







htmlunit 是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现。是一个没有界面的浏览器,运行速度迅速。是junit的扩展之一,它采用的是Rhinojs引擎。模拟js运行。常规意义上,该项目可以用来进行页面的测试工作,实现网页自动化测试,(包括JS)但是一般来说,在小型爬虫项目中,这种框架十分常用,可以有效的分析出 dom的标签,并且有效的运行页面上的js以便得到一些需要执行JS才能得到的值。
在一般爬虫应用中 仅仅用Httpclient+jsoup是不够的,只能去获取静态的页面数据,这里就可以使用htmlunit,内嵌js浏览器,模拟Js运行,把结果执行出来
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.29</version>
</dependency>
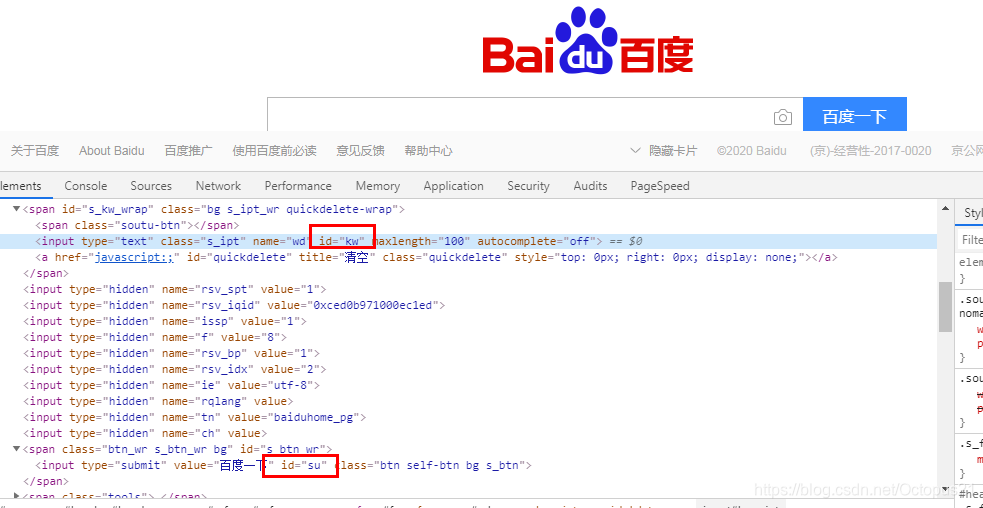
使用案例:使用htmlunit操作表单控件和提交(执行百度搜索)
public static void main(String[] args) throws Exception {
//创建webclient,并设置对应的浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com/");
//获取搜索输入框并提交搜索内容
HtmlInput input = page.getHtmlElementById("kw");
System.out.println(input.toString());
//输入需要搜索的关键词
input.setValueAttribute("Java");
System.out.println(input.toString());
//获取搜索按钮并点击
HtmlInput btn = page.getHtmlElementById("su");
HtmlPage newPage = btn.click();
//输出新页面的文本
System.out.println(newPage.asText());
//当我们通过HtmlPage 获取到HTML文本后就可以通过Jsoup来进行解析了
}


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











