







目录
前言
如果尚未了解主从复制的话建议观看这一篇博客:
Redis的主从复制模式下,⼀旦主节点由于故障不能提供服务,需要⼈⼯进⾏主从切换,同时⼤量
的客⼾端需要被通知切换到新的主节点上,对于上了⼀定规模的应⽤来说,这种⽅案是⽆法接受的,于是Redis从 2.8 开始提供了Redis Sentinel(哨兵)加个来解决这个问题
哨兵基本概念
Redis Sentinel是 Redis 的⾼可⽤实现⽅案,在实际的⽣产环境中,对提⾼整个系统的⾼可⽤是⾮常有帮助的
主从复制的一些问题:
Redis的主从复制模式可以将主节点的数据改变同步给从节点,这样从节点就可以起到两个作⽤:
第⼀:作为主节点的⼀个备份,⼀旦主节点出了故障不可达的情况,从节点可以作为后备“顶”上
来,并且保证数据尽量不丢失(主从复制表现为最终⼀致性)。
第⼆:从节点可以分担主节点上的读压⼒,让主节点只承担写请求的处理,将所有的读请求负载均衡到各个从节点上
但是他并不是万能的,有一些遗留问题~
- 主节点发⽣故障时,进⾏主备切换的过程是复杂的,需要完全的⼈⼯参与,导致故障恢复时间⽆法保障
- 主节点可以将读压⼒分散出去,但写压⼒/存储压⼒是⽆法被分担的,还是受到单机的限制。
人工恢复故障:
1.发现主节点master出现宕机(OK这第一步就已经非常恶心了,因为主节点什么时候挂掉你根本不知道,更何况如果是在夜深人静的时候挂了~~很折磨)
2.你发现了主节点宕机了,此时就要从一个从节点集群中选择一个新的作为主节点(要尽量保证数据跟主节点一致)
3.配置其他所有从节点让他们重新指向新的主节点(万一子节点多,就要一个一个配,并且还有可能出错)
4.让应用连接新的主节点,否则用户仍旧不能读
5.此时如果原来的主节点恢复了,就手动把它设置成从节点加入进来
哨兵自动恢复节点故障:
当主节点出现故障时,Redis Sentinel能⾃动完成故障发现和故障转移,并通知应⽤⽅,从⽽实现真正的⾼可⽤
Redis Sentinel 是⼀个分布式架构,其中包含若⼲个 Sentinel 节点和 Redis 数据节点
每个Sentinel 节点会对数据节点和其余Sentinel节点进⾏监控,当它发现节点不可达时,会对节点做下线表⽰。
如果下线的是主节点,它还会和其他的Sentinel节点进⾏“协商”,当⼤多数Sentinel节点对主节点不可达这个结论达成共识之后,它们会在内部 “选举” 出⼀个领导节点来完成⾃动故障转移的⼯作,同时将这个变化实时通知给 Redis 应⽤⽅。整个过程是完全⾃动的,不需要⼈⼯介⼊。
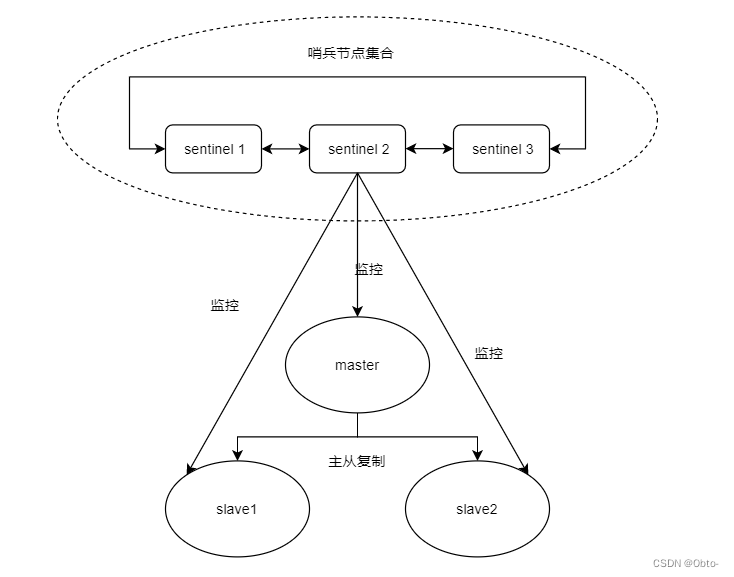
Redis Sentinel 相⽐于主从复制模式是多了若⼲(建议保持奇数)Sentinel节点⽤于实现监控数据节点,哨兵节点会定期监控所有节点(包含数据节点和其他哨兵节点)。
针对主节点故障的情况,故障转移流程⼤致如下:
1)主节点故障,从节点同步连接中断,主从复制停止
2)哨兵节点通过定期监控发现主节点出现故障。哨兵节点和其他哨兵节点协商,达成多数认同该节点发生故障的共识。
3)哨兵节点之间使用Raft算法选举出一个领导角色,负责该节点后续的故障转移工作
4)哨兵leader领导者开始执行故障转移:从节点中选择一个作为新主节点;让其他从节点同步新主节点,通知应用层转移新的主节点
通过上面可以知道redis 哨兵具有以下几个功能;
- 监控:Sentinel节点会定期检测Redis数据节点
- 故障转移:实现从节点晋升成主节点并维护后续正确的主从关系
- 通知:Sentinel接一单回家过年故障转移的结果通知给应用方
哨兵的部署
由于我们就一台云服务器,所以只能使用docker来在本地同时跑三个哨兵服务,实际上这样毫无意义~
安装docker:
# ubuntu
apt install docker-compose
# centos
yum install docker-compose
停止之前的redis-server:
// 停⽌ redis-server
service redis-server stop使用docker获取redis镜像:
docker pull redis:5.0.9 编写redis主从节点
1)写docker-compose.yml (名字不能变)
新建一个redis目录
docker-compose.yml文件的数据
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name : redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name : redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379
2)启动所有容器
docker-compose up -d
如果启动后发现前面配置有误,那就docker-compose down停止一下并删除刚才创建好的容器
3)查看运行日志
docker-compose logs上述操作必须保证⼯作⽬录在yml的同级⽬录中,才能⼯作
编写redis-sentinal节点
这里把redis-sentinal和redis节点分卡启动时为了好观察日志
创建新目录:

注意:每个目录只能有一个docker-compose.yml文件
docker-compose.yml文件编写
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name : redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379
networks:
default:
external:
name: redis-data_default
创建三个哨兵节点的配置文件,上面的那个配置文件yml是docker用的
sentinal1.conf的初始文件内容,其余两个也一样,cv过去即可
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000下面是运行了一段时间后的sentina1.conf文件

理解sentinal monitor
sentinel monitor 主节点名 主节点ip 主节点端⼝ 法定票数 )主节点名这里自己起名
)主节点ip,部署redis-master的设备ip,由于我们直接使用docker,可以直接写docker的容器名,会被DNS成对应容器ip
)法定票数,即主节点挂了需要多个哨兵确认,达到这个票数才是真正确认挂
)sentinel down-after-milliseconds 这是心跳包的超时时间,超过这个时间没响应就认为节点故障
既然内容相同,为啥要创建多份配置⽂件redis-sentinal在运⾏中可能会对配置进⾏rewrite,修改⽂件内容.如果⽤⼀份⽂件,就可能出现修改混乱的情况.
上面的sentinel1.conf和sentinel2.conf运行一段时间后,内部数据不同,所以不能共用一个~
配制好redis-data和redis-sentinel目录下的所有配置后就可以开始启动容器了:
docker-compose up -d 查看运行日志:
docker-compose logs 选举原理:
1)主观下线
当redis-master宕机,此时redis-master和三个哨兵之间的⼼跳包就没有了.此时,站在三个哨兵的⻆度来看,redis-master出现严重故障 因此三个哨兵均会把redis-master判定为主观下线(SDown)
2)客观下线
此时, 哨兵 sentenal1, sentenal2, sentenal3 均会对主节点故障这件事情进⾏投票.当故障得票数>=配置的法定票数之后
sentinel monitor redis-master 172.22.0.4 6379 2 此时意味着 redis-master 故障这个事情被做实了.此时触发客观下线(ODown)
3)选举出哨兵的leader
接下来需要哨兵把剩余的slave中挑选出⼀个新的master.这个⼯作不需要所有的哨兵都参与.只需要选出个代表(称为leader),由leader负责进⾏slave升级到 master 的提拔过程.这个选举的过程涉及到 Raft 算法
假定有三个哨兵节点S1,S2,S3
1)每个哨兵节点都会给其他的哨兵节点,发起一个拉票请求
2.收到拉填请求的节点,会回复一个投票响应(每个节点只能投票一次)
3)如果一轮投票发现自己票数过半,自动成为leader
4)leader几点负责挑选一个新的slave成为一个新的master,当其他的sentinal发现新的master出现了,说明选举结束了
4) leader挑选出合适的slave成为master
1)比较优先级,优先级高的尚未。优先级在配置文件有
2)比较replication offset 看谁复制的多谁上位
3)比较run id,谁id小谁上位
当某个slave节点成为主节点后
1.leader指定该节点执行slave no one,让他自己成为主节点
2.leader指定剩余的slave节点都依附于这个新master~~
总结
- 哨兵节点不能只有⼀个.否则哨兵节点挂了也会影响系统可⽤性.
- 哨兵节点最好是奇数个.⽅便选举 leader, 得票更容易超过半数.
- 哨兵节点不负责存储数据.仍然是 redis 主从节点负责存储.
- 哨兵 + 主从复制解决的问题是"提⾼可⽤性",不能解决" 数据极端情况下写丢失" 的问题.
- 哨兵+主从复制不能提⾼数据的存储容量.当我们需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了
















 5024
5024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











