






集合
1. 概述
Java 集合,也叫作容器,主要是由两大接口派生而来:
-
Collection接口,主要用于存放单一元素,三大子接口List、Set、Queue; -
Map接口,主要用于存放键值对。
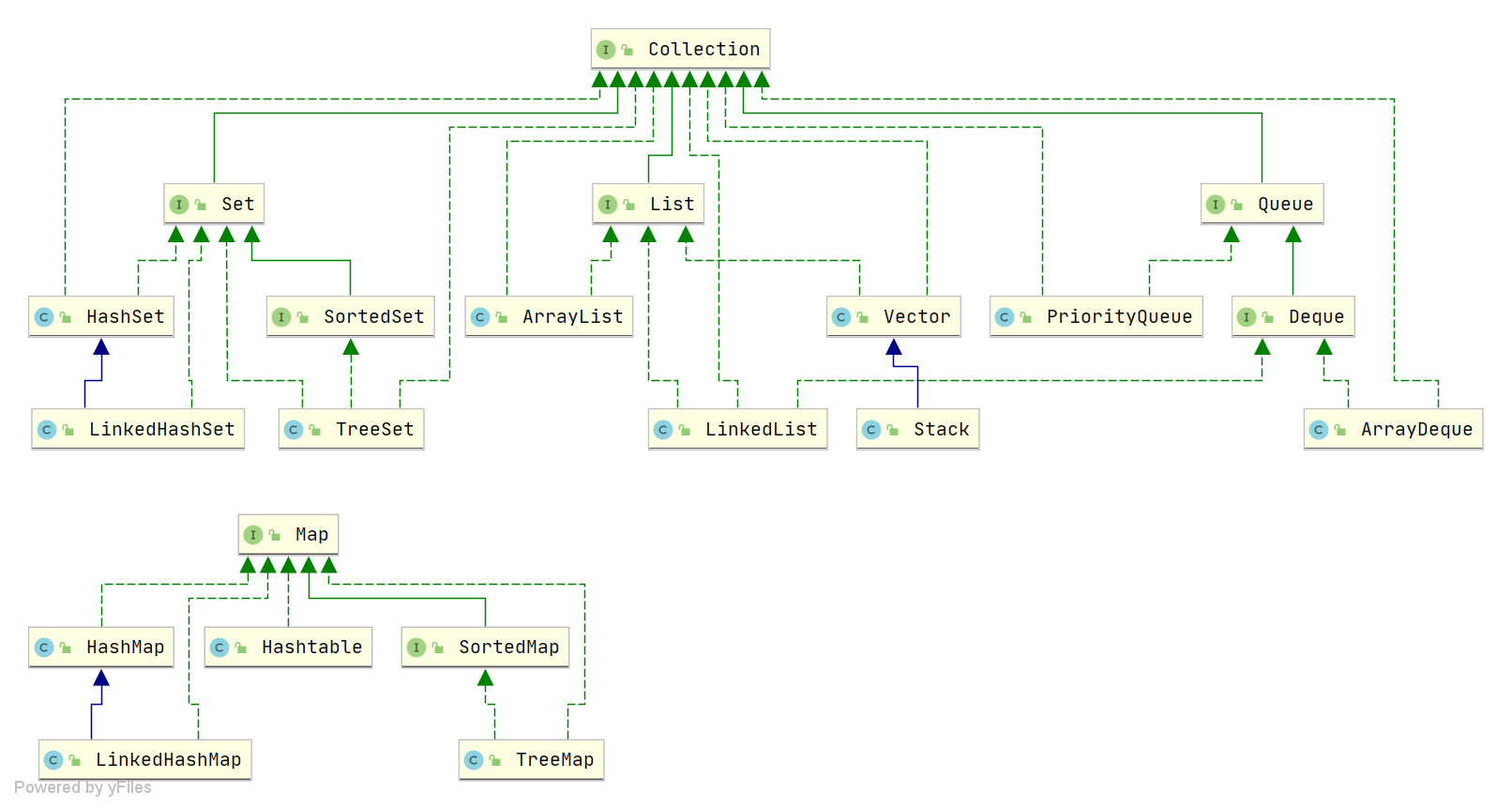
1. List, Set, Queue, Map 四者的区别?
-
List(顺序): 存储的元素是有序的、可重复的。 -
Set(不重): 存储的元素不可重复的。 -
Queue(排队): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。 -
Map( key 搜索): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
2. 选用集合
-
键值获取到元素值时就选用
Map接口下的集合。 排序TreeMap, 不排序HashMap, 线程安全ConcurrentHashMap。 -
存放元素值时,就选择实现
Collection接口的集合。 元素唯一Set(TreeSet,HashSet) ,否则List(ArrayList、LinkedList)。
相较于数组,Java 集合的优势在于它们的大小可变、支持泛型、具有内建算法等,提高了数据的存储和处理灵活性。
2. List
1. ArrayList vs. 数组
| 特性 | ArrayList | Array |
|---|---|---|
| 实现方式 | 动态数组 | 静态数组 |
| 长度 | 会根据实际存储的元素动态扩容或缩容 | 创建后长度不可变 |
| 类型安全 | 允许使用泛型确保类型安全 | 不支持泛型 |
| 存储类型 | 只能存储对象,基本类型需使用对应的包装类 | 可直接存储基本类型数据和对象 |
| 操作方法 | 支持插入、删除、遍历等常见操作,提供丰富的API方法 | 只能按下标访问元素,不具备动态添加、删除元素的能力 |
| 创建时是否需指定大小 | 创建时不需要指定大小 | 创建时必须指定大小 |
ArrayList 可以添加null值,但是会让代码难以维护比如忘记做判空处理就会导致空指针异常。
2. ArrayList插入删除元素时间复杂度
| 操作类型 | 位置 | 时间复杂度 | 说明 |
|---|---|---|---|
| 插入 | 头部 | O(n) | 需要将所有元素依次向后移动一个位置 |
| 尾部 | O(1) / O(n) | 容量未达到极限时为 O(1),达到极限需要扩容时为 O(n) | |
| 指定位置 | O(n) | 需要将目标位置之后的所有元素向后移动一个位置 | |
| 删除 | 头部 | O(n) | 所有元素依次向前移动一个位置 |
| 尾部 | O(1) | 删除末尾元素时,时间复杂度为 O(1) | |
| 指定位置 | O(n) | 目标位置之后的所有元素向前移动一个位置 |
LinkedList:
-
头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
-
尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
-
指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,因此需要遍历平均 n/2 个元素,时间复杂度为 O(n)。
需要用到 LinkedList 的场景几乎都可以使用 ArrayList 来代替,并且,性能通常会更好!
3. LinkedList 为什么不能实现 RandomAccess 接口?
RandomAccess 是一个标记接口,用来表明实现该接口的类支持随机访问(即可以通过索引快速访问元素)。 由于 LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问。
4. ArrayList的扩容机制
3. Set
1. Comparable vs. Comparator
都是 Java 中用于排序的接口,支持 Collections.sort 和 Arrays.sort 的排序。
-
待比较类重写
Comparable #compareTo()即可,内部定义。 -
创建一个比较器类 实现
Comparator #compare(),再实例化作为sort()第二个参数(或者匿名内部类),外部定义,推荐!
2. 无序性 和 不可重复性 的含义是什么?
-
无序性不等于随机性 ,无序性是指存储的数据在底层数组中不按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。
-
不可重复性是指添加的元素按照
equals()判断时 ,返回 false,需要同时重写equals()方法和hashCode()方法。
3. HashSet vs. LinkedHashSet vs. TreeSet
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层数据结构 | 哈希表 | 链表和哈希表 | 红黑树 |
| 元素顺序 | 无序 | 插入顺序 | 自然排序或定制排序 |
| 元素唯一性 | 是 | 是 | 是 |
| 元素排序 | 不支持排序 | 不支持排序 | 支持 |
| 应用场景 | 不需要保证元素插入和取出顺序的场景 | 需要保证元素的插入和取出顺序满足FIFO的场景 | 支持对元素自定义排序规则的场景 |
4. Queue
1. Queue vs. Deque
-
Queue是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。 -
Deque是双端队列,在队列的两端均可以插入或删除元素。(可以模拟栈)
因为容量问题而导致操作失败后处理方式的不同: 一种在操作失败后会抛出异常,另一种则会返回特殊值。
2. PriorityQueue
元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。
3. BlockingQueue
BlockingQueue (阻塞队列)是一个接口,继承自 Queue。阻塞的原因是其支持当队列没有元素时一直阻塞,直到有元素;还支持如果队列已满,一直等到队列可以放入新元素时再放入。常用于生产者-消费者模型中,生产者线程会向队列中添加数据,而消费者线程会从队列中取出数据进行处理。
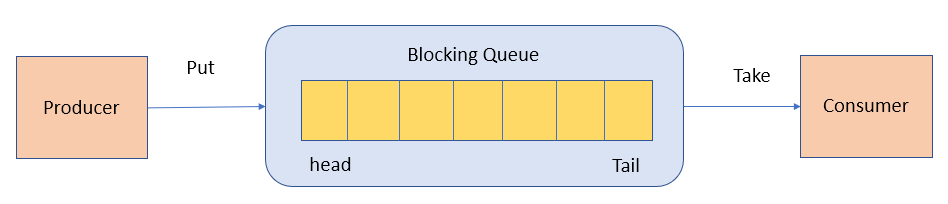
常见实现类:
-
ArrayBlockingQueue:使用数组实现的有界阻塞队列。在创建时需要指定容量大小,并支持公平和非公平两种方式的锁访问机制。 -
LinkedBlockingQueue:使用单向链表实现的可选有界阻塞队列。在创建时可以指定容量大小,如果不指定则默认为Integer.MAX_VALUE。和ArrayBlockingQueue不同的是, 它仅支持非公平的锁访问机制。 -
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。元素必须实现Comparable接口或者在构造函数中传入Comparator对象,并且不能插入 null 元素。 -
SynchronousQueue:同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,SynchronousQueue通常用于线程之间的直接传递数据。 -
DelayQueue:延迟队列,其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
| 特性 | ArrayBlockingQueue | LinkedBlockingQueue |
|---|---|---|
| 底层实现 | 数组 | 链表 |
| 是否有界 | 有界队列,创建时必须指定容量大小 | 默认无界(Integer.MAX_VALUE),也可以指定容量大小 |
| 锁是否分离 | 锁未分离,生产和消费使用同一个锁 | 锁分离,生产用putLock,消费用takeLock |
| 内存占用 | 需要提前分配数组内存 | 动态分配链表节点内存 |
两者都是线程安全的。















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









