







并发模型之Master-Worker模式
1.核心思想
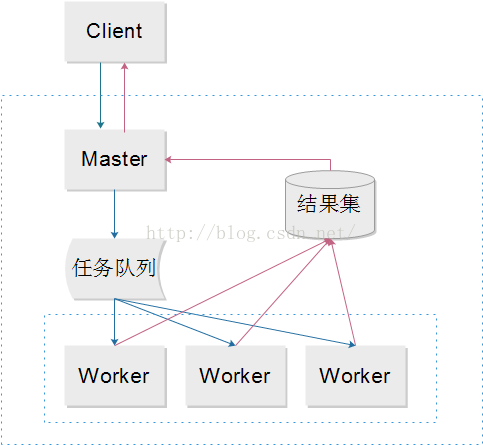
由两个进程协作工作,master负责接收和分配任务,worker负责处理任务,Master汇总worker各子线程处理结果,返回给客户端。
- 感觉Map-Reduce的基础思想就用的这个模型….
2.优点及应用场景
它的好处在于能把一个大任务分解成若干个小任务,并行执行,提高系统吞吐量。
并且对于客户端而言,一旦提交任务,master进程立刻返回一个处理结果,并非等待系统处理完毕再返回。
Master-Worker模式是一种将串行任务并行化的方案,被分解的子任务在系统中可以被并行处理,
Master进程可以不需要等待所有子任务都完成计算,就可以根据已有的部分结果集计算最终结果集。
3.应用示例代码
利用Master-Worker模型实现一个计算1-100立方和,思路如下:
1、将计算任务分配成100个子任务,每个子任务用于计算单独数字的立方和
2、master产生固定个数的worker用于处理这个子任务
3、worker开始计算,并把结果写入resultMap中
4、master负责汇总map中的数据,求和后将最终结果返回给客户端
worker 抽象类:
/**
* Worker实际处理单个子任务
* 1.从workQueue出队列获取子任务
* 2.handle()处理子任务
* 3.将结果写入resultMap
*
* @author YiJie
* @date May 9, 2017
*/
public abstract class Worker implements Runnable{
//任务队列,用于每个子任务
protected Queue<Object> workQueue;
//子任务处理结果集
protected Map<String,Object> resultMap;
public void setWorkQueue(Queue<Object> workQueue) {
this.workQueue = workQueue;
}
public void setResultMap(Map<String, Object> resultMap) {
this.resultMap = resultMap;
}
//子任务处理逻辑,在子类中具体实现
public abstract Object handle(Object input);
@Override
public void run() {
while(true){
//获取子任务
Object input = workQueue.poll();//出队列
if(input==null)
break;
//处理子任务
Object result = handle(input);
//将处理结果写入结果集,key为子任务哈希码
resultMap.put(Integer.toString(input.hashCode()), result);
}
}
}
CubeSumWorker 实现类
/**
* 求立方和的Worker实现类。实现handle方法:子任务立方操作
*
* @author YiJie
* @date May 9, 2017
*/
public class CubeSumWorkerWorker extends Worker {
@Override
public Object handle(Object input) {
Integer i=(Integer)input;
return i*i*i;
}
}Master抽象类
/**
* Master负责分配任务和任务结果合成
*
* @author YiJie
* @date May 9, 2017
*/
public abstract class Master {
// 任务队列
protected Queue<Object> workQueue = new ConcurrentLinkedQueue<Object>();
// work线程队列
protected Map<String, Thread> threadMap = new HashMap<String, Thread>();
// 子任务处理结果集
protected Map<String, Object> resultMap = new ConcurrentHashMap<String, Object>();
public Map<String, Object> getResultMap() {
return resultMap;
}
/**
* 构造函数。创建workerCount个装有(统一的/本类中的)workQueue,resultMap的worker线程,写入threadMap线程集合
* @param worker 一个worker实现类
* @param workerCount 线程数
*/
public Master(Worker worker, int workerCount) {
worker.setResultMap(resultMap);
worker.setWorkQueue(workQueue);
for (int i = 0; i < workerCount; i++) {
String name = Integer.toString(i);// 新线程名称
threadMap.put(name, new Thread(worker, name));
}
}
/**
* 判断进程队列里的线程状态是否都完成
* @return
*/
public boolean isComplete() {
for (Map.Entry<String, Thread> entry : threadMap.entrySet()) {// entrySet方法遍历threadMap
if (entry.getValue().getState() != Thread.State.TERMINATED) { // 判断进程队列里的线程状态是否为TERMINATED
return false;
}
}
return true;
}
/**
* 提交任务。放入任务队列
* @param job
*/
public void submit(Object job) {
workQueue.add(job);
System.out.println("任务队列size:" + workQueue.size());
}
//Master对结果集的处理,在子类中具体实现.不用等到子线程全部执行完,只要结果集有数据,就可开始主线程的求和计算.
public abstract Object handle(Map<String, Object> resultMap);
/**
* 执行。开始运行所有的worker线程,并执行主线程计算
* @return 返回执行结果
*/
public Object execute() {
for(Map.Entry<String, Thread> entry:threadMap.entrySet()){
entry.getValue().start();//开启线程
System.out.println(entry.getValue());//Thread类覆写了toString()方法,打印出Thread[线程名,优先级,线程组]
}
return handle(resultMap);
}
}
CubeSumMaster 实现类
/**
* 求立方和的Master实现类。实现handle方法:结果集求和操作
*
* @author YiJie
* @date May 12, 2017
*/
public class CubeSumMaster extends Master{
public CubeSumMaster(Worker worker, int workerCount) {
super(worker, workerCount);
}
@Override
public Object handle(Map<String, Object> resultMap) {
Integer result = 0;
Integer value;
String key;
while (resultMap.size() > 0 || !this.isComplete()) {
for (Map.Entry<String, Object> entry : resultMap.entrySet()) {
key = entry.getKey();
value = (Integer) entry.getValue();
if (key != null && value != null) {
result += value;//叠加得到最终结果
resultMap.remove(key);
}
}
}
return result;
}
}
Main启动类
public class Main {
public static void main(String[] args) {
// 创建一个含5个工作线程的Master
Master master = new CubeSumMaster(new CubeSumWorkerWorker(), 5);
// 添加100个子任务
for (int i = 0; i < 100; i++) {
master.submit(i);
}
// 执行
int result = (Integer) master.execute();
System.out.println(result);
}
}运行结果
任务队列size:1~100
Thread[3,5,main]
Thread[2,5,main]
Thread[1,5,main]
Thread[0,5,main]
Thread[4,5,main]
24502500
补充
1.jdk中定义的Thread.State有7项


2.线程数开多少合适?
因为CPU是有线程数的,比如4核4线程的CPU,那如果你的线程主要是用来做运算的,就是不是单纯的执行IO的,那这个线程数尽量的靠近CPU的核数,因为线程在CPU运算的过程中不会被释放,多于核心数了,会降低性能。但是如果你的线程是在执行IO操作,那因为CPU本身没有运算的操作,只是等待IO的读写,这时候CPU可以腾出来很多的空间去开启线程,直至填满CPU才会降低性能,所以线程用来执行数据库读写的时候,线程数可以设置为CPU数量的2-10倍。读写时间是会受查询数据库量的大小而影响的,如果你查的量大,那这个IO返回的就很慢。2-10倍是一个经验值,具体要做压测,看线程执行时间。
3.关于Master-Worker的待解决小疑惑 // TODO
它是不是mapreduce的一个基本思路呢?
一些排序算法查找算法中,有没有Master-Worker的应用场景呢?
并发的从任务队列workQueue中取子任务如何保证不取重呢?
本文有任何错误,或有任何意见和建议,烦请留言不吝赐教















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









