能已经不逊色于ReentrantLock
使用简便性
- sync操作简单,不需要手动释放.
- ReentrantLock需要,但是正因为此,它可以更细粒度操作.
ReentrantLock独有特性
- 支持公平和非公平获取锁,参考源码解析
- 等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。通过lock.lockInterruptibly()来实现这个机制。
- 锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。参考ArrayBlockingQueue源码解析
加锁到底是为了啥?
为了保护临界资源.也就是解决线程安全问题.
出现线程安全的问题一般是因为主内存和工作内存数据不一致性和重排序导致的.
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提供并行度),(单线程)程序的执行结果不能被改变。
happens-before:如果A happens-before B,那么Java内存模型将向程序员保证——A操作的结果将对B可见,且A的执行顺序排在B之前。

无锁,偏向锁,轻量级锁,重量级锁有什么区别. todo

对象如何访问?
句柄访问

直接访问

java5种引用?
强引用
1:强引用:类似Object obj=new Object()这类引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象
Object strongReference = new Object();
当内存空间不足时,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。
如果强引用对象不使用时,需要弱化从而使GC能够回收,如下:
strongReference = null;
软引用
如果一个对象只具有软引用,则内存空间充足时,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
通过SoftReference实现
Mybatis的SoftCache有具体使用

弱引用
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
通过WeakReference实现

虚引用
也称为幽灵引用或者幻影引用,一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,
也无法通过虚引用来取得一个对象实例
为一个对象设置虚引用关联的唯一目的就是希望能在这个对象被收集器回收时受到一个系统通知
jdk1.2之后,提供了PhantomReference类来实现虚引用
netty的ResourceLeakDetector就是基于此类
FinalReference(jvm管理)
线程模型
内核线程

用户线程

轻量级线程

用户线程与轻量级线程混合模型

IO模型(BIO NIO AIO以及Reactor模型)
直接传输,mmap,零拷贝
直接传输,mmap,零拷贝复制在transferTo()应用
C实现mmap
个人理解如下
- 将数据copy用户空间然后,在将用户空间数据copy到socket,中间需要经历2次cpu读写以及2次DMA读写.
- mmap:通过用户空间数据与内核空间数据共享方式,减少了一次cpu传输,同时当数据传送给socket时,只需要在内核空间执行一次CPU调用就行,相当于减少了一次CPU read.
- 直接通过DMA将带有文件位置和长度信息的缓冲区描述符添加socket缓冲区去,减少了2次CPU调用
- 写时复制:当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中,这样做并不影响其他进程对这块数据的操作,每个进程要修改的时候才会进行拷贝,所以叫写时拷贝。这种方法在某种程度上能够降低系统开销,如果某个进程永远不会对所访问的数据进行更改,那么也就永远不需要拷贝。
类加载器
类加载器:让应用程序自己决定如何去获取所需的类
只有判断类和类加载器是否一样才能判断2个class文件是否相同
什么场景下需要自定义类加载器?
- 类的加载地址来源不定,如网络,其他jar
- 某些情况下需要动态再次加载类,如修改jsp后,tomcat会卸载类加载器然后再次加载jsp.
自定义类加载器时需要注意啥?
防止破坏双亲委派模式,所以一般覆写findClass(name)和findResource()即可,而不是重写loadClass()

双亲委派模式
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加
载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
使用双亲委派模型来组织类加载器之间的关系,一个显而易见的好处就是Java中的类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪一
个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都能够保证是同一个类。反之,如果没有使用双亲委派模型,都由各个类加载器自行去加载的话,如果用户自己也编写了一个名为java.lang.Object的类,并放在程序的ClassPath中,那系统中就会出现多个不同的Object类,Java类型体系中最基础的行为也就无从保证,应用程序将会变得一片混乱
使用场景:
- 热部署
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
//判断此类是否加载
Class<?> c = findLoadedClass(name);
if (c == null) {
//尚未加载
long t0 = System.nanoTime();
try {
if (parent != null) {
//调用父类加载
c = parent.loadClass(name, false);
} else {
//调用启动类加载器加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
//执行这里说明,父类or启动类加载器加载失败
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
//调用本身类加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
框架
spring
spring如何实现标签功能扩展的?
spring在解析doc的时候,会创建一个ReaderContext对象


ReaderContext对象创建的时候,会创建NamespaceHandlerResolver对象

在进行对象解析的时候,会分别解析默认命名空间和自定义的解析,也就是beans标签和非beans标签的解析


/*
获取所有已经配置的handler映射,读取配置文件
根据命名空间找到对应的信息
当是类的时候说明,已经做过解析直接缓存读取,直接返回
没有做过解析,返回类路径
判断handlerClass是否是NamespaceHandler子类
初始化类
调用自定义的namespaceHandler的初始化方法,这个时候注入了解析器
记录在缓存
返回
*/
public NamespaceHandler resolve(String namespaceUri) {
//获取所有已经配置的handler映射,读取配置文件
//和类org.springframework.beans.factory.xml.PluggableSchemaResolver.getSchemaMappings一样,不在阐述
Map<String, Object> handlerMappings = getHandlerMappings();
//根据命名空间找到对应的信息
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
//这个时候还是字符串
else if (handlerOrClassName instanceof NamespaceHandler) {
//已经做过解析,直接缓存读取
return (NamespaceHandler) handlerOrClassName;
}
else {
//没有做过解析,返回类路径
String className = (String) handlerOrClassName;
try {
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
//判断handlerClass是否是NamespaceHandler子类
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
//初始化类
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
//调用自定义的namespaceHandler的初始化方法,这个时候注入了解析器
namespaceHandler.init();
//记录在缓存
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}
catch (ClassNotFoundException ex) {
throw new FatalBeanException("Could not find NamespaceHandler class [" + className +
"] for namespace [" + namespaceUri + "]", ex);
}
catch (LinkageError err) {
throw new FatalBeanException("Unresolvable class definition for NamespaceHandler class [" +
className + "] for namespace [" + namespaceUri + "]", err);
}
}
}
注册命名空间能解析的elementName
public class AopNamespaceHandler extends NamespaceHandlerSupport {
/**
* Register the {@link BeanDefinitionParser BeanDefinitionParsers} for the
* '{@code config}', '{@code spring-configured}', '{@code aspectj-autoproxy}'
* and '{@code scoped-proxy}' tags.
*/
@Override
public void init() {
// In 2.0 XSD as well as in 2.1 XSD.
registerBeanDefinitionParser("config", new ConfigBeanDefinitionParser());
registerBeanDefinitionParser("aspectj-autoproxy", new AspectJAutoProxyBeanDefinitionParser());
registerBeanDefinitionDecorator("scoped-proxy", new ScopedProxyBeanDefinitionDecorator());
// Only in 2.0 XSD: moved to context namespace as of 2.1
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
}
}
接着会读取META-INF/spring.handlers文件配置的命名空间解析器
private Map<String, Object> getHandlerMappings() {
Map<String, Object> handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
if (logger.isTraceEnabled()) {
logger.trace("Loading NamespaceHandler mappings from [" + this.handlerMappingsLocation + "]");
}
try {
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
if (logger.isTraceEnabled()) {
logger.trace("Loaded NamespaceHandler mappings: " + mappings);
}
handlerMappings = new ConcurrentHashMap<>(mappings.size());
CollectionUtils.mergePropertiesIntoMap(mappings, handlerMappings);
this.handlerMappings = handlerMappings;
}
catch (IOException ex) {
throw new IllegalStateException(
"Unable to load NamespaceHandler mappings from location [" + this.handlerMappingsLocation + "]", ex);
}
}
}
}
return handlerMappings;
}

然后根据url获取对应的解析器,然后解析
public BeanDefinition parse(Element element, ParserContext parserContext) {
//寻找解析器并进行解析操作
BeanDefinitionParser parser = findParserForElement(element, parserContext);
//AbstractBeanDefinitionParser.parse
return (parser != null ? parser.parse(element, parserContext) : null);
}
/*
调用自定义的解析器类
对id的支持
对name别名注册的支持
将AbstractBeanDefinition转换为BeanDefinitionHolder并注册
注册别名
子类后续处理
通知监听器,注册完成
*/
public final BeanDefinition parse(Element element, ParserContext parserContext) {
//内部调用了自定义的解析器类
AbstractBeanDefinition definition = parseInternal(element, parserContext);
if (definition != null && !parserContext.isNested()) {
try {
//对id的支持,当没id的时候,使用内部构造名字
String id = resolveId(element, definition, parserContext);
if (!StringUtils.hasText(id)) {
parserContext.getReaderContext().error(
"Id is required for element '" + parserContext.getDelegate().getLocalName(element)
+ "' when used as a top-level tag", element);
}
//对name别名注册的支持
String[] aliases = null;
if (shouldParseNameAsAliases()) {
String name = element.getAttribute(NAME_ATTRIBUTE);
if (StringUtils.hasLength(name)) {
aliases = StringUtils.trimArrayElements(StringUtils.commaDelimitedListToStringArray(name));
}
}
//将AbstractBeanDefinition转换为BeanDefinitionHolder并注册
BeanDefinitionHolder holder = new BeanDefinitionHolder(definition, id, aliases);
//注册别名以及名字,还有BeanDefinition
registerBeanDefinition(holder, parserContext.getRegistry());
if (shouldFireEvents()) {
//需要通知监听器则进行处理
BeanComponentDefinition componentDefinition = new BeanComponentDefinition(holder);
//子类后续处理
postProcessComponentDefinition(componentDefinition);
//通知监听器,注册完成
parserContext.registerComponent(componentDefinition);
}
}
catch (BeanDefinitionStoreException ex) {
String msg = ex.getMessage();
parserContext.getReaderContext().error((msg != null ? msg : ex.toString()), element);
return null;
}
}
return definition;
}
/*
获取自定义标签解析器中的class
若没有获取class,则获取beanClassName
继承父类scope
配置延迟加载
调用自定义的解析方法
*/
protected final AbstractBeanDefinition parseInternal(Element element, ParserContext parserContext) {
//内部构造了GenericBeanDefinition
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();
String parentName = getParentName(element);
if (parentName != null) {
builder.getRawBeanDefinition().setParentName(parentName);
}
//获取自定义标签解析器中的class,此时会调用UserBeanDefinitionParser.getBeanClass
/*
org.example.custom.dtd.UserBeanDefinitionParser.getBeanClass
*/
//调用自定义类获取class对象
Class<?> beanClass = getBeanClass(element);
if (beanClass != null) {
builder.getRawBeanDefinition().setBeanClass(beanClass);
} else {
//若子类没有重写,则尝试子类是否重写了getBeanClassName方法
String beanClassName = getBeanClassName(element);
if (beanClassName != null) {
builder.getRawBeanDefinition().setBeanClassName(beanClassName);
}
}
builder.getRawBeanDefinition().setSource(parserContext.extractSource(element));
BeanDefinition containingBd = parserContext.getContainingBeanDefinition();
//继承父类scope
if (containingBd != null) {
// Inner bean definition must receive same scope as containing bean.
builder.setScope(containingBd.getScope());
}
//配置延迟加载
if (parserContext.isDefaultLazyInit()) {
// Default-lazy-init applies to custom bean definitions as well.
builder.setLazyInit(true);
}
//调用子类重写的方法解析,这里调用了自定义的解析方法
doParse(element, parserContext, builder);
//内部做了loopup-method,replace-method,factory-method覆盖方法的校验
return builder.getBeanDefinition();
}
spring如何解决循环依赖?
创建bean的时候,通过提早暴露一个工厂对象
这样后续填充属性的时候,如果遇到循环依赖会从工厂中获取对象,而因为工厂对象的初始地址是一样的,也就解决了循环依赖问题



BeanFactoryPostProcessors和BeanPostProcessors区别
BeanPostProcessors并不需要马上调用,所以不需要考虑硬编码方式
BeanPostProcessor可以修改实际的bean实例
而BeanFactoryPostProcessors之所以考虑硬编码是因为不仅要实现注册功能,还要实现对后处理器的激活操作,所以需要载入配置中的定义,并进行激活
BeanFactoryPostProcessor作用域容器级,仅仅对容器中的bean进行后置处理,如propertyPlaceholderConfig,继承order可实现排序调用功能
spring加载xml过程
spring加载xml时,2个步骤
第一步
首先验证xml是否正确,会从网络或者本地获取xsd配置文件,也就是META-INF/spring.schemas
第二步解析document获取Definitions
解析默认命名空间和自定义命名空间
自定义的命名空间,会从META-INF/spring.handlers获取命名空间解析器进行解析,这里也是对aop等标签的支持.
spring获取对象过程
这里只有一个重要点就是循环依赖的问题,上述已有解答
spring-aop执行过程(重点)
在xml配置文件中扫描到aop标签的时候,会执行命名空间解析器,对应的根据aop标签注入AnnotationAwareAspectJAutoProxyCreator类,

这个类继承BeanPostProcessor,也就是说会在每次加载bean的时候会执行后置方法postProcessAfterInitialization

进行切点表达式匹配并进行相应增强.

增强的过程中会选择动态代理还是cglib

然后接着就是执行动态代理增强器链或者cglib增强器链
cglib和动态代理区别
动态代理
必须某接口实现,运行期间创建一个接口的实现类
cglib
运行期间生成的代理对象是针对目标类的扩展的子类,底层依赖ASM操作字节码实现,性能比jdk强,不能对声明为final的方法进行代理
spring选择

实现接口,本身是接口,Proxy子类,则默认动态代理
否则cglib,可强制设置使用cglib
字节码层面讲解jdk代理(超详细)
2020年10月20日面试被问到了,好久之前看过.但是不知道咋样形容.本来想随便网上搜索博客看下就行了,但是想到了王阳明说过的"纸上得来终觉浅,绝知此事要躬行".开干.
简单实现接口.
/**
* JDKproxy源码分析
*
* @author WangChao
* @create 2020/10/22 10:04
*/
public class JdkProxyTest {
public static void main(String[] args) {
//用来输出proxy.class,默认在根目录,而不是src目录.
System.getProperties().setProperty("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
InvocationHandler h = new InvocationHandler() {
@Override
public String toString() {
return "hah";
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
System.out.println("你好,动态代理!");
if (method.getName().equals("toString")){
System.out.println( toString());
System.out.println(method.invoke(this,null));;
}
return null;
}
};
Subject o = (Subject) Proxy.newProxyInstance(Subject.class.getClassLoader(), new Class[]{Subject.class},h);
System.out.println(o.getClass()+" "+ Arrays.toString(o.getClass().getInterfaces()));
o.doSomething();
}
}
interface Subject {
default void doSomething() {
System.out.println("exec");
}
}
分析newProxyInstance()源码

目录下查找到$Proxy0.class,通过javap -c $Proxy0.class,看得到实现的代理类继承了Subject接口,这也就是可以转成Subject类型原因.

使用jd-gui反编译查看.
可以看到分别继承了Proxy和Subject

构造传参了一个InvocationHandler,这个是我们写的回调函数.

当执行doSomething,会执行这儿.

然后后面重写的equals,toString,hashCode,全部都是调用的Object实现方法.

为什么要重写的equals,toString,hashCode?
在上图中,可以得出一个结论,这三个方法最终会被InvocationHandler调用,如果InvocationHandler没实现这三个方法,会默认调用Object方法(看下图).在我看来这三方法,也就是使用InvocationHandler与被代理的Subject起到桥接作用.也就是当比较Subject对象和代理对象是否相同时,我们只需要在InvocationHandler中重写比较规则即可.
重写toString()

没重写toString()

动态代理为啥子还要继承Proxy类?
- 定义接口规范,这样就可以直接通过是否有继承Proxy,得知哪些类是代理类了
- 将冗余代码写入Proxy,使用户只需要关注增强方法实现即可.
字节码层面讲解cglib详解
导包
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
案例demo
/**
* CGlib代理测试
*
* @author WangChao
* @create 2020/10/22 11:59
*/
public class CglibTest {
public static void main(String[] args) throws Exception {
System.setProperty(DebuggingClassWriter.DEBUG_LOCATION_PROPERTY, "target/cglib");
UserDao userDao = new UserDao();
//代理对象
//1:生成代理对象的工具类
Enhancer en = new Enhancer();
//2:设置父类
en.setSuperclass(userDao.getClass());
//3:设置回调函数,触发intercept()
en.setCallback(new MethodInterceptor(){
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
System.out.println("开启事务");
Object o2 = method.invoke(userDao, objects);
System.out.println("结束事务");
return o2;
}
});
//4:创建子类并返回
UserDao proxy = (UserDao) en.create();
proxy.save();
}
}
class UserDao {
public void save() {
System.out.println("数据保存");
}
}
运行之后会生成三个源码

查看类继承层次

查看增强类的实现方法

mybatis如何和spring整合?
1:配置SqlSessionFactoryBean,分别配置注入数据源和配置文件(可省略)
2:SqlSessionFactoryBean主要继承了InitializingBean,FactoryBean还有EventListener
InitializingBean:bean初始化bean后会调用afterPropertiesSet用于对bean属性做一些操作,和配置文件自定义init-method一样,只不过执行顺序比init早
FactoryBean:通过getObject获取bean
EventListener:用于事件监听
3:afterPropertiesSet主要解析配置文件配置属性,然后构建sqlSessionFactory
4:getObject返回sqlSessionFactory对象
第二步注入MapperFactoryBean对象,也就是mapper对象
1:配置文件注入2对象,mapperInterface和sqlSessionFactory
2:同样继承自InitializingBean,FactoryBean接口
3:afterPropertiesSet映射文件存在性校验
4:getObject返回通过注入的sqlSessionFactory封装对象返回mapper对象
整合扫描
1:配置MapperScannerConfigurer,并注入扫描包名
2:继承自BeanDefinitionRegistryPostProcessor
实现方法,主要干了2件事
解析占位符
模拟spring容器加载占位符解析处理器
扫描包
设置扫描规则,如扫描那些类,或者不扫描那些类
调用父类扫描获取BeanDefinitionHolders
利用MapperFactoryBean对每个beanDefinitions生成mapper
替换beandinition的class为mapperFactoryBeanClass
替换mapperInterface
为什么不使用二级缓存?
如果仅仅是解决循环依赖问题,二级缓存也可以,但是如果注入的对象实现了AOP,那么注入到其他bean的时候,不是最终的代理对象,而是原始的。通过三级缓存的ObjectFactory才能实现类最终的代理对象。
一级缓存能不能解决循环依赖问题?
可以解决,但是因为初始化完成和未初始化完成的都放在这个map中,拿到的可能是没有完成初始化的,属性都是空的,直接空指针异常。
spring-boot扩展 todo
spring-cloud源码解析 todo
通讯协议
tcp为什么不二次握手就建立连接?
假设C发送给S连接请求分组,S确认应答分组.在确认过程中,如果丢失分组.C将持续等待应答,如果S确认2次握手成功,将直接发送数据分组.而C因为处于等待应答状态,将丢弃数据分组.S在发出分组超时后,将重试.进而产生死锁问题.
已经建立连接,客户端突然崩了?TCP怎么处理?
TCP设有保活计数器,服务端每次接收客户端报文,将重置计数器,通常2小时.当2小时没收到报文,则会发送一个试探报文,间隔75S发送一次,若10次没响应,则关闭连接
为什么连接的时候是三次握手,关闭的时候却是四次挥手?
当服务端接收到FIN,并不会立即关闭socket,因为可能还有其他请求没有处理完,所以只是ACK,我收到消息了.当服务端所有报文发送完毕,才会发送FIN.
直接原因:**半关闭.**当客户端发送关闭请求给服务端时,接收到服务端响应后,客户端会关闭输出缓冲区.这个时候就处于半关闭状态,也就是只能接收到消息,但是无法发送.当服务端处理完自己的事后,发送FIN后,对服务端做出响应.自此关闭连接.
生活中对应的例子就是,打电话.我该说的说完了,我要挂电话了,想问问你还有没有什么要说的,也就是说这个时候我就不说了,听你说.你要是没啥事,或者听你说完,就双方挂断电话.
为什么四次挥手后客户端还需要等待2MSL(最大报文段生存时间)才进行最终关闭?
假设最后ack服务端后,丢失了.服务端将不停重试发送FIN.所以客户端不能立即关闭,也就是说至少需要等到服务端关闭后,才能关闭.从而设置了一个缓冲时间.在2MSL范围内,等待服务端发送FIN,如果没收到,则假设服务端已经正常关闭,从而关闭.如果收到了FIN,则再次等待2MSL.
为什么不三次挥手?
因为服务端在接收到FIN, 往往不会立即返回FIN, 必须等到服务端所有的报文都发送完毕了,才能发FIN。因此先发一个ACK表示已经收到客户端的FIN,延迟一段时间才发FIN。这就造成了四次挥手。
如果是三次挥手会有什么问题?
等于说服务端将ACK和FIN的发送合并为一次挥手,这个时候长时间的延迟可能会导致客户端误以为FIN没有到达客户端,从而让客户端不断的重发FIN。
流量控制? todo
拥塞控制?todo
其他
同步和阻塞关系?
同步和异步关注的是消息通信机制,关注的是结果
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.关注的是过程
同步阻塞
我在手工制作热狗,在制作期间,我不能做其他事
我买了一台制作热狗的机器
同步非阻塞
我用热狗机器制作,在制作期间,我一边玩手机,一边不停地查看热狗机搞好热狗了没有 poll/select
异步阻塞
我去买热狗,老板说还在制作,我走了,临走前我让老板热狗造好后通知我(事件回调).
异步非阻塞
我去买热狗,老板用热狗机器制作,在等他制作期间,我走了,临走前我让老板热狗造好后通知我.而老板在接待下个顾客. epoll
闭锁,计数信号量,栅栏使用场景?
Semaphore(计数器):网关限流
CountDownLatch(闭锁):工作中,将db数据全量到搜索引擎时,采用闭锁达到所有数据同步完成后,检测数据同步成功率.如果成功率低,则再次重试.
栅栏:召唤七龙珠.
栅栏与闭锁区别?
栅栏:所有运动员就绪,才能跑步,在所有运动员到达之前,其他就绪运动员(工作线程)都得等.
闭锁:所有运动员到达终点,才开始颁奖.每个运动员到达后,不需要等待其他运动员,只有手持运动员名单的人(主线程),才需要等待.
信号量和同步锁的区别
锁用来一个资源的线程互斥
信号量用来多个同类资源的多个线程互斥与同步
信号量=1 = 锁
信号量加锁和解锁可能不是同一个线程
而互斥锁绝对同一个线程.
信号量使用场景
spring-cloud 网关限流
RocketMQ客户端异步调用的时候,采用限流

参考异步发送消息
闭锁使用场景
rocketMQ注册所有broker时,通过闭锁同步执行结果
参考broker节点

哪些类用到了unsafe?
concurrentHashMap
原子类
如何选择线程池?
线程池的决策?
1:尽量少用线程,避免上下文切换.
2:尽量多用线程,充分利用CPU性能
对于耗时短的,线程少点,满足并发要求即可,多了容易争抢.
对于耗时长的,分为IO密集型和CPU密集型任务,如果IO密集型,线程多搞一点,否则少搞一点.
对于高并发耗时长的,整体架构考虑,针对IO的,添加缓存.扩大机器内存.针对CPU密集型的,提升CPU计算性能,再就是异步回调.
长文本去重
完整性校验
md5签名
相似性校验
LSH
hash冲突如何解决?
开放定址法
线性探测再散列


二次探测再散列
不是直接累加,而是在表的左右跳跃式探测
1^2,-1 ^ 2 ,2 ^ 2,-2 ^ 2,…,k ^ 2,-k ^ 2 ( k<=m/2 )
伪随机探测再散列
随意设置一组随机数,如1,5,9,7,累加后取模,算出下标
链地址法



CHM是数组+链表+红黑树不列代码了
再哈希法
构建多个hash值,取模存储,直到不出现冲突为止.
建立公共溢出区
建立一个公共溢出区域,就是把冲突的都放在另一个地方,不在表里面。
HTTP get请求可以带请求体么?
可以,而且请求体数据也是可以获取的,HTTP1.1并没有明确规定这样不行.
elasticSearch就是这样的GET带请求体,同时兼容POST
死锁
指定锁顺序解决死锁

TCP死锁
二次握手和三次挥手都会造成死锁,具体看上关于TCP的解答
线程饥饿死锁
单线程情况下,一个任务等待另外2个任务的结果
如果任务之间存在依赖,有界线程池or队列可能导致饥饿死锁。推荐使用无界的线程池newCachedThreadPool

资源分配死锁
分布式场景下,则是因为资源调度不当导致整个调度系统无法继续执行.如资源储备策略就可能造成死锁,作业AB分别需要2/3资源,如果此时此刻AB分别分配了1/2资源,因为无空闲资源分配,资源储备策略又会导致各自保持不释放分配的资源,就会造成死锁问题.

Receive阻塞

分析死锁,活锁
具体请看
打开jconsole

死锁


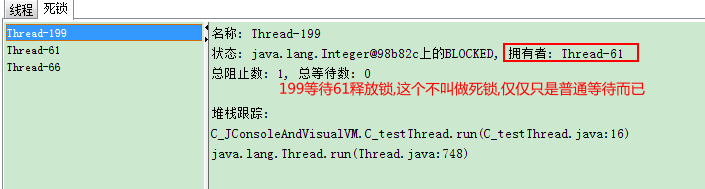
活锁

空循环
可看见线程处于RUNNABLE运行状态,这种情况会一直占用CPU

spring如果一个@transation声明的事务调用另外一个没声明@transation事务能回滚么? todo
并发和并行

并发是两个队列交替使用一台咖啡机
并行是两个队列同时使用两台咖啡机,如果串行,一个队列使用一台咖啡机,那么哪怕前面那个人便秘了去厕所呆半天,后面的人也只能死等着他回来才能去接咖啡,这效率无疑是最低的。
串行是一个队列使用一台咖啡机.















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









