









Python爬虫:概念、知识和简单应用
什么是爬虫?
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
- robots.txt协议:规定了网站中那些数据可以被爬取,那些不可以被爬取
使用的开发工具
- python 3.8
- pycharm
一个简单的爬虫实例
用程序模拟浏览器,输入一个网址,从该网址中获取到资源或者内容。如爬取百度的界面代码。
代码如下:
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url) #打开url
# print(resp.read().decode(utf--8)) #打印抓取到的界面
with open("baidu.html",mode="w",encoding="utf-8") as f: #创建文件
f.write(resp.read().decode("utf-8")) #保存到文件中
print("over!")
结果:


Web请求过程分析
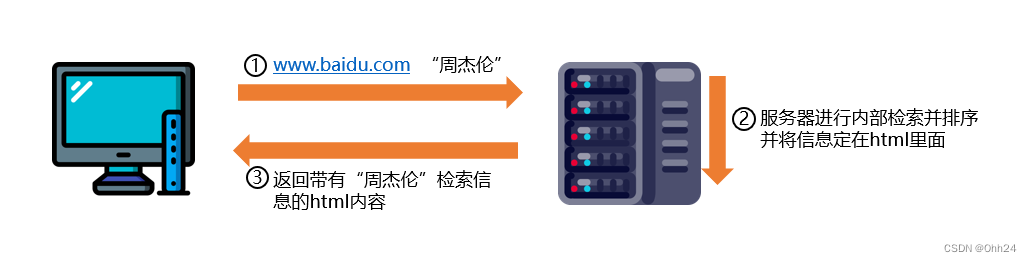
1)服务器渲染:在服务器中直接把数据和html整合并统一返回到浏览器,在页面源代码中能看到数据,是一个静态过程。
举个例子:在百度中搜索“周杰伦”关键字信息。首先客户端会发送关键字到服务器,服务器进行内部检索并将信息排序后插入到html里面,然后返回带有“周杰伦“检索信息的html内容。
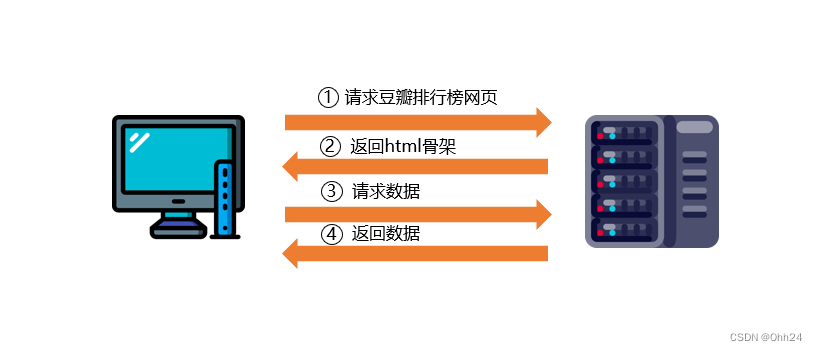
2)客户端渲染:第一次请求只要html骨架,第二次请求拿到数据,进行数据展示。在页面源代码看不到数据,是一个动态过程。
举个例子:查看排行榜页面。首先客户端会请求排行榜页面,服务器返回html骨架,此时客户端未收到数据,然后需要再次请求,由服务器返回数据,最后,由客户端对数据进行拼接。
- 爬虫时一般想要的是数据,可以对浏览器进行抓包
HTTP协议
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP协议把一条消息分为三大模块,无论请求、响应都是三块内容,爬虫时需要注意请求头和响应头,一般含有重要内容
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 放一些服务器使用的附加信息
请求体 -> 一般放请求参数
响应:
状态行 - > 协议 状态码
响应头 -> 放一些客户端要使用的一些附加信息
响应体 - > 服务器返回真正客户端要用的内容(HTML,json)等
请求头中的重要内容
-
User-Agent:请求载体的身份标识
-
Referer:防盗链(请求从哪个页面来?反爬会用到)
-
cookie:本地字符串数据新消息(反爬的token)
响应头中的重要内容
-
cookie:本地字符串数据信息(反爬的token)
-
各种莫名其妙的字符串(一般都是token字样,防止攻击和反爬)
请求方式
GET:显示提交,get请求传递参数爬虫中使用”params=“
POST:隐式提交,post请求传递参数爬虫中使用”data=“
requests
requests相比第三节的urllib使用起来更加简洁
安装
pip install requests
GET实例:输入一个你喜欢的明星,使用request爬取搜索结果页面
如果直接爬取页面会被小小的反爬拦截住,因为服务器判断你的操作来源与自动化脚本,为了让我们的操作看起来更像是人为行为,需要User-Agent字段来标识自己的身份。
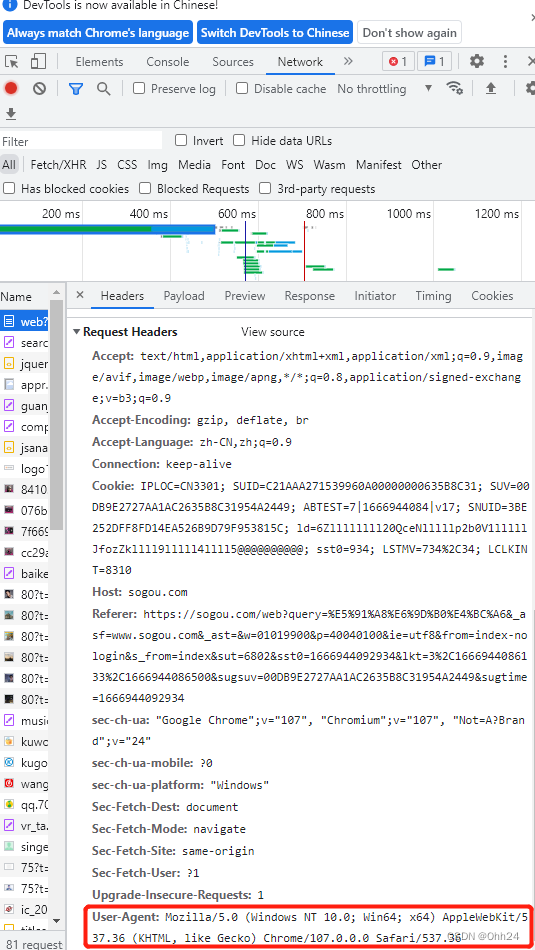
代码如下:
import requests
query = input("请输入一个你喜欢的明星")
url = f'https://sogou.com/web?query={query}'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
resp = requests.get(url,headers=headers) #处理小小的反爬,搜索引擎的搜索栏信息都是get请求
print(resp) #返回状态码
print(resp.text) #返回页面源代码
resp.close()
输出:

POST实例:使用requests获取百度翻译结果
开启开发者模式后,在文本框中输入相应单词,然后查看数据包中有个sug(爬取不同的网站时名字可能不同),其中的preview中发现确定是我们要的信息
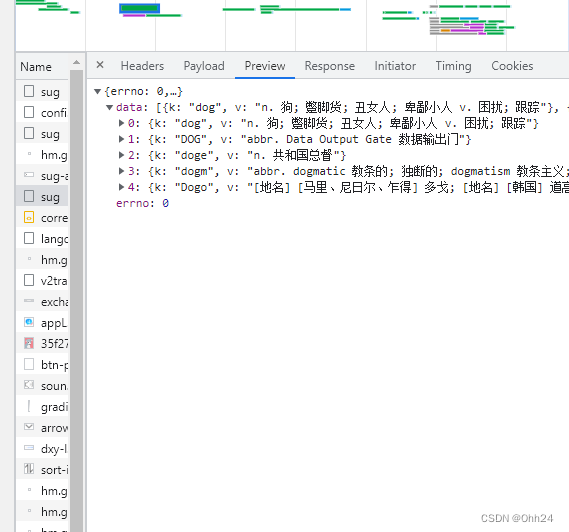
同时可以看到请求方式是post

在payload中可以看到传参的变量值
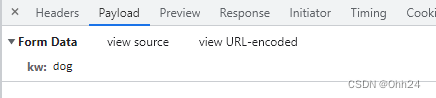
- 使用post方法请求与get方法请求是完全不一样的
代码如下:
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的单词:")
data = {
"kw": s
}
#发送post请求
resp = requests.post(url,data=data) #传入参数
print(resp.json()) #将服务器返回的内容直接处理成json
resp.close()
返回结果:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









