







系列文章目录
第一章 「Java AI实战」LangChain4J接入Xinference本地大模型
第二章 「Java AI实战」LangChain4J - ChatAPI 及常用配置
文章目录
前言
相比 Python 社区的 LangChain,LangChain4J 为 Java 提供了相似的链式语言模型编排能力,兼顾工程化可维护性与复杂场景的灵活性。而在众多场景中,向量数据库(如 FAISS、Milvus、Qdrant)扮演了大模型“记忆体”的角色,尤其适用于构建基于语义理解的问答系统(RAG)、文档检索、智能客服等系统。
一、什么是向量数据库?
1.1. 向量数据库的原理简述
在传统数据库中,检索通常依赖于关键词、精确匹配或范围查询。而在自然语言处理、图像识别等 AI 场景中,我们更需要的是语义相似度检索,即“查找与某个内容在语义上最接近的内容”。这正是向量数据库的核心用途。
✅ 什么是向量?
向量是通过深度学习模型(如 BERT、OpenAI Embedding、CLIP 等)对文本、图片、音频等内容提取出的稠密特征表示。
它通常表现为一个高维浮点数组,例如:
[0.12, -0.08, 0.33, ..., 0.91] // 维度可以是 384、768、1536 等
在语义空间中,相似的内容对应的向量距离会更近,从而实现语义检索。
✅ 向量数据库的核心功能
-
向量存储:存储大量高维向量及其关联元数据(如文档ID、标题、标签等)。
-
相似度搜索:基于欧几里得距离、余弦相似度等方式,快速查找最相近的Top-K向量。
-
近似最近邻(ANN)算法:为提升性能,向量数据库使用 ANN 算法(如 HNSW、IVF)在亿级数据中实现毫秒级搜索。
-
条件过滤:支持结合结构化字段(如类别、时间)进行筛选+向量检索。
✅ 与传统数据库的区别
| 功能点 | 传统数据库 | 向量数据库 |
|---|---|---|
| 检索方式 | 精确匹配 / 范围查询 | 语义相似度(向量Top-K) |
| 数据结构 | 行/列、主键索引 | 高维向量 + 元数据结构 |
| 查询能力 | SQL 查询 | 向量相似度 + 条件过滤 |
| 典型应用场景 | 电商、金融系统 | 搜索推荐、AI检索、RAG场景 |
1.2. 主流向量数据库介绍
| 名称 | 特点 |
|---|---|
| Faiss | Facebook 出品,C++/Python,高性能本地引擎 |
| Milvus | 专业向量数据库,支持多种索引算法,企业级 |
| Weaviate | 云原生,支持 GraphQL 查询和语义增强 |
| Pinecone | 商业化云向量服务,易用性高 |
| Qdrant | Rust 编写,支持嵌入过滤,支持 Docker 快速部署 |
| Chroma | 适合轻量级 RAG 本地场景,支持 LangChain |
1.3. 向量数据库在语义搜索中的价值
向量数据库是语义搜索的核心基础设施,在传统关键词检索中,系统只能根据字面匹配进行查找,难以理解用户的真实意图。
而向量数据库通过将文本等非结构化内容映射为高维语义向量,使得系统能够基于语义相似度进行“意图层”的检索。
这意味着,即使用户输入的查询词与数据库中的文档没有明显的词面重合,系统依然可以通过语义向量的接近程度,返回语义相关度最高的内容。这种能力广泛应用于:
-
问答系统(RAG):基于语义检索找到相关知识片段,提供更可靠的上下文补全。
-
智能搜索框:实现更“懂你”的搜索体验。
-
推荐系统:用向量衡量兴趣相似度,实现个性化推荐。
-
企业知识库检索:提升非结构化文档的可用性和搜索效率。
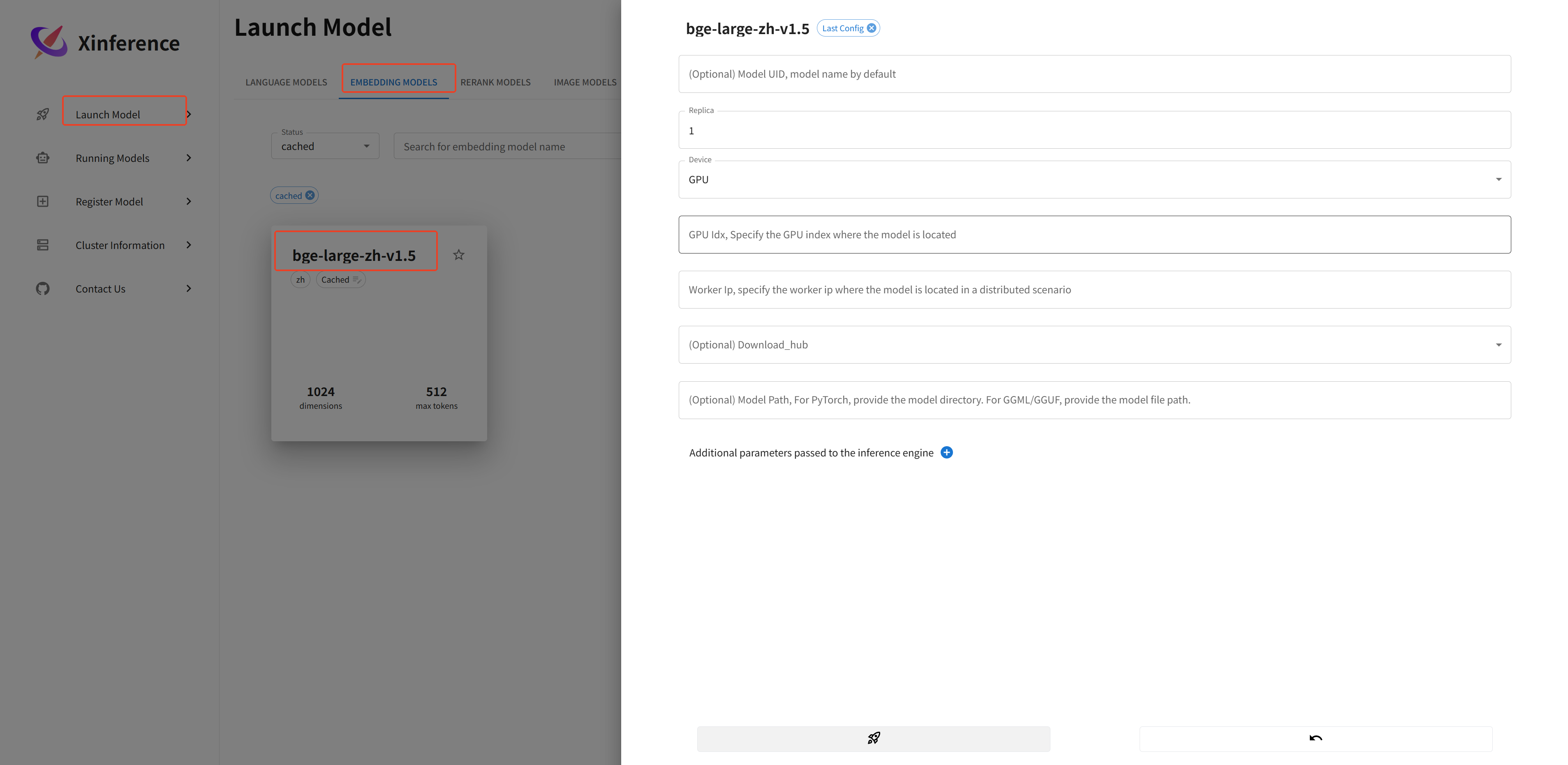
二、Xinference注册向量模型
三、接入Qdrant并实现语义问答
3.1. 项目依赖配置
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<!--qdrant-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
</dependency>
<!--sensitive-word-->
<dependency>
<groupId>com.github.houbb</groupId>
<artifactId>sensitive-word</artifactId>
<version>0.21.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
3.2. Qdrant数据库安装
可以基于docker进行安装:
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
3.3. 注册向量模型和向量数据库
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.qdrant.QdrantEmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.QdrantGrpcClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration(proxyBeanMethods = false)
public class EmbeddingModelConfig {
@Bean
public EmbeddingModel embeddingModel() {
return OpenAiEmbeddingModel.builder()
.apiKey("1")
.modelName("bge-large-zh-v1.5")
.baseUrl("http://192.168.1.13:9997/v1")
.build();
}
@Bean
public QdrantClient qdrantClient() {
QdrantGrpcClient.Builder grpcClientBuilder =
QdrantGrpcClient.newBuilder("127.0.0.1", 6334, false);
return new QdrantClient(grpcClientBuilder.build());
}
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("127.0.0.1")
.port(6334)
.collectionName("test-qdrant")
.build();
}
}
此处注册的模型是直接对接Xinference的向量模型,api_key可以任意填写。指定模型名称和baseUrl即可。
3.4. 问答式语义检索API
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingSearchResult;
import dev.langchain4j.store.embedding.EmbeddingStore;
import io.qdrant.client.QdrantClient;
import io.qdrant.client.grpc.Collections;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import dev.langchain4j.model.embedding.EmbeddingModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import dev.langchain4j.data.embedding.Embedding;
import static dev.langchain4j.store.embedding.filter.MetadataFilterBuilder.metadataKey;
@RestController
@Slf4j
public class EmbeddingController {
@Resource
private EmbeddingModel embeddingModel;
@Resource
private QdrantClient qdrantClient;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
/**
* 文本向量化测试,看看形成向量后的文本
*
*/
@GetMapping(value = "/embedding/embed")
public String embed() {
String prompt = """
咏鸡
鸡鸣破晓光,
红冠映朝阳。
金羽披霞彩,
昂首步高岗。
""";
Response<Embedding> embeddingResponse = embeddingModel.embed(prompt);
System.out.println(embeddingResponse);
return embeddingResponse.content().toString();
}
/**
* 新建向量数据库实例和创建索引:test-qdrant
* 类似mysql create database test-qdrant
*/
@GetMapping(value = "/embedding/createCollection")
public void createCollection() {
var vectorParams = Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine)
.setSize(1024)
.build();
qdrantClient.createCollectionAsync("test-qdrant", vectorParams);
}
/*
往向量数据库新增文本记录
*/
@GetMapping(value = "/embedding/add")
public String add() {
String prompt = """
咏鸡
鸡鸣破晓光,
红冠映朝阳。
金羽披霞彩,
昂首步高岗。
""";
TextSegment segment1 = TextSegment.from(prompt);
segment1.metadata().put("author", "zxl");
segment1.metadata().put("price", "50");
Embedding embedding1 = embeddingModel.embed(segment1).content();
String result = embeddingStore.add(embedding1, segment1);
System.out.println(result);
return result;
}
@GetMapping(value = "/embedding/query1")
public void query1(){
Embedding queryEmbedding = embeddingModel.embed("咏鸡说的是什么").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
System.out.println(searchResult.matches().get(0).embedded().text());
}
@GetMapping(value = "/embedding/query2")
public void query2(){
Embedding queryEmbedding = embeddingModel.embed("咏鸡作者是谁").content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.filter(metadataKey("author").isEqualTo("zxl"))
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
System.out.println(searchResult.matches().get(0).embedded().text());
}
}
总结
LangChain4J为Java开发者打开了大模型生态的一扇窗,特别是在语义搜索与RAG问答场景中,通过接入向量数据库如FAISS或Milvus,可以高效实现文档理解与语义检索功能。本文不仅解析了LangChain4J在向量数据库接入中的架构设计,也通过完整代码案例展示了其在Java后端中的落地方式。未来,随着本地模型与嵌入技术的发展,Java + LangChain4J + 向量数据库将成为企业级AI服务的强有力支撑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









