







BF,KMP,BM算法详解
1.实验题目
给定一个文本,在该文本中查找并定位任意给定字符串。
2.实验目的
1.深刻理解并掌握蛮力法思想。
2.提高蛮力法设计算法的技能。
3.理解这样一个观点:用蛮力法设计的算法,一般来说,经过适度的努力后,都可以对算法的第一个版本进行一定程度的改良,改进其时间性能。
3.实验要求
实现BF、KMP算法,实现BM算法
4.算法思想与核心代码
(1)BF算法
BF算法其实思路相对简单,总的来说,就是模式串与主串“一对一”匹配,如果匹配失败,子串回溯到头部,并且从模式串的下一个元素开始与子串头匹配。时间复杂度较高,为O(m*n),m为模式串长度,n为主串长度,以下都是。
BF代码
//BF
int BF(const char s[],const char t[])
{
int index=0;
int i=0,j=0;
while(s[i]!='\0'&&t[j]!='\0')
{
if(s[i]==t[j])
{ i++;
j++;}
else
{index++,i=index,j=0;}
}
if(t[j]=='\0')
return index+1;//不是下标
else
return index;
}
(2)KMP算法
KMP算法是相对于BF算法的改进,改进点主要是在主串的遍历上,主串只需遍历一遍,算法的精髓在于求最长相等的前后缀。
首先,需要理解几个概念:
通过举例说明:
字符串 abcdab
前缀的集合:{a,ab,abc,abcd,abcda}
后缀的集合:{b,ab,dab,cdab,bcdab}
最长相等的前后缀:ab
abcabfabcab中最长相等前后缀:abcab
KMP算法就是将已经匹配的串中,找到相等的前缀和后缀,然后将前缀移动到后缀的位置上,如下图: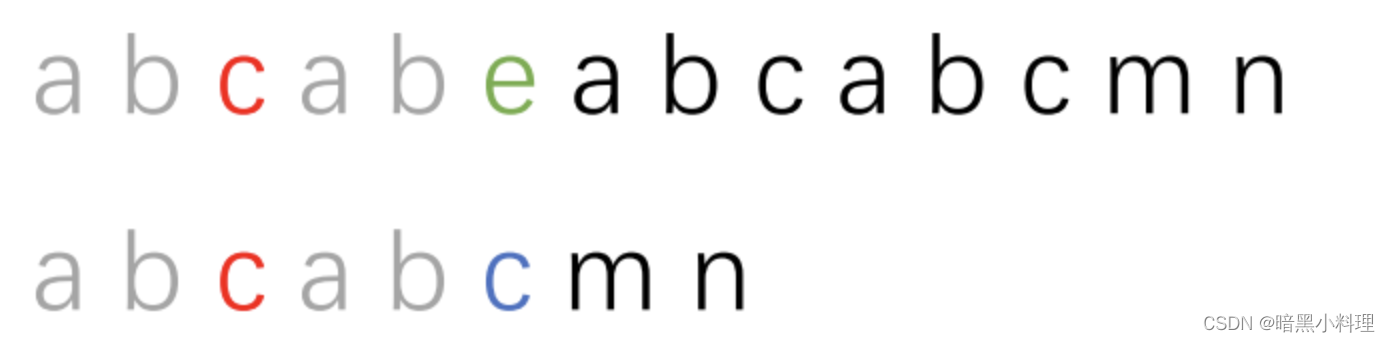
匹配,发现e和c不相等,比较“abcab”中的前后缀,发现有最长相等的前后缀“ab“,直接移动到如下图所示位置:
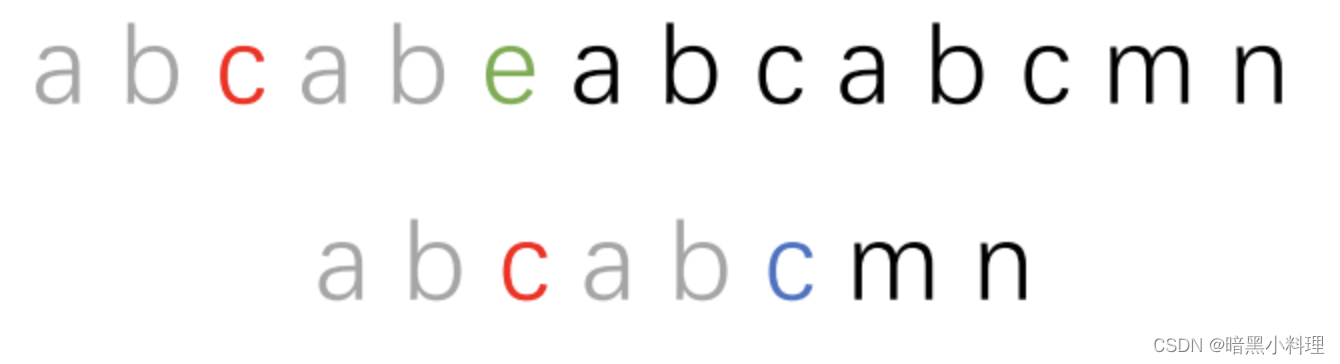
那么我们怎么求最长相等前后缀呢?
用一个next数组来求,next[i]表示前i个元素中最长相等前后缀的长度,若值为-1,则表示不可能出现最长相等前后缀。
例:我们用“ababc"这个字符串来求这个next数组:
当i=0时,因为前0个里面甚至连元素都没有,所以next[0]=-1;
当i=1时,前一个元素无最长相等前后缀,所以next[1]=0;
当i=2时,前两个元素为ab,无最长相等前后缀,next[2]=0;
当i=3时,前三个元素为aba,发现有最长相等前后缀,为“a”,且为一个,则next[3]=1;
当i=4时,前四个元素为abab,发现有最长相等前后嘴,为“ab”,且为两个,则next[4]=2;
注意,最后一个元素不计入next数组的计算范围内。
此时,next数组求解完毕。
求解next数组的代码
//next
void GetNext(int next[],const char t[])//t为模式串
{
int i,j,len;
next[0]=-1;
for(j=1;t[j]!='\0';j++)
{
for(len=j-1;len>=1;len--)//长度肯定要比当前字符串小1个。
{
for(i=0;i<len;i++)
{
if(t[i]!=t[j-len+i])
break;
}
if(i==len)
{
next[j]=len;
break;
}
}
if(len<1)
next[j]=0;
}
}
解决了next数组问题,KMP算法就比较简单了
KMP代码
//KMP
int KMP(const char s[],const char t[])
{
int i=0, j=0;
int next[80];
GetNext(next,t);
while(s[i]!='\0'&&t[j]!='\0')
{
if(s[i]==t[j])
{
i++;
j++;
}
else
{
j=next[j];
if(j==-1)
{
i++;
j++;
}
}
}
if(t[j]=='\0')
return(i-strlen(t)+1);
else
return 0;
}
KMP算法的时间复杂度为O(n),n为主串长度。
(3)BM算法
BM算法其实是对后缀蛮力匹配算法的改进
后缀匹配,是指模式串的比较从右到左,模式串的移动也是从左到右的匹配过程
重点理解两个概念:坏字符,好后缀。
坏字符
-
坏字符规则:当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动坏字符分为两种情况:
1.如果"坏字符"不包含在模式串之中,则最右出现位置为-1,移动的位数 = 坏字符在模式串中的位置 - (-1)
首先,“文本串"与"模式串"头部对齐,从尾部开始比较。”S“与”E“不匹配。这时,”S“就被称为"坏字符”(bad character),即不匹配的字符,它对应着模式串的第6位。且"S“不包含在模式串”EXAMPLE“之中(相当于最右出现位置是-1),这意味着可以把模式串后移6-(-1)=7位,从而直接移到”S"的后一位。
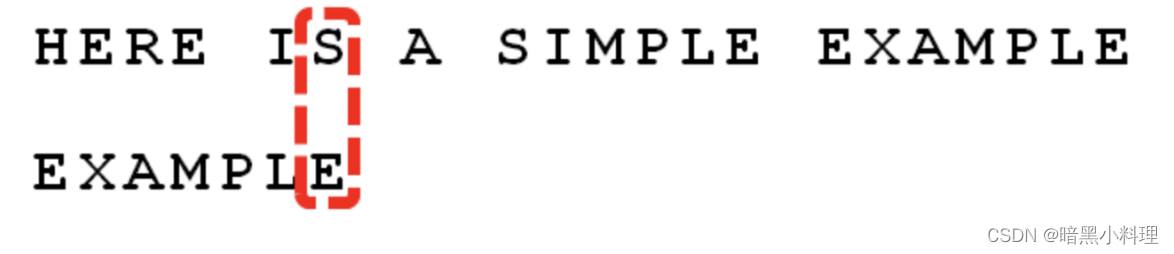
2.如果坏字符包含在模式串中,则移动的位数 = 坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置
从尾部开始比较,发现"P“与”E“不匹配,所以”P“是"坏字符”。但是,"P“包含在模式串”EXAMPLE"之中。因为“P”这个“坏字符”对应着模式串的第6位(从0开始编号),且在模式串中的最右出现位置为4,所以,将模式串后移6-4=2位,两个"P"对齐。

实现坏字符数组代码
void get_badchar(int* badchar, char* t)//t为模式串
{
for(int i=0;i<256;i++)
{
badchar[i]=-1;
}
for(int i=0;i<strlen(t);i++)
{
badchar[t[i]]=i;
}
}
好后缀
即为后缀匹配过程中,匹配成功的子串:
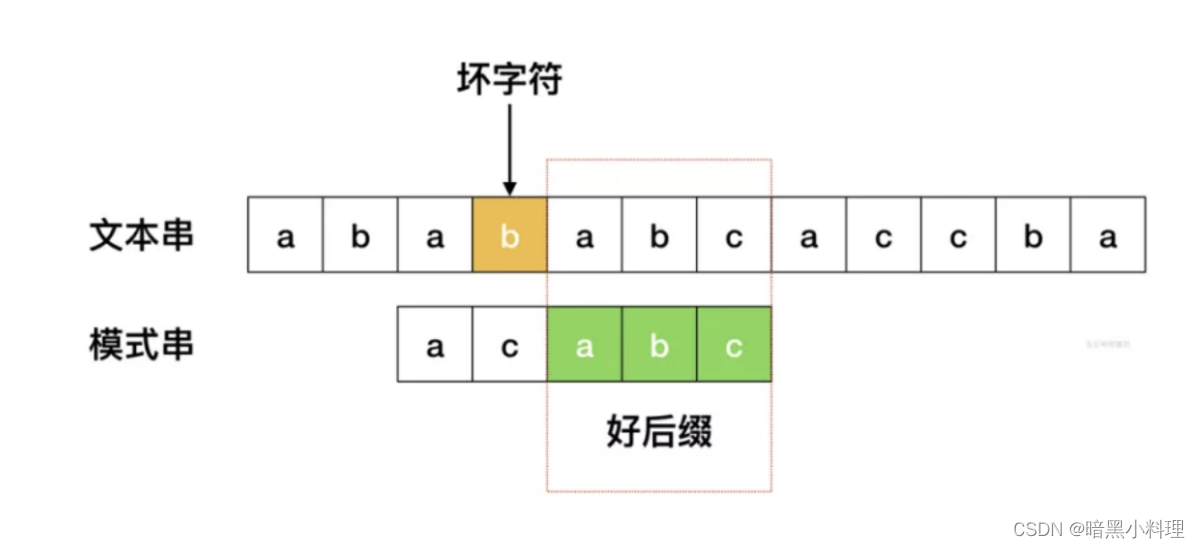
好后缀的匹配,分为三种情况:
1.模式串中有子串匹配上好后缀,此时移动模式串,让该子串和好后缀对齐即可,如果超过一个子串匹配上好后缀,则选择最靠左边的子串对齐。
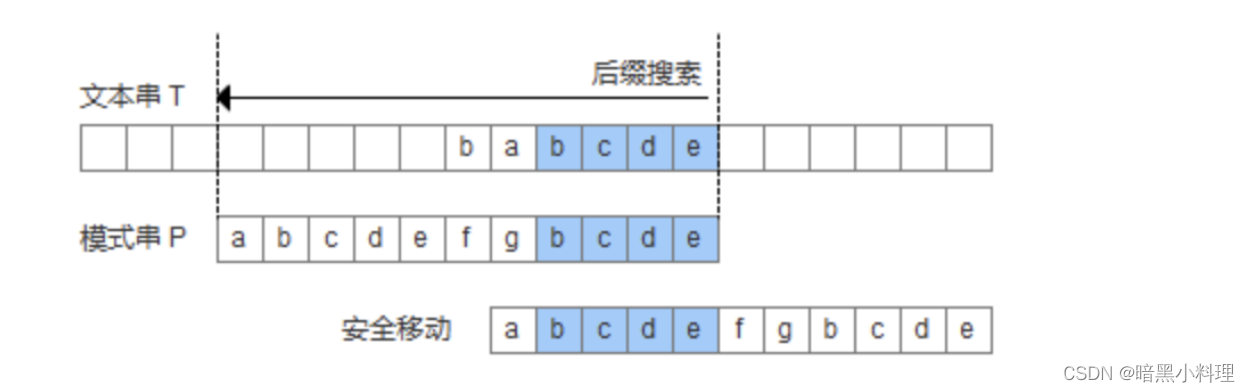
2.模式串中没有子串匹配上好后缀,此时需要寻找模式串的一个最长前缀,并让该前缀等于好后缀的后缀,寻找到该前缀后,让该前缀和好后缀对齐即可。
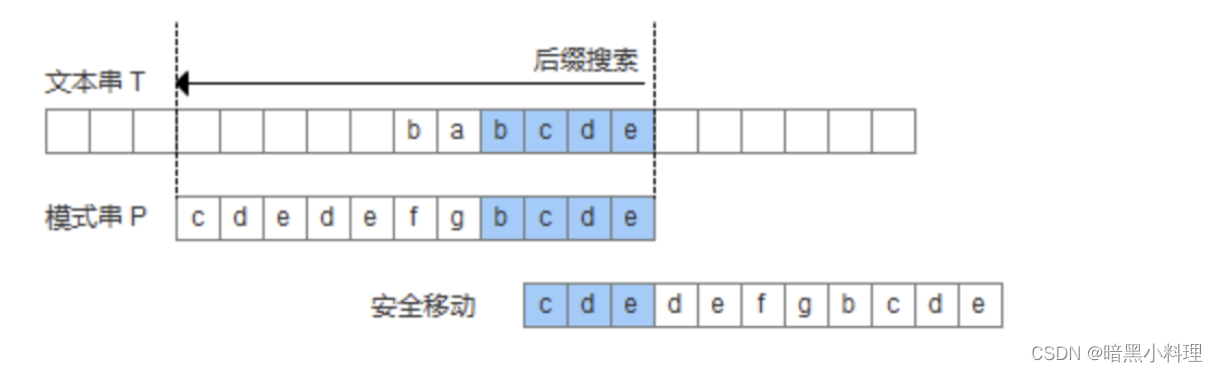
3.模式串中没有子串匹配上好后缀,并且在模式串中找不到最长前缀,让该前缀等于好后缀的后缀。此时,直接移动模式到好后缀的下一个字符。
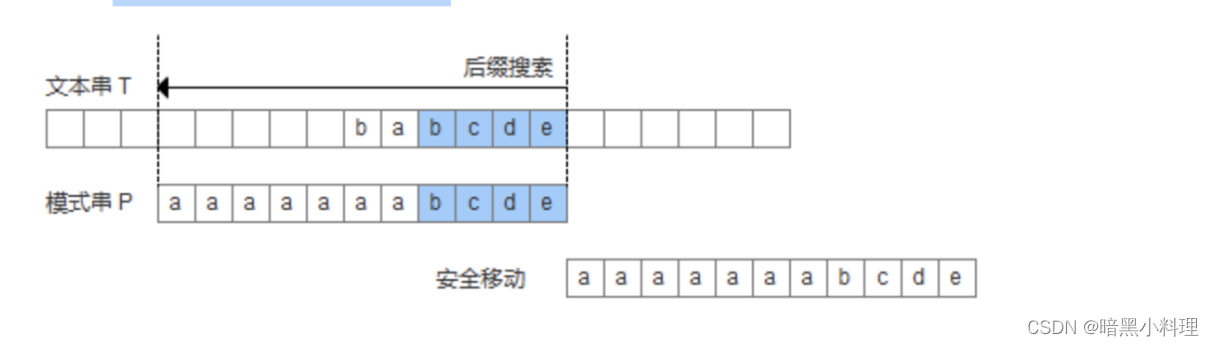
实现好后缀数组代码
void get_goodsuffix(int* goodsuffix,int t_len,bool* ispre,const char* t)
{
for(int i=0;i<t_len+1;i++)
{
goodsuffix[i]=-1;
}
for(int i=0;i<t_len-1;i++)
{
int j=i;
int k=t_len-1;
while(j>=0&&t[j]==t[k])
{
goodsuffix[t_len-k]=j;
k--;
j--;
}
if(j==-1)
ispre[i+1]=true;
}
}
实现好后缀的代码相当繁琐,且时间复杂度较高,为O(n^2)
这是两种移动模式串的方法,然后我们比较那种移动的模式串位数较多,我们就选择哪一种去移动模式串,进行匹配
BM算法
int BM( char s[], char t[])//s为主串,t为模式串
{
int s_len=strlen(s);
int t_len=strlen(t);
int badchar[256];
int* goodsuffix=new int[t_len+1];
bool* ispre =new bool[t_len+1];
get_badchar(badchar,t);
get_goodsuffix(goodsuffix,t_len,ispre,t);
if(s_len<t_len)
return 0;
int idx1=t_len-1;
int idx2=t_len-1;
while(idx1<s_len)
{
while(idx2>=0&&s[idx1]==t[idx2])
{
idx1--;
idx2--;
}
if(idx2==-1)
return idx1+2;
int way1=idx2-badchar[s[idx1]],way2=0;
if(idx2<t_len-1)
{
if(goodsuffix[t_len-idx2-1]!=-1)
way2=idx2-goodsuffix[t_len-idx2-1]+1;
else{
bool flag=0;
for(int i=t_len-idx2-2;i>0;i--)
{
if(ispre[i])
{
flag=1;
way2=t_len-i-1;
break;
}
}
if(!flag)
way2=t_len;
}
}
int choose=max(way1,way2);
idx1+=t_len-1-idx2+choose;
idx2=t_len-1;
}
return 0;
}
但是我认为,由于实现好后缀的算法时间复杂度较高,导致整体BM算法时间复杂度也比较高。
5.测试案例与实验结果
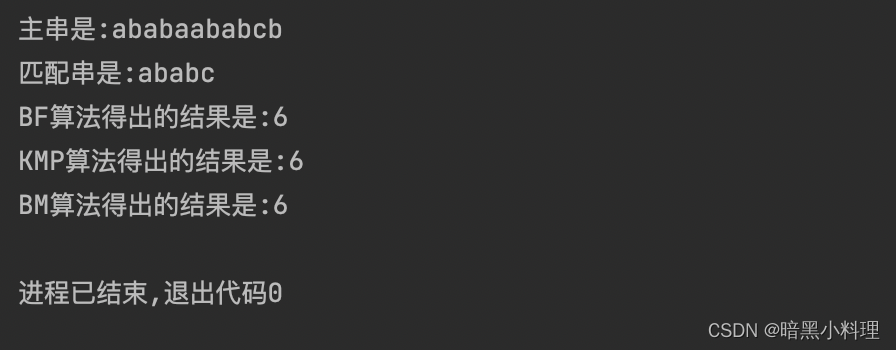
char s1[]="ababaababcb";
char s2[]="ababc";
int result1=BF(s1,s2);
int result2=KMP(s1,s2);
int result3=BM(s1,s2);
cout<<"主串是:"<<s1<<endl;
cout<<"匹配串是:"<<s2<<endl;
cout<<"BF算法得出的结果是:"<<result1<<endl;
cout<<"KMP算法得出的结果是:"<<result2<<endl;
cout<<"BM算法得出的结果是:"<<result3<<endl;//加入BM算法的结果
如果觉得写的好的话,记得给个小心心呀!















 1457
1457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









