







创建Maven项目
1.1 增加Scala插件
Spark由Scala语言开发的,所以本课件接下来的开发所使用的语言也为Scala,咱们当前使用的Spark版本为2.4.5,默认采用的Scala版本为2.12,所以后续开发时。我们依然采用这个版本。开发前请保证IDEA开发工具中含有Scala开发插件
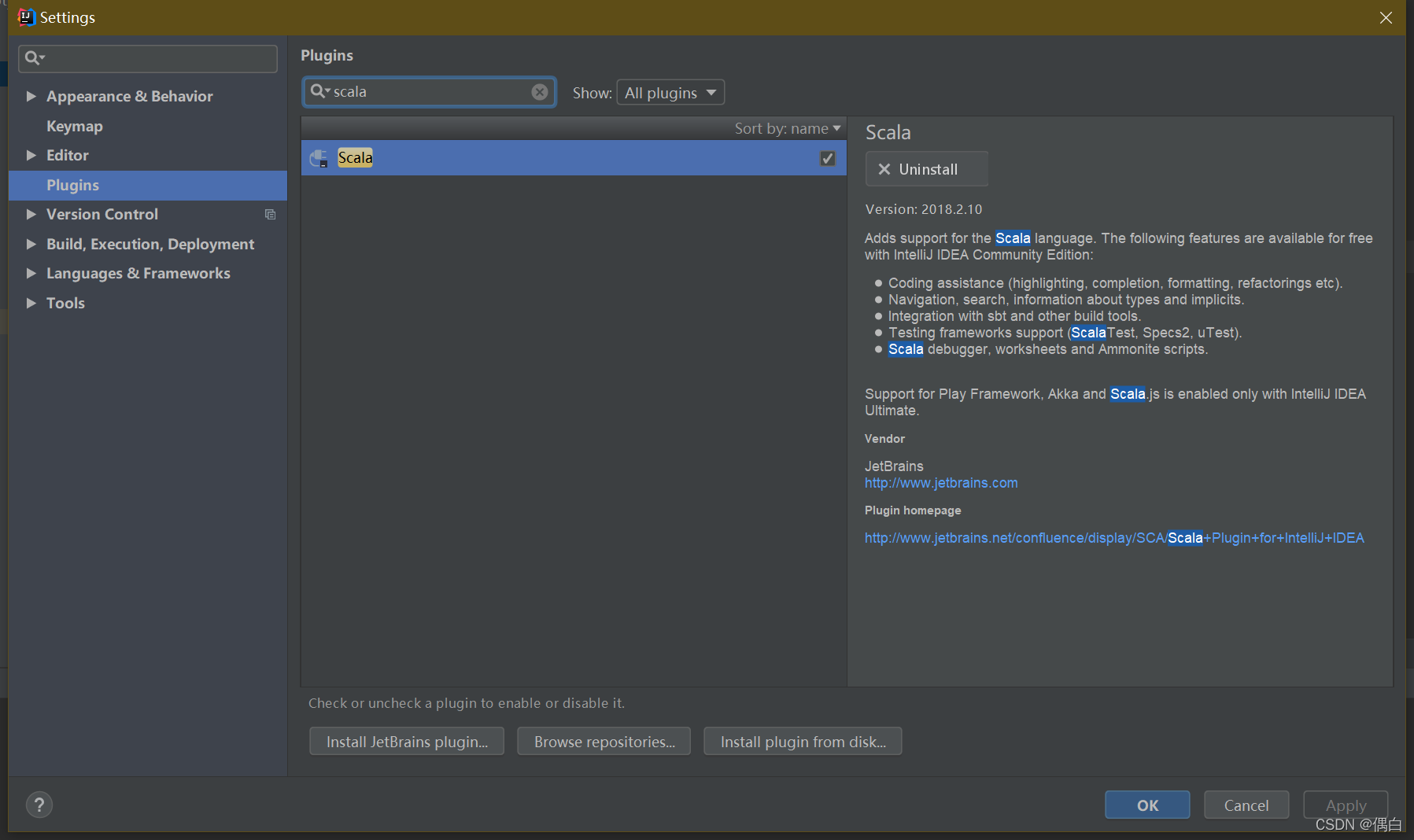
在idea的setting中,找到plugins,搜索scala,并进行安装,如果不安装插件,我们是无法在idea中创建scala文件的
1.2 增加依赖关系
修改Maven项目中的POM文件,增加Spark框架的依赖关系。本文中基于Spark2.4.5版本,使用时请注意对应版本。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
配置时注意:spark-core_2.12
后缀为scala语言的版本,如果没有装scala的话,可以直接使用idea下载
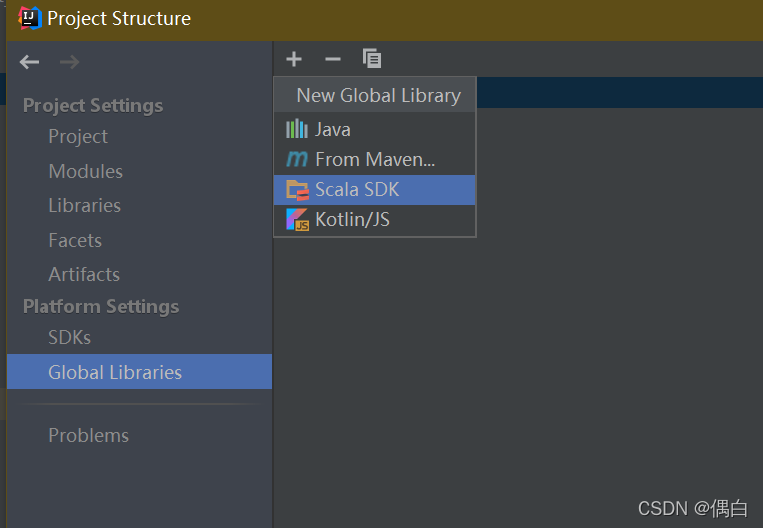
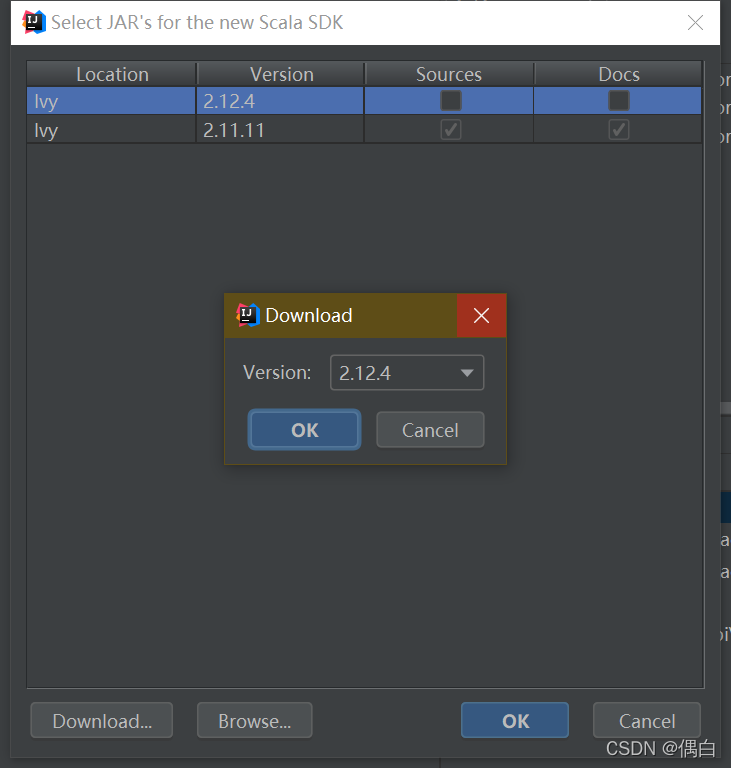
在project Structure中找到global libraries 点击加号,添加scala sdk选择对应的版本下载即可
下载完成后,我们已经趋近于成功了,在项目的src的main目录下创建一个scala目录,我们的scala文件集中放置在这个位置,注意,我们在新建的时候,目录和java的颜色是不是不一样,这里我们需要手动去修改
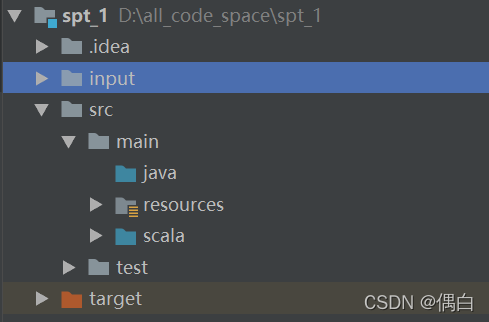
右键我们的scala文件夹,找到对应选项,更改scala文件夹
到这里,我们就算是完成了,创建一个最经典的wordcount项目来试验一下吧
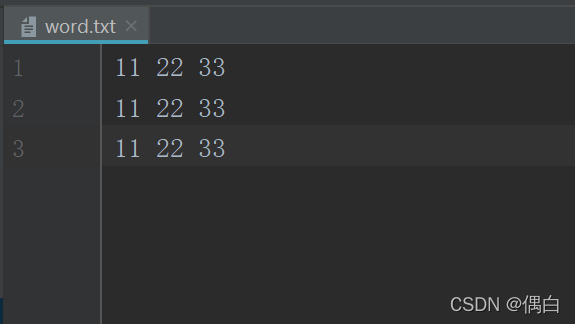
创建一个txt文件,随便写几行东西
在scala中创建一个scala文件,写入以下代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object test1 {
def main(args: Array[String]): Unit = {
// 创建Spark运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建Spark上下文环境对象(连接对象)
val sc : SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.textFile("word.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
// 转换数据结构 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
// 将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭Spark连接
sc.stop()
}
}
直接执行就可以了

















 2309
2309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









