







前言
在人工智能领域不断进步的过程中,人们对更准确且具备上下文理解能力的响应的追求,催生了诸多突破性创新。
而 Claude 的上下文检索技术就是其中一项进步,有望显著提升检索增强生成 (RAG) 系统的表现。
可能有同学就要问了:上下文检索技术是什么?
大白话来说,就是现在的AI越来越聪明了,尤其是在回答问题的时候,它可以更好地理解和利用上下文,而不仅仅是“查”到一些零碎的信息。
而本篇文章将讲解 Claude 先进的上下文检索技术如何提高 RAG 准确性,提高 AI 的知识检索能力,从而获得更精确、更具上下文感知的响应
如果你对Claude感兴趣的话,又很想升级Claude Pro,可以看看往期文章
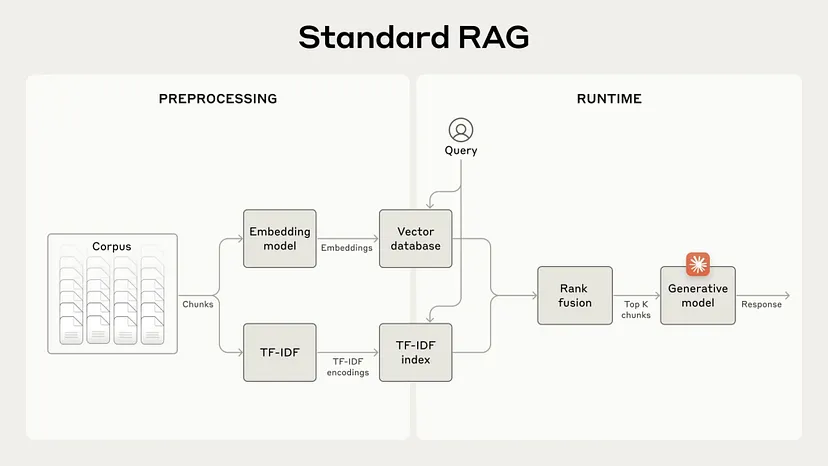
RAG 革命及其局限性
RAG (检索增强生成)改变了游戏规则,为 AI 模型提供了庞大的知识库。
通过检索相关信息并将其纳入生成过程,RAG 系统使 AI 能够提供更明智、更准确的响应。
不过,传统的 RAG 解决方案往往难以保留上下文,导致系统无法检索最相关的信息。打个比方,你和AI聊了一阵,它可能忘记了前面说过的话,没法持续保持“记忆”,导致有时给出的信息不够准确。
而这种局限性在需要细致理解或特定领域知识的场景中尤为明显。例如,如果无法全面掌握业务背景,客户支持聊天机器人可能难以提供准确的帮助,而如果无法访问相关案例历史,法律分析机器人可能会失败。
进入上下文检索:范式转变
Anthropic 的上下文检索方法代表了解决这些挑战的重大飞跃。通过引入两个关键子技术——上下文嵌入和上下文 BM25(下文会对这两个子技术进行解释)。
这两个技术的结合极大地改进了RAG系统的效果,这些创新之后的影响也是惊人的:
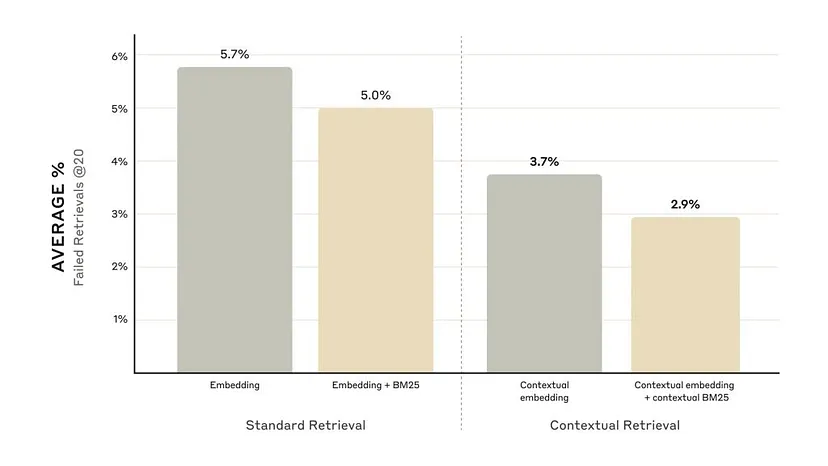
- 仅上下文嵌入就将检索失败率降低了 35%(从 5.7% 降至 3.7%)。
- 上下文嵌入和上下文 BM25 的组合进一步将失败率降低了 49%(从 5.7% 降至 2.9%)。
- 与重新排序技术结合使用时,检索失败率可大幅降低 67%。
这些进步显著提高了搜索准确性,从而也提高了广泛 AI 应用的性能。
解读语境检索
上下文检索的核心就是尽量保留和利用相关的上下文信息,特别是在面对大型数据库和复杂问题时。这里面有两个关键部分:
- 上下文嵌入
这个技术通过给每个文本片段加上背景信息,确保系统能理解这些片段的语义。简单来说,AI不仅知道每个词的意思,还知道它们背后的含义。
- 上下文 BM25
这是结合了传统的文本匹配算法,确保AI可以处理那些对精确匹配有要求的查询。这样,AI既可以理解大概意思,又能精确找到关键字,适用于更多不同类型的问题。
重新构想检索过程
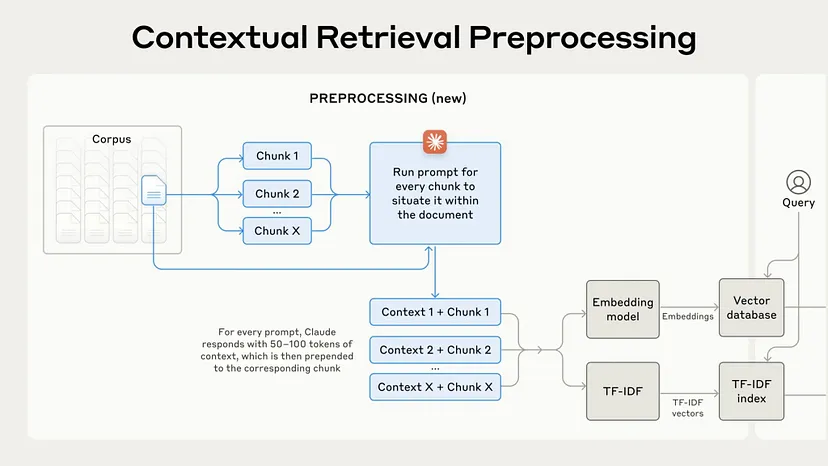
有了上下文检索,整个检索流程也变得更加优化。它包括:
文档分块和上下文生成
嵌入和 BM25 索引创建
搜索和排序
上下文融合和最终生成回答
这样,每个步骤都可以保持上下文,确保AI生成的答案更加相关。
重新排序:最后一步的优化
上下文检索的最后一步是“重新排序”,这相当于给找到的答案再打个分,确保最终传递给AI的内容是最相关的。
成本和效率考虑
而这么强大的技术也带来了计算成本的问题。为了应对这个挑战,Anthropic 引入了一个优化方案,叫做“即时缓存”。它可以存储和重复使用上下文信息,这样一来,系统的运行成本和时间都会大大降低。
实际效果是:
- 上下文嵌入的生成成本降低了90%
- 检索延迟减少了50%
这使得上下文检索不仅强大,而且在大规模应用中也变得可行。
现实中的应用
这种技术不只是理论上的进步,它可以真正改变很多AI应用。比如:
- 客服系统可以提供更个性化的帮助
- 法律AI可以更精准地分析案件
- 研究助手可以更细致地提供信息
- 内容推荐系统可以更好地匹配用户的需求
未来展望
尽管上下文检索已经取得了显著进步,这可能还只是个开始。未来的发展可能会让AI理解和利用上下文的能力更强,比如:
- 更复杂的上下文生成
- 与其他高级NLP模型的结合
- 多模态检索,包括图像、音频和视频
这项技术将为更智能、更细腻的AI系统铺平道路。
最后有话说
Claude 的上下文检索技术确实为 AI 在理解和记忆对话背景方面带来了巨大的进步。它解决了传统 RAG 系统难以保持上下文的缺点,让 AI 能够给出更加准确、贴近用户需求的答案。这种技术特别适合复杂的、需要细致分析的场景,比如法律分析或客户支持。
不过,从长远来看,随着多模态技术的发展,如何在更多数据形式中应用上下文检索,仍是个值得期待的方向。总的来说,这是 AI 迈向更智能、更人性化的重要一步。
往期文章推荐:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











