







系列文章目录
第一章 Xinference 分布式推理框架的部署
第二章 LLaMA Factory 微调框架的部署
第三章 LLaMA Factory 微调框架数据预处理加载
文章目录
前言
在深度学习的浪潮中,预训练大语言模型(Large Language Models, LLMs)逐渐成为各领域的核心工具。然而,由于大规模模型的复杂性和计算资源需求,直接使用这些模型来解决特定任务往往效率低下。微调(Fine-tuning)技术因此成为了模型开发者们的关键手段,通过针对特定任务的数据调整模型的权重,可以大幅提升模型的效果
LLaMA(Large Language Model Meta AI)作为近年来大受欢迎的开源大语言模型,因其性能优异和架构灵活被广泛应用。而为了更高效地利用 LLaMA 及其衍生模型,许多开发者希望能够快速构建一套易用的微调框架,以支持特定场景的模型训练、验证与部署。本文将介绍如何部署 LLaMA Factory 微调框架。
一、LLaMA Factory是什么?
LLaMA Factory 是一款专注于 LLaMA 模型及其衍生版本的轻量级微调框架,旨在帮助开发者快速实现从模型加载到特定任务微调的全流程管理。它结合了主流的大语言模型微调技术,支持高效的参数优化和灵活的任务定制。无论是小规模的实验性项目,还是面向生产环境的大规模模型部署,LLaMA Factory 都能以简单、高效的方式满足不同场景的需求,为开发者释放了 LLaMA 模型的更多潜力。
通过使用 LLaMA Factory,可以轻松完成以下目标:
- 快速上手:一键加载 LLaMA 模型,结合简单的配置快速完成微调流程。
- 资源节约:支持轻量化微调技术,使消费级硬件也能运行大模型任务。
- 任务灵活:支持多种自然语言处理任务的微调,满足不同场景的实际需求。
二、LLaMA Factory 部署
1.环境说明
此处需要在anaconda中创建虚拟环境,python版本推荐3.11,anaconda的安装和使用参考往期文章:第一章 Xinference 分布式推理框架的部署。注意:除了LLaMA Factory源码的下载,下列命令均在虚拟环境中执行。
1.1 硬件要求
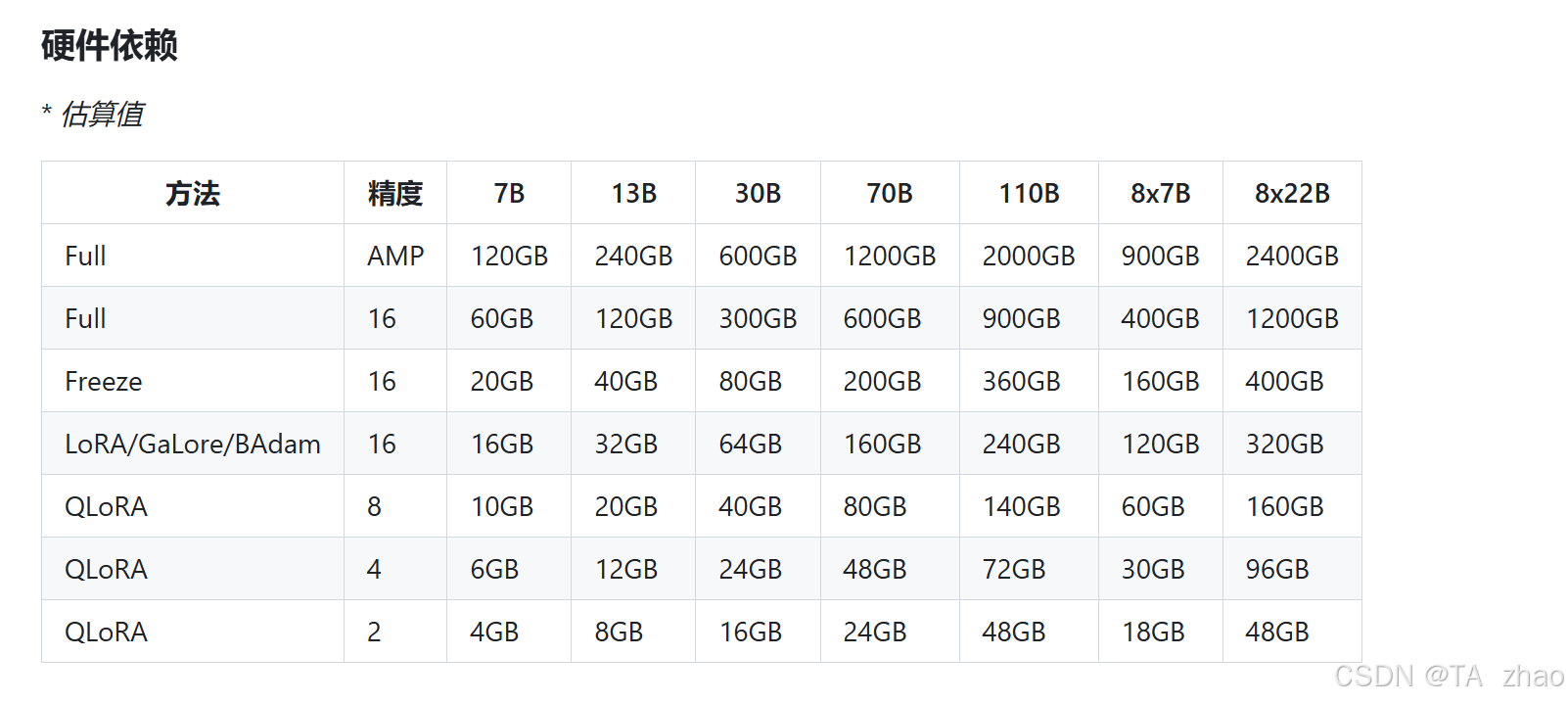
1.2 环境版本推荐
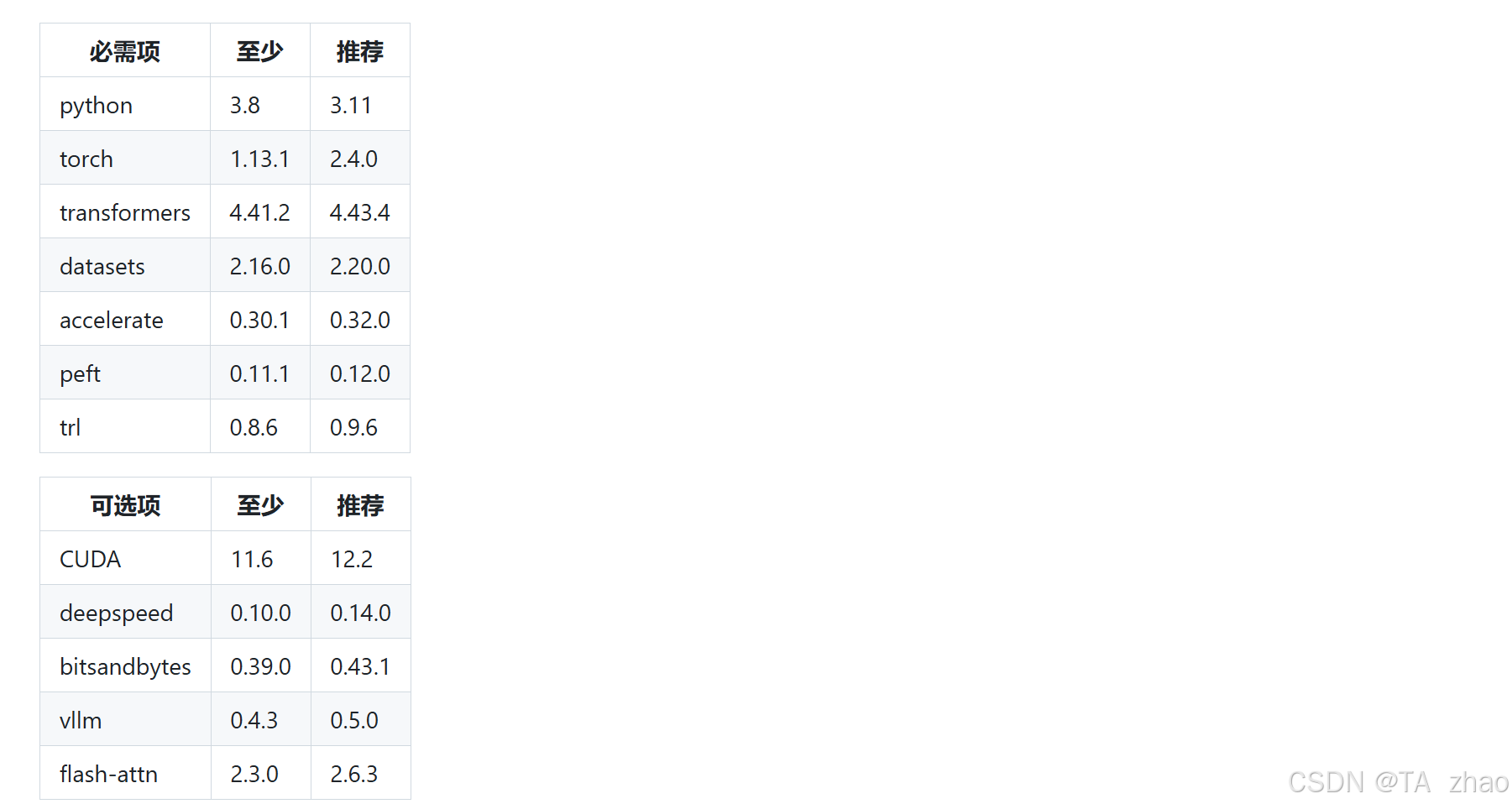
2.部署
2.1 下载git源码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
2.2 安装
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
可选的额外依赖项:torch、torch-npu、metrics、deepspeed、liger-kernel、bitsandbytes、hqq、eetq、gptq、awq、aqlm、vllm、galore、badam、adam-mini、qwen、modelscope、openmind、swanlab、quality。
如果要在 Windows 平台上开启量化 LoRA(QLoRA),需要安装预编译的 bitsandbytes 库, 支持 CUDA 11.1 到 12.2。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
2.3 启动
-- 进入到下载的源码目录,否则自定义数据集和默认数据集无法直接加载进入LLama Factory
cd /d D:\LLaMA-Factory
-- 设置缓存目录,set TRANSFORMERS_CACHE只是为了启动页面去除警告信息
set TRANSFORMERS_CACHE=
set HF_HOME=D:\anaconda3\envs\llama-factory\cache
-- 启动成功后,会自动跳转到浏览器页面
llamafactory-cli webui
跳转成功后,页面如下:
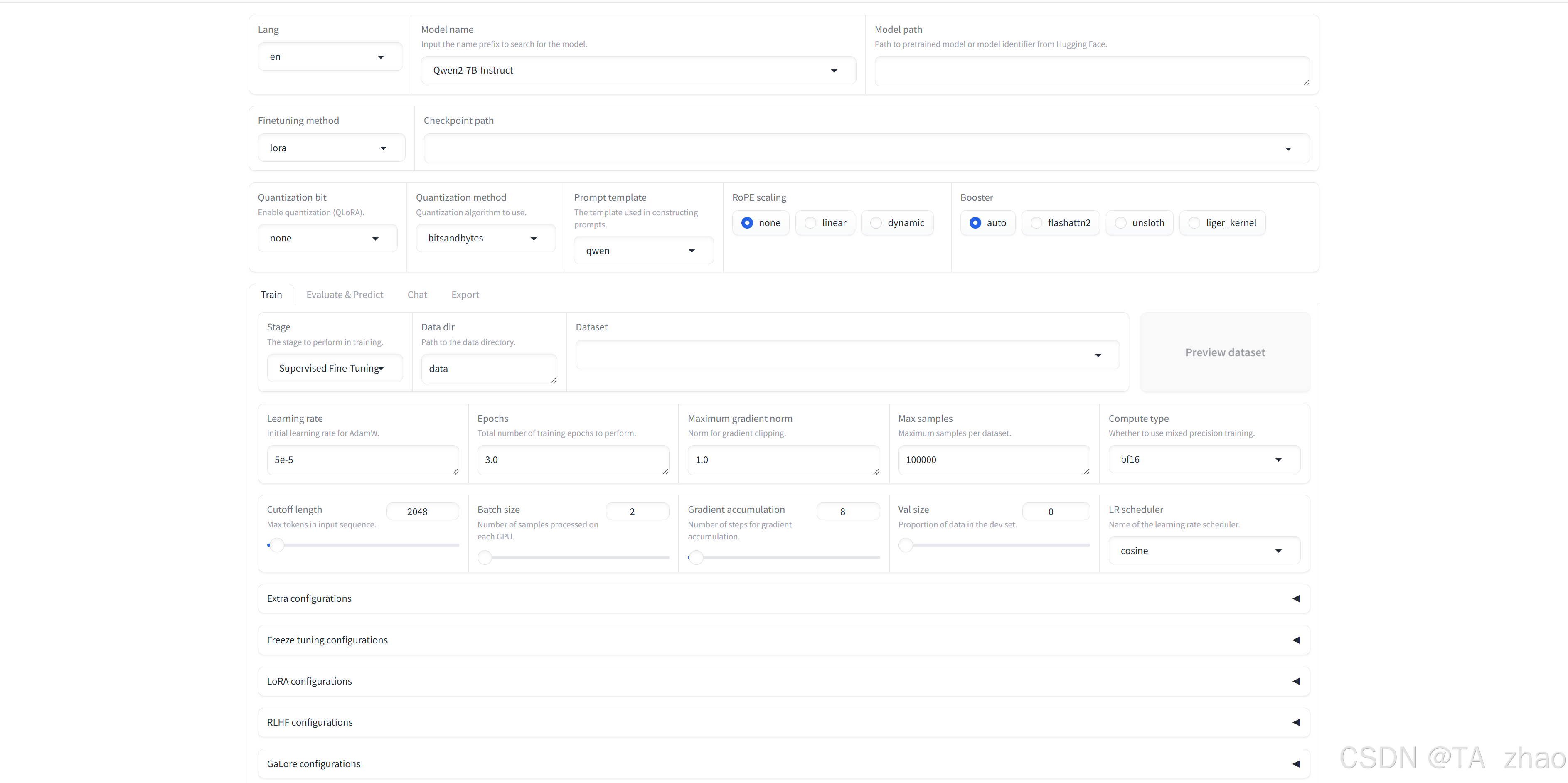
总结
本文仅仅介绍了如何部署 LLaMA Factory 微调框架,下期将会介绍如何使用LLaMA Factory实现数据预处理、微调训练Xinference的本地模型,并最终部署的全流程管理。

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









