







1. 引言
从2021年年底开始,笔者带领一个微型团队开始开发我们的大数据平台XSailboat,目前已经初步具备实用化条件,产品将持续性地开发、完善、迭代升级。
在接下来的一段时间,笔者将陆续编写一些关于大数据平台实现相关的技术文档,有兴趣的从事大数据相关的同学,可以关注收藏一下,交流一下开发技术。如果对我们的大数据平台XSailboat感兴趣的同学比较多,希望将其应用于学习或商业项目中,我们可以在条件成熟的情况下,开源我们的大数据平台。
如果有些同学对我们大数据平台的模块和细节的实现方式比较感兴趣,欢迎留言。我将尽量抽空撰写相关的技术文档,无遮掩地分享技术内幕。……_如果不够及时,敬请理解。毕竟还得从事其它项目工作,得养家糊口,也得有休息时间……_。也欢迎大家把此篇文档分享给更多从事大数据开发的同学,加入进来一起关注XSailboat的成长。
XSailboat是一个面向政府和大企业的大数据平台,是部署在私有云/机房下的。它和阿里云的大数据工厂(DataWorks)、DataPhin有很多同质的模块,甚至界面都很像。实不相瞒,本人在开发大数据平台之前有带领团队在阿里云上进行数据开发工作,当时觉得这东西我也能搞,后来正好有时间,所以就搞起了。(-),见笑,只是一定程度的能搞,我认为当一个系统要在云环境下面向大规模租户的时候,平台从基础架构和设计方面就会有很大的不同,但这不妨碍我在小规模用户场景下,开发出类似的、可用的大数据平台。毕竟我面对的只是一部分几百万甚至不上百万的政府和大企业项目,和阿里云不在一个舞台上,更无所谓竞争。
产品设计不能超脱预设的应用场景和目标用户,避免在产品初期过度设计,致使产品迟迟不能落地应用。一个优秀的产品首先立足于其应用场景,跟随业务需要一次次迭代升级出来的。当然如果一个设计者有足够的经验和资源,也可以一步跨上更高的台阶。
--------我们的未来是星辰大海,一起扬帆起航----------------
2. 概述
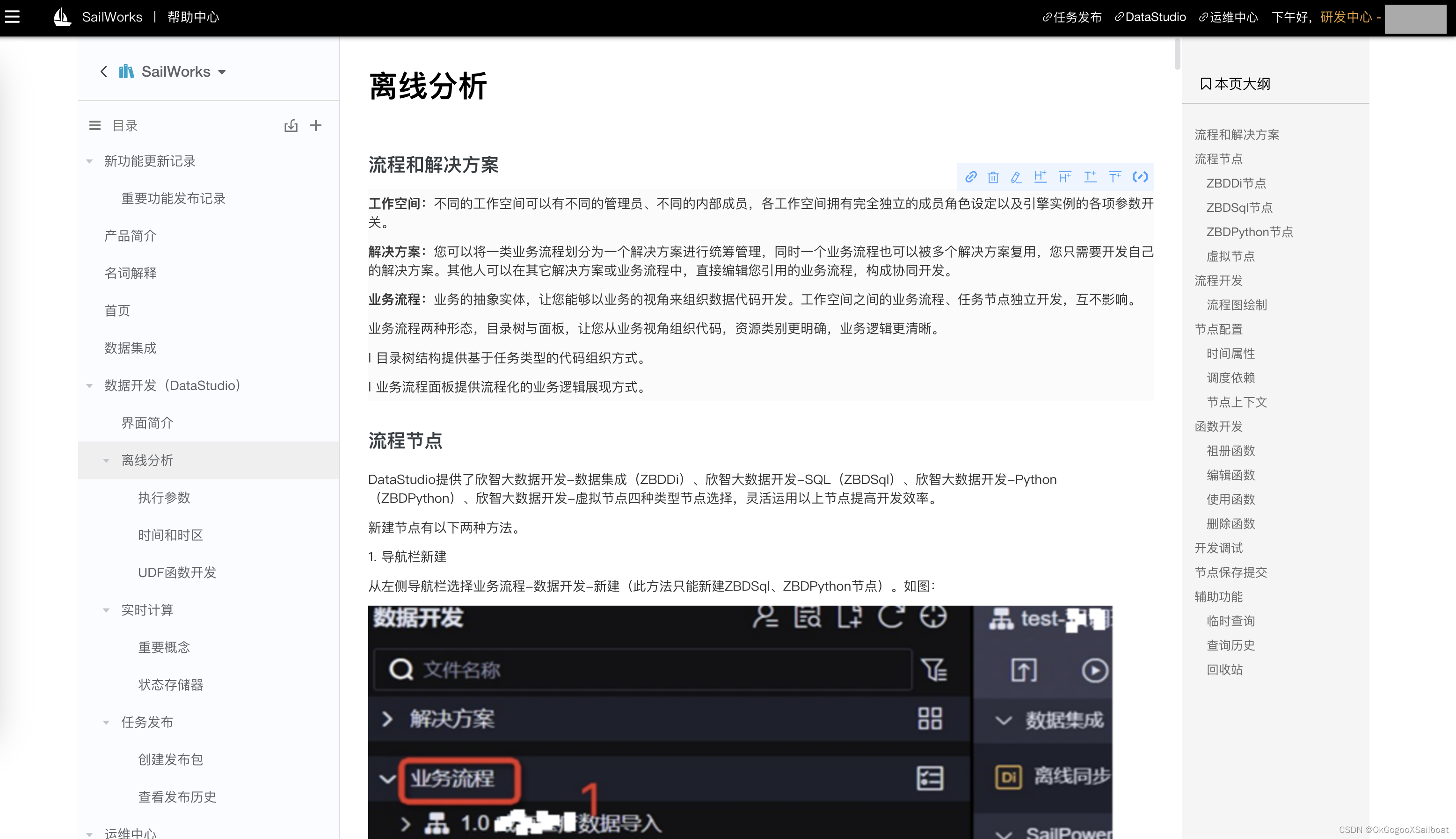
XSailboat是我们开发的一个主要建立在 Hadoop 生态及SpringCloud解决方案之上的全栈式的大数据开发套件。其中包含数据集成(SailDI) 、数据开发(DataStudio)、任务运维(SailTaskOps)、数据服务(SailDS)、API网关(SailGateway)、数据可视化(SailDV)、认证中心(SailAC)、在线文档中心(SailDoc),平台运维中心(SailCockpit),应用引擎(SailAE) 、指标建模(SailIMS)、数据地图(SailMap)、消息中心(SailMsg)、XTaskWorks(定时工作任务)。其中的数据集成、数据开发、任务运维共同组成了数据工厂(SailWorks)。数据工厂支持离线分析和实时计算,后续还将整合TensorFlow深度学习框架。
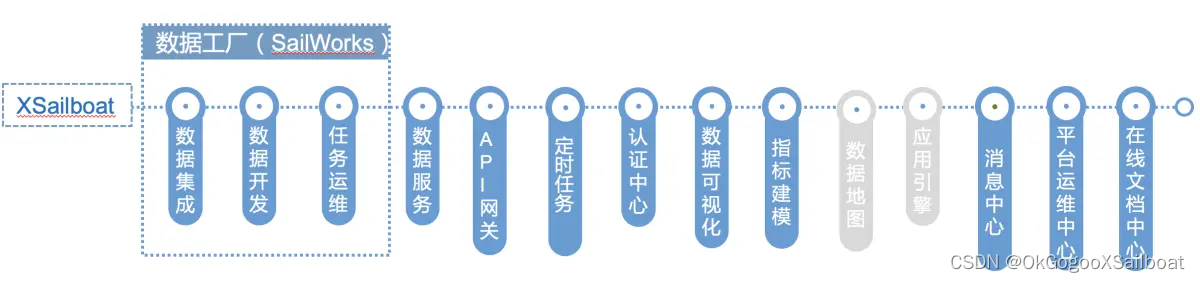
- 数据集成(SailDI)。从功能需求上来说,数据工厂的DI节点,实时计算管道,XTaskWorks的任务都具有数据集成的能力,共同组成了平台的数据集成能力。但这里说的数据集成功能模块,主要是数据源的定义,和数据源数据的查看浏览功能,对于内部数据源,亦可以进行维护。数据查看功能支持各种数据源上数据的查看。因为大数据平台的设计目标就是提供一站式解决方案,所以并不想用户查看平台支持的数据源,还得去使用其它工具。
- 数据开发(DataStudio)。DataStudio是大数据平台的可视化开发环境,提供离线分析业务流程、流式计算管道、和深度学习数据分类模型训练和应用的开发功能。DataStudio是数据开发环境。开发测试好之后,可以吧流程、计算管道、模型提交到生产环境部署。
- 任务运维是数据工厂的生产环境运维工具。
- 离线分析流程。可以重跑、冻结离线分析的流程,补数据、查看节点的历次执行日志等。
- 实时计算管道。可以查看计算管道的状态数据和日志信息,停止或重新部署其在某一个Flink集群上的Job。
- 深度学习模型。未具体设计,暂留空。
- 数据服务是基于SQL+Aviator的接口开发工具,可以实现快速的接口开发、测试和发布。无需传统的在IDE中开发、测试、打包、发布、部署过程,实现数据快速发布,敏捷响应。
- API网关是平台众多中台微服务接口的发布平台,提供接口的安全访问控制。同时具有流量监控、多实例服务负载均衡、API文档生成导出、服务可用性监测等功能。
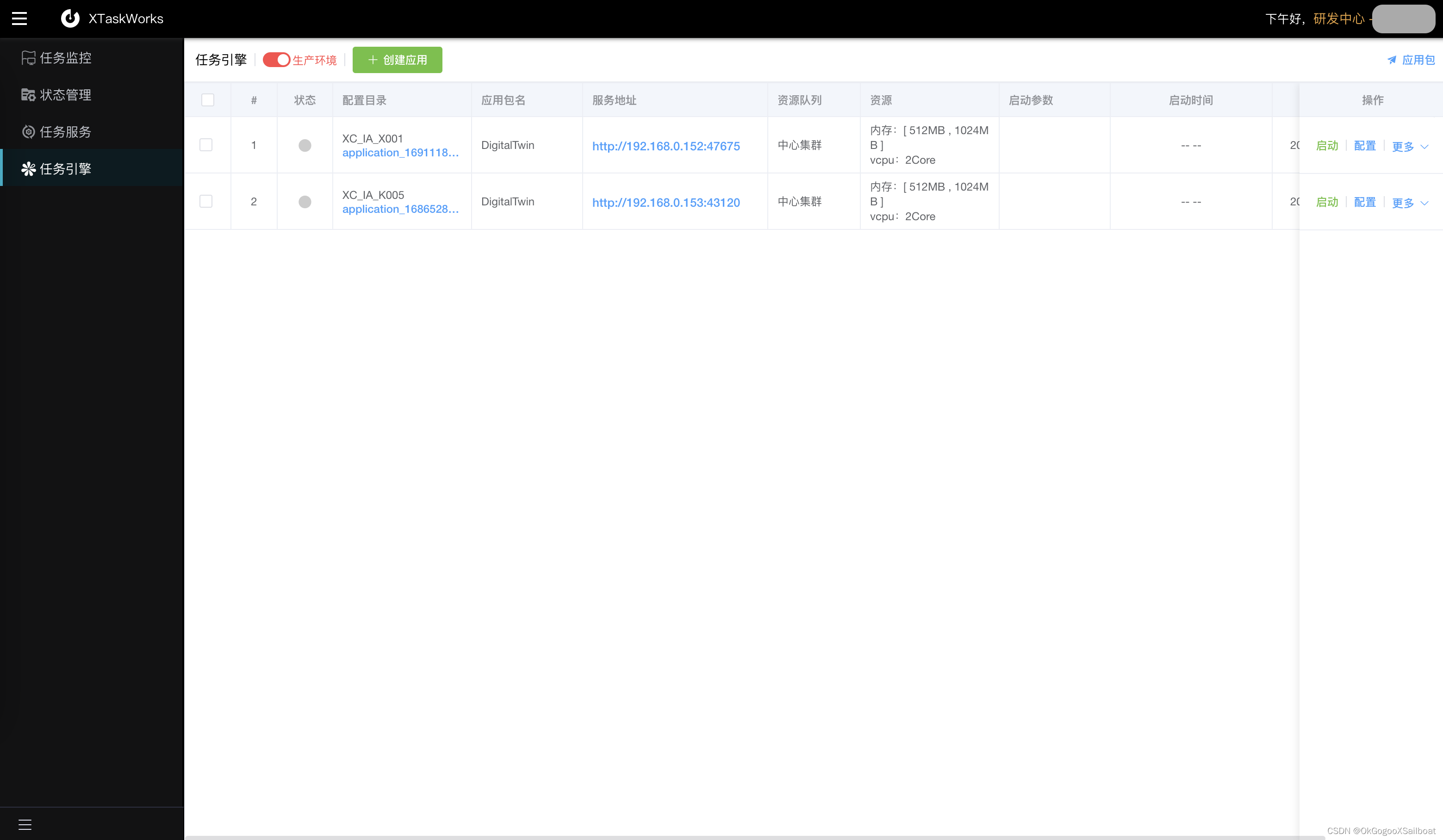
- XTaskWorks(定时任务)。是一个基于XTFrame框架开发的定时任务的监控管理平台。XTFrame是笔者早年间开发的一个工作流定时任务框架,现把它移植到大数据平台,并进行相应的升级改造。现已经开发出任务引擎,使任务能基于Yarn容器灵活部署运行,让部署、管理几百个定时任务也不是问题。后续将在此基础上开发出配置、部署更友好的ETL工具。
- 认证中心。大数据平台的所有前台WEB系统都接入认证中心,使大数据平台的众多web微服务能实现单点登录,无障碍跳转,让用户意识不到大数据平台是有十几个web服务在提供支持。认证中心基于OAtuh2.0实现,其中部分细节做了调整,主要是
- 将将资源服务器和认证服务器合二为一,
- 提供通用的用户、角色、权限模型,让web服务能寄存自己定义的角色和权限,利用认证中心工具实现用户、角色、权限配置,可以让web服务无需开发角色、权限管理工具。
- 提供子空间的概念,让具有类似工作空间概念的web服务,能把权限细化到其中。
- 数据可视化。我们的数据可视化和常见BI工具不同,我们以可分享的图表作为基本元素,仪表板和大屏是以这些图表为基本元素按一定布局组合而成。图表、仪表板和大屏也具有开发环境和生产环境。图表的分享链接上有可调参数,让用户选择风格、控制查询参数等。
- 指标建模,是一个定义指标,通过指标查看数据的工具。想要了解更多,可以查看笔者的另一篇文档《指标建模》。
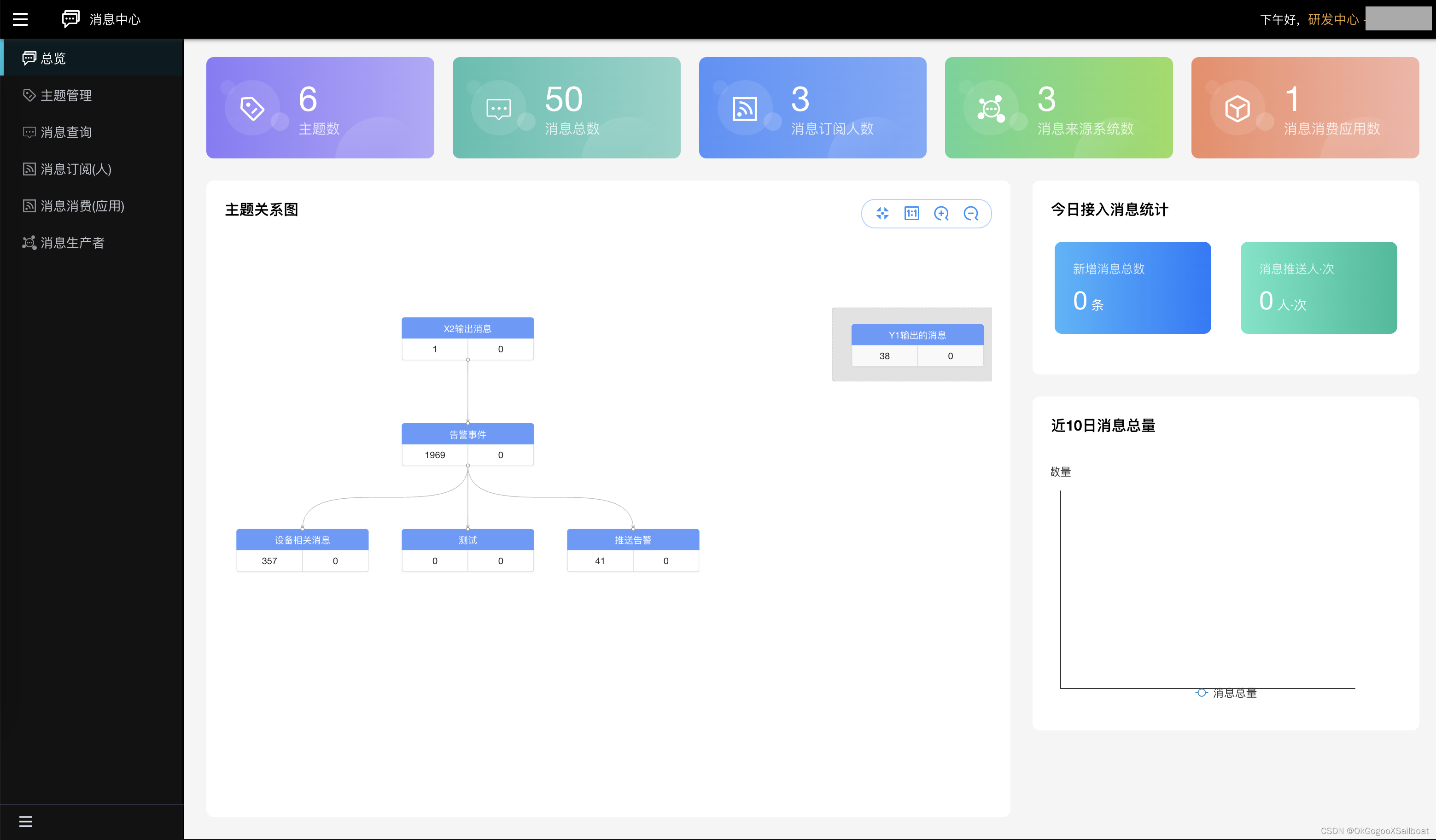
- 消息中心。它是一个实现消息按主题管理,并且通过配置输入源(另一个主题+消息过滤器),让消息在主题之间流转,实现消息的抽取、合并,组织成新主题,以满足用户个性化的消息订阅需要。应用可以通过订阅Kafka主题,或通过接口查询消息中心的接口,得到消息。自然人用户,可以通过消息订阅,把自己关心的消息通过钉钉、工作通知、短信等形式推送到自己的终端上。消息订阅支持消息的进一步过滤、在指定时间窗口发送(指定时间段免打扰),支持消息聚合发送。
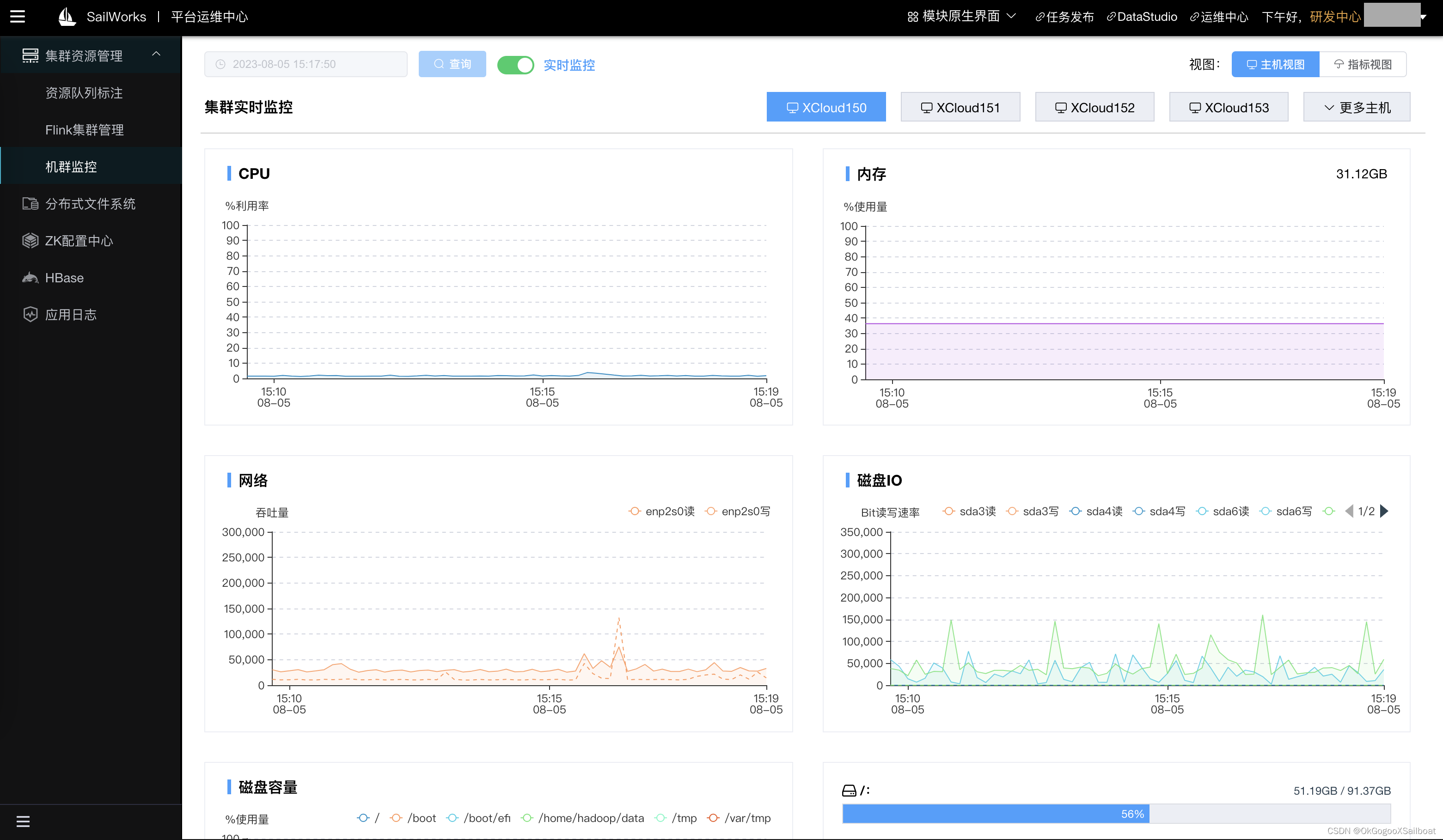
- 平台运维中心。是平台的管理工具,支持集群资源监控,平台服务日志查看、HDFS文件系统浏览管理工具、ZK配置中心、Flink集群管理和扩展Jar包的更新管理界面,YARN资源队列标注、HBase数据查看和管理工具等。目标是在平台运维中心几乎解决所有日常的运维工作。
- 在线帮助中心。提供在线文档的编辑和管理功能。在其中提供在数据平台上进行开发所需的所有专业知识讲解和培训资料。平台中很多模块中面板上的“?”都应用在线文档中心某些文档的段落。
- 数据地图。它为开发人员和业主提供一站式总体上了解平台管辖有哪些数据以及数据规模的工具。为开发人员提供离线开发所得到的数据表血缘关系展示图。
- 应用引擎。应用引擎是为了通过容器化部署+负载均衡服务,解决微服务众多所带来的部署、维护、更新工作繁重的问题,并提供服务的不停服更新能力、实例运行监测和服务不可用自动重启能力,提升服务的可用性指标。
XSailboat的核心思想是提供下图的一种大数据解决方案,所有模块都直接或间接服务于这个核心思想。
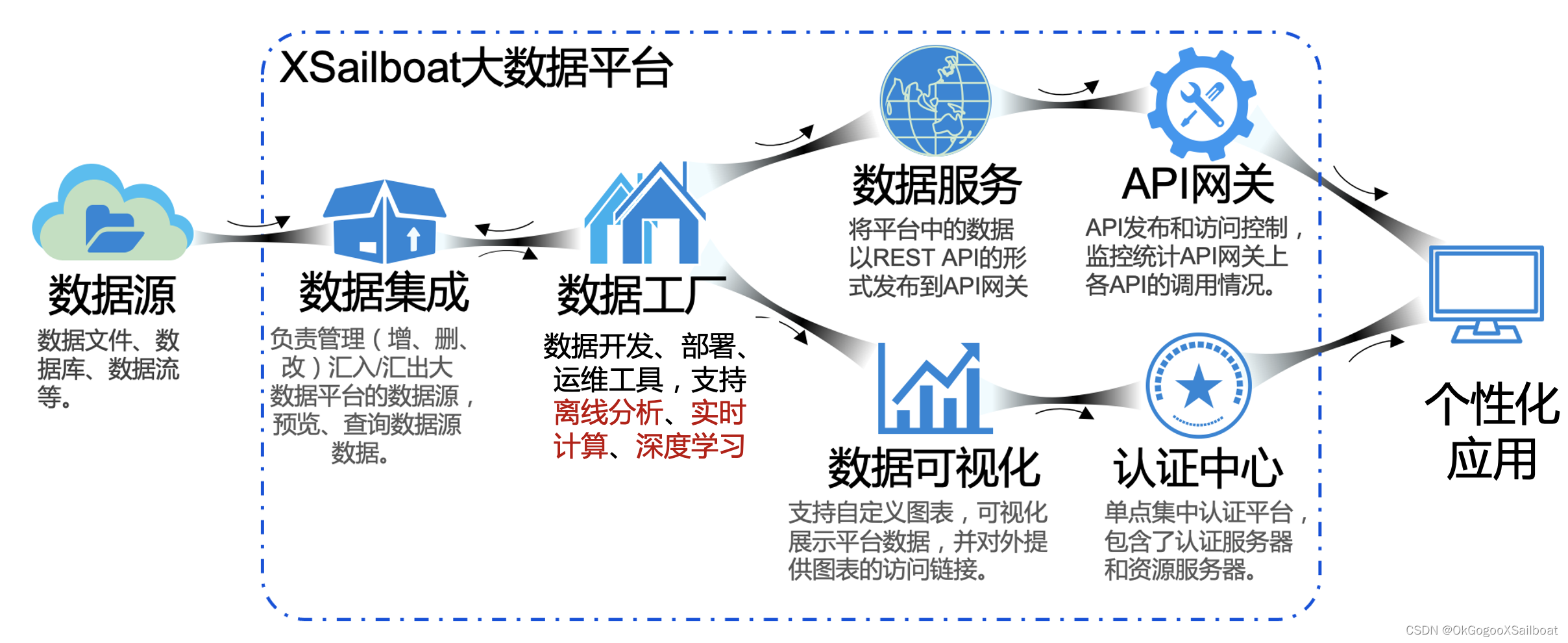
以这个解决方案为核心,逐渐从图中直接列明的模块扩展延伸出更多的模块:
- 因为微服务数量太多,所以增加应用应用引擎模块;
- 因为大数据平台那么多主机和基础实施、所以需要平台运维中心提供监控、管理能力。
- 因为基础实施、软件模块多,尽管可以借助运维中心等进行人工巡检,但不可能实时盯着系统,为了当出现问题时能及时发现并解决,所以增加消息中心,以支持自动化运维。
- 因为大数据平台模块和功能众多,需要专业知识及熟悉大数据平台的使用,所以提供在线文档中心,以提供文档资料、培训视频和教程等。
- 因在生产环境数据集成的复杂性,有非常多个类型的定时计算需要,所以提供XTaskWorks做定时同步、计算和ETL。
- 因数据开发通常需要预先梳理、定义指标,数据开发完成之后需要将数据和指标对应,所以提供指标建模工具。
3. 架构
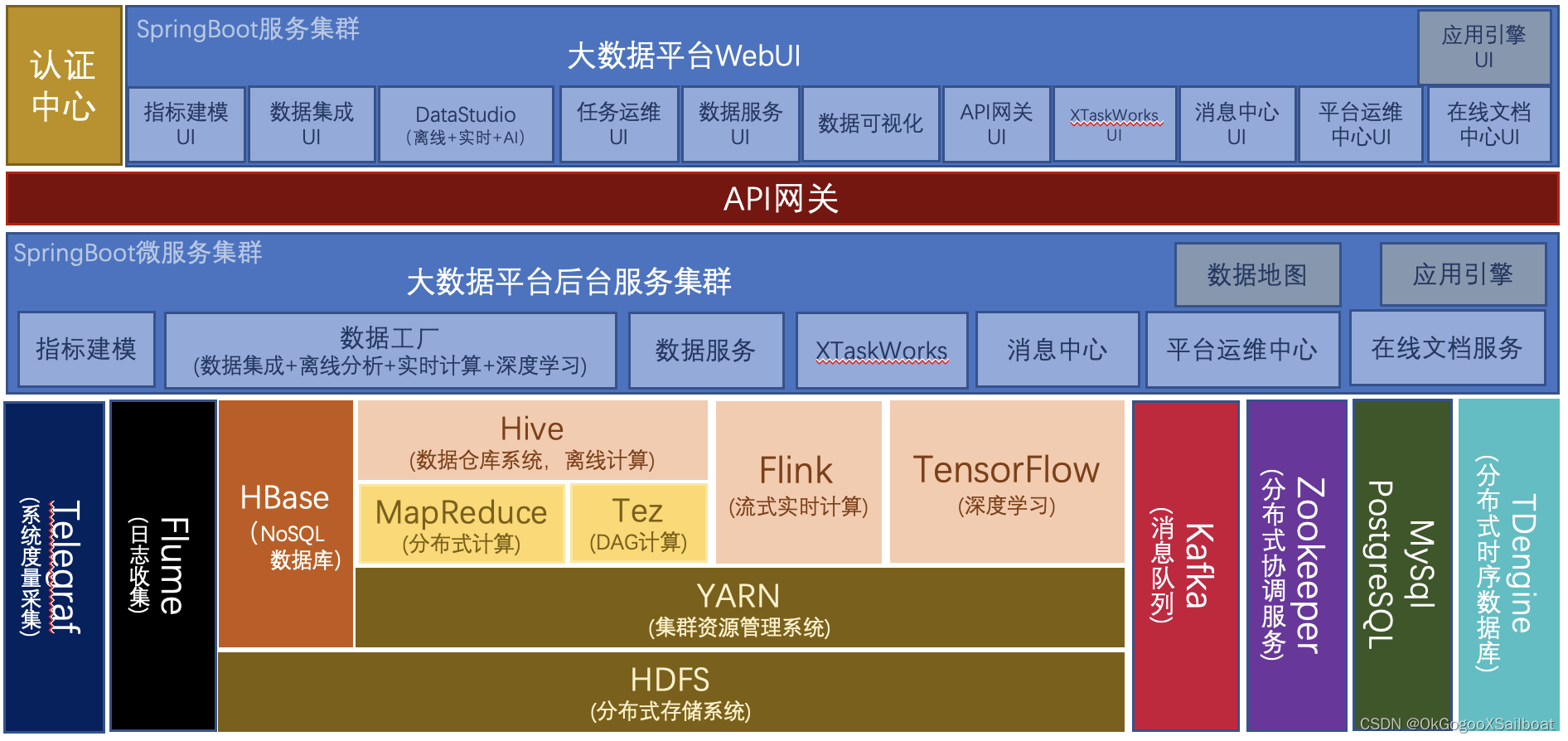
- Hadoop生态是XSailboat的关键基础设施。
- Spring是XSailboat的关键开发框架。
- 使用Hive+Tez/MapReduce作为大数据平台的存储和计算引擎。另外自己开发调度引擎和基于Python的执行引擎。使用Python开发执行引擎是数据工厂的离线分析功能的重要核心构建。这使得用户可以在DataStudio中使用Python基于执行引擎的SDK进行脚本开发,调用数据访问接口,实现循环、异步执行SQL、引入DataFrame框架等高级离线分析功能成为可能。
- 使用Flink作为流式计算的框架。我们在数据工厂中实现可视化的计算管道开发和运维功能,提供Flink集群的容器化、自动化、多集群部署功能。让实时计算更易入手,更易管控。
- 使用TensorFlow作为深度学习框架,在数据工厂中借助可视化的界面,辅助神经网络的搭建、超参数的设置和模型训练。对于训练好的模型,支持提交到生产环境,容器化部署应用。(尚处于规划中的功能)
- 使用Flume采集平台中的各个微服务的日志,存储到HBase中,在平台运维中心可以通过界面查看各个服务的实时日志。
- Kafka对于实时计算和消息中心,都是关键性必需的基础设施。
- 我们使用Zookeeper作为配置中心和分布式协调中心。在平台运维中心,开发有分布式“ZK配置中心"模块,可视化浏览、配置和管理ZK配置。
- MySQL和PostgreSQL用来存储系统数据。之所以会使用到两种类型的库,是因为笔者最初主要是使用MySQL数据库,后来在平台开发过程中,有几个模块需要使用模糊搜索功能,所以引入了PostgreSQL,配合bigm插件实现搜索。
- TDengine作为时序数据数据库使用,存储平台的各种度量数据。之所以使用它主要是因为项目中极有可能会遇到超大规模的时序数据,有可能是TB甚至PB级的,用国产关系数据库很容易遇到瓶颈。用时序数据库,不仅可以大大节约存储空间,而且查询效率也更好。TDengine作为一个国产开源时序数据库引入进来,作为一个试验型的数据库使用。为遇实际项目大规模应用做技术验证和准备。TDengine有开源版和商业版,如果项目经费允许,最好还是用商业版(但挺贵)存储业务数据,商业版有技术支持,能有更好的稳定性。
- Telegraf用来采集平台集群主机的度量数据,包括内存,CPU使用率、网络、磁盘使用率等度量。在平台中心开发有平台主机监控界面。
4. 各模块一览
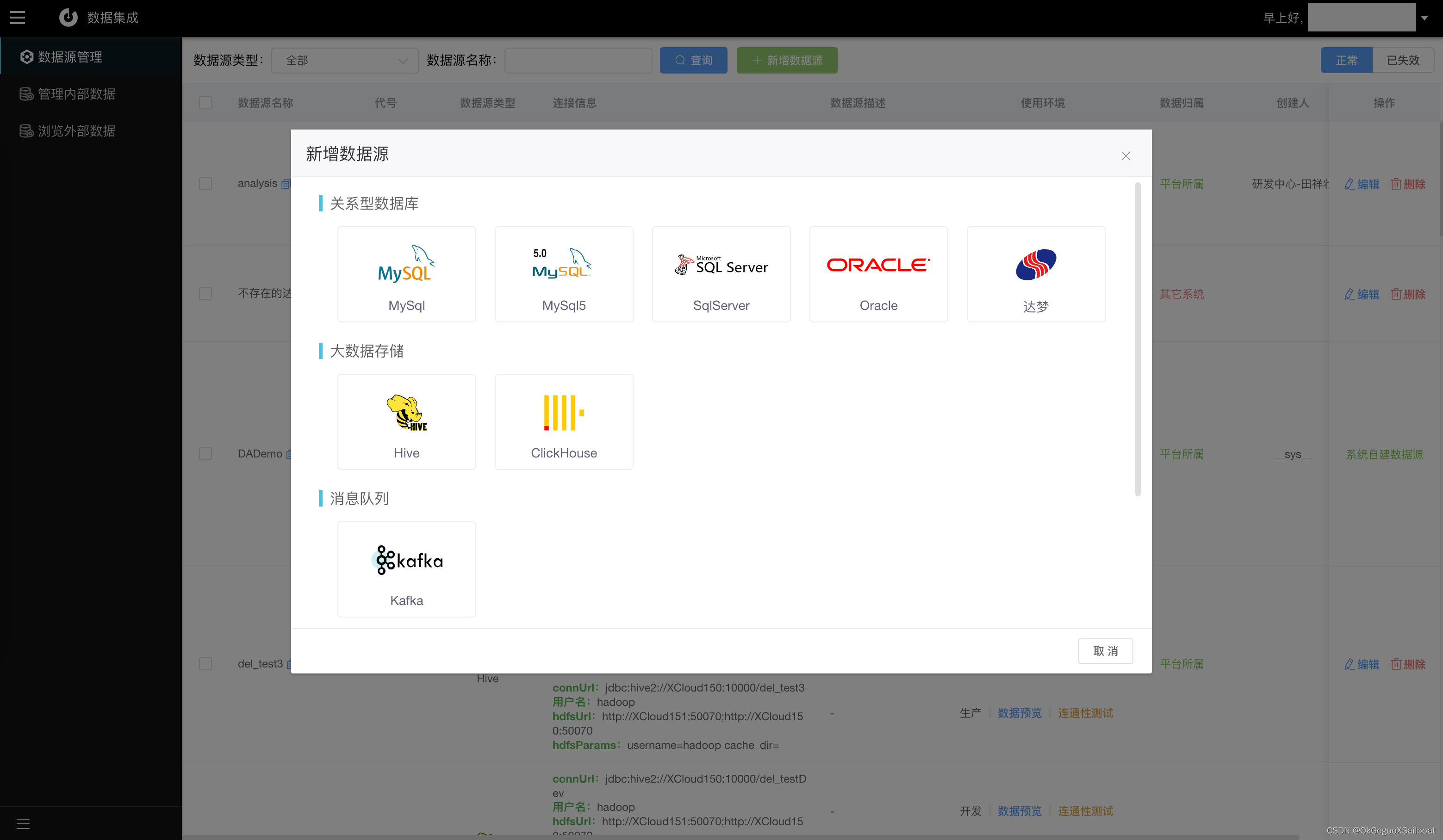
4.1 数据集成
4.2. 指标建模
待补充
4.3 DataStudio
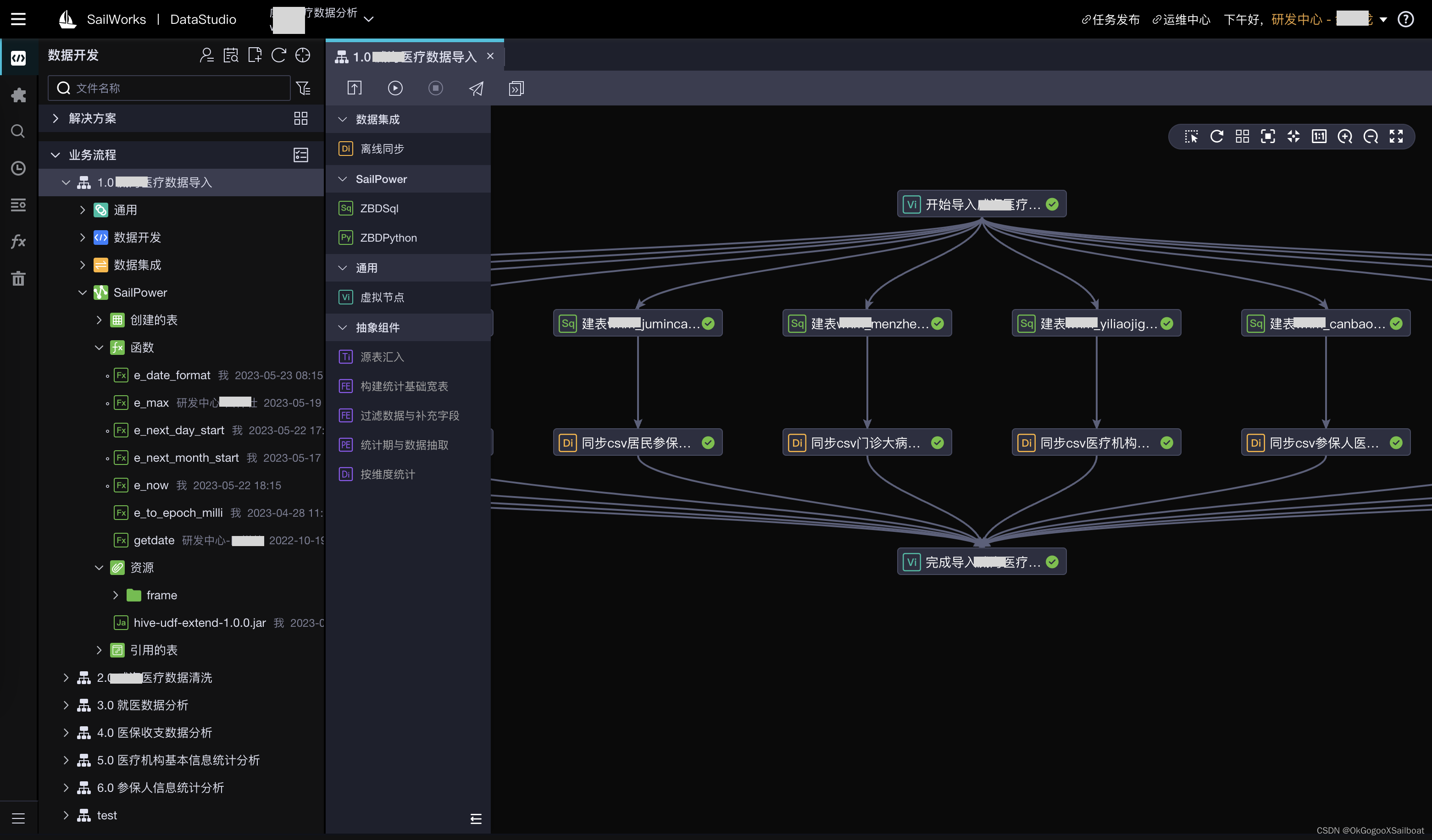
4.4 任务运维
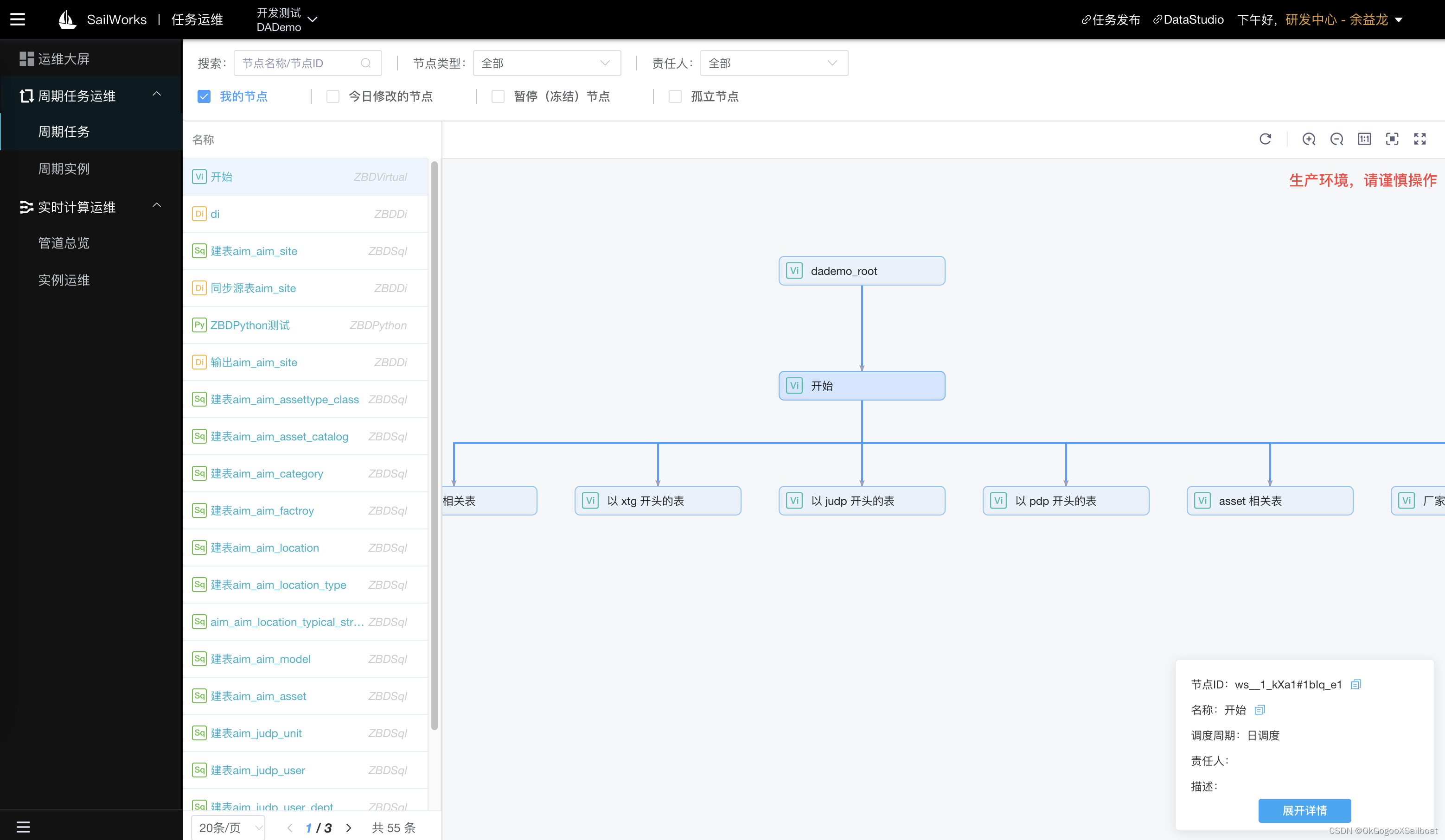
4.5 数据服务
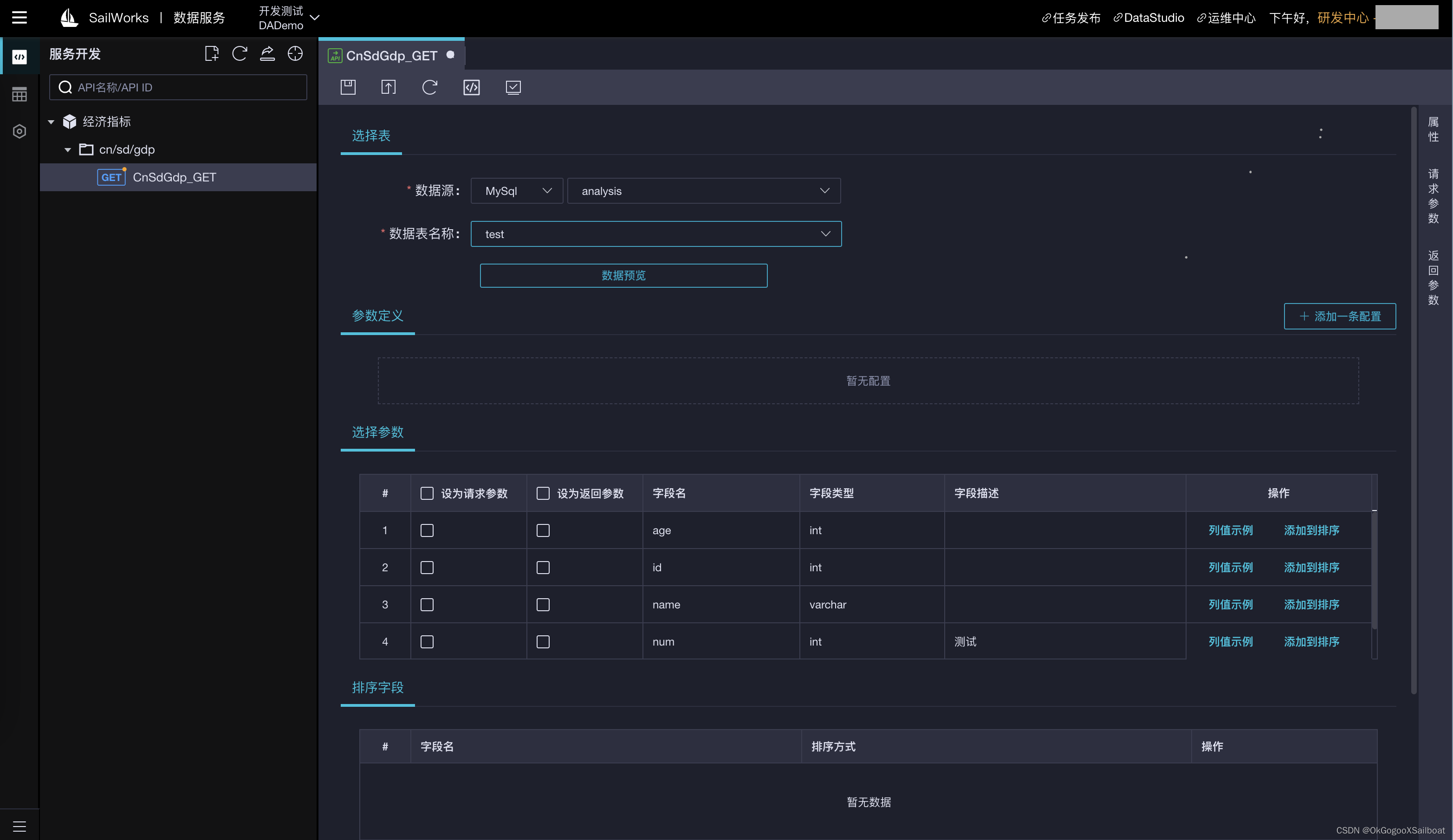
4.6 API网关
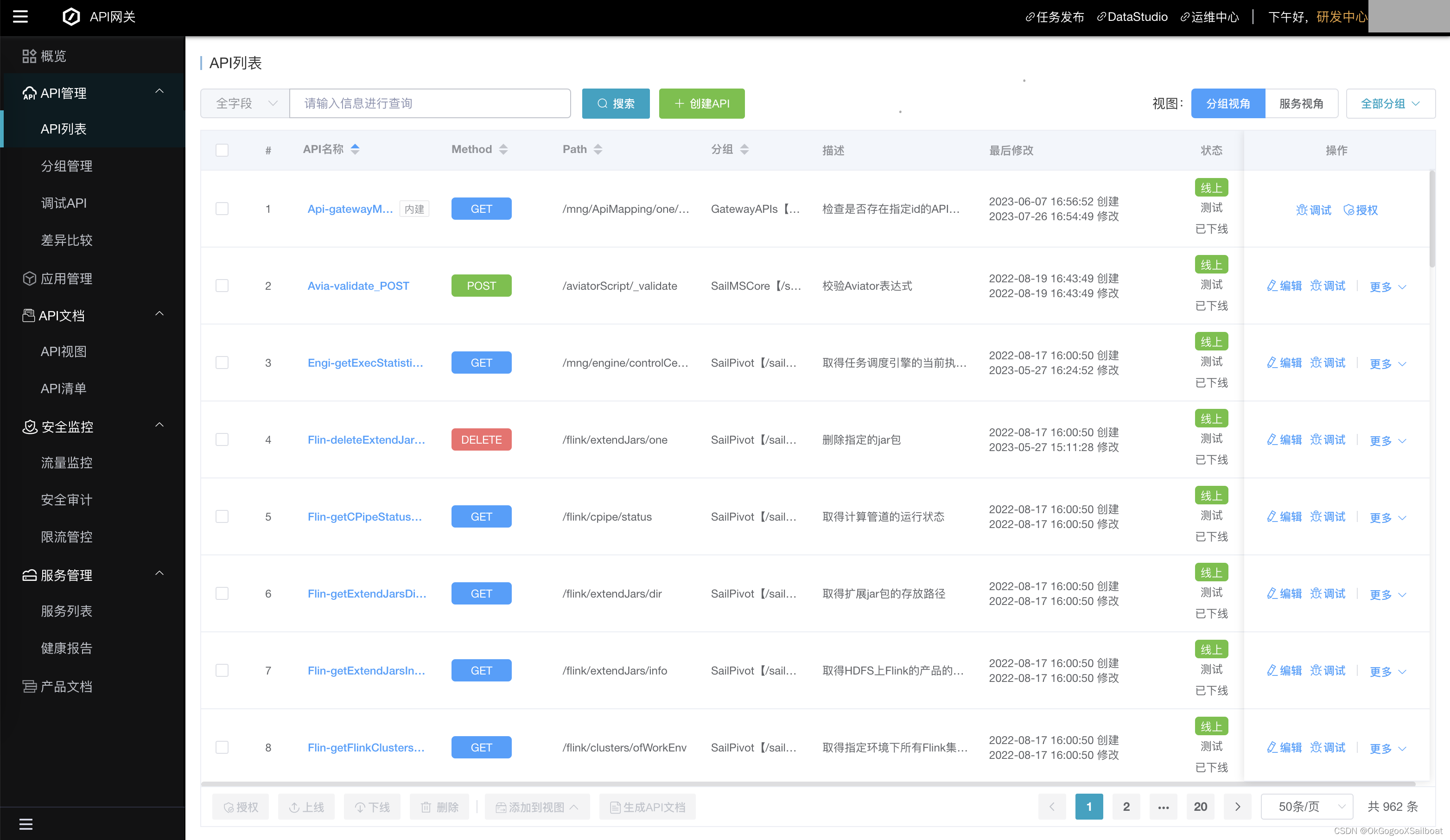
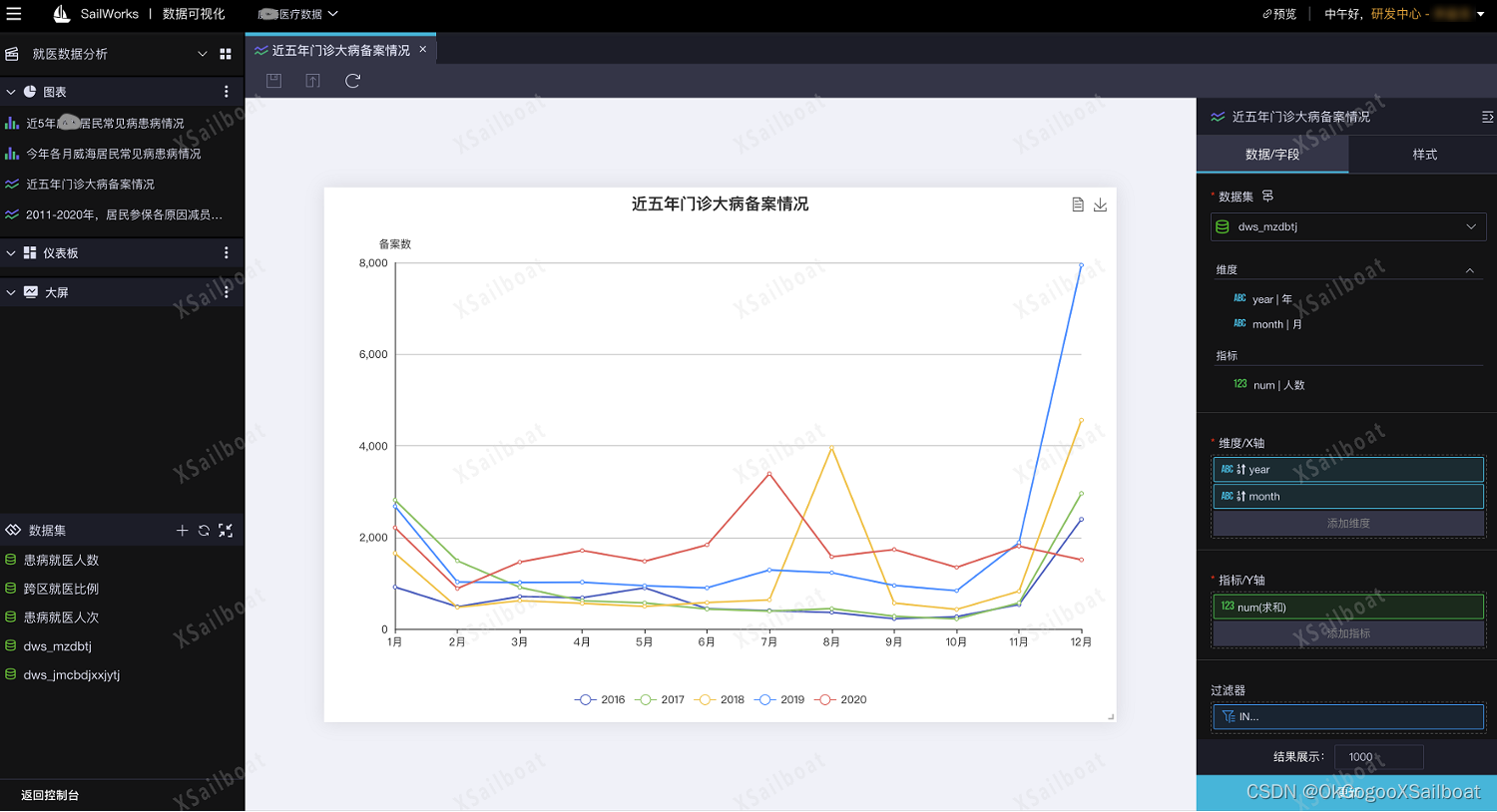
4.7 数据可视化
4.8 XTaskWorks
4.9 消息中心
4.10 平台运维中心
4.11 帮助中心
4.12 数据地图
规划中
4.13 应用引擎
规划中














 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









