







1. 何为数据治理
数据治理是为了让数据在形式上和质量上更好地达成某一数据应用目标而进行的数据集成、数据整理、数据分析、数据修缮、数据发布,数据应用的过程。
2. 为什么需要数据治理
数据治理平台通常不是源端的数据生产者。政府和大企业通常有非常多的信息系统,这些信息系统往往有不同的厂家,在不同的时期建设,数据的存储方式和形式一般由厂家根据业务需要自行设计。数据模型在整体层面上缺少统一规范的顶层设计。当有的业务需要跨系统进行数据整合应用时,往往都需要相应的项目承包商,自行处理,而这过程中通常会出现各种各样的问题。例如:
a. 编码方式不统一,同一对象在不同的系统有不同的编码。
b. 命名不统一,虽然人通过语义和层级结构理解,可以知道是同一个对象,但因为字符顺序和字符上有些许差异,不能用字符串equals比较。
c. 字段缺失。对某一业务来说是必需的,但在源系统里面,它可能只是一个非必填的边缘字段,有的对象设置了,有的对象没有设置。
d. 字段值单位和设值不规范。例如在源系统中,有些字段可能只是为了展示,所以只要用一个字符串,人能看的懂,中文名称或西文字符单位都可能出现,中间有空格等等。但是在用在计算的时候,单位和格式就不得不统一
e. 不同来源的数据连接不能很好对齐。就像需要连接两根光缆似的,有的光纤能连上,有的连不上,有的又似乎能找到对应的连上,但又不是很确定。
f. 不同来源的同一对象,同样含义的字段,取值不一致。
数据治理就是源系统和个性化业务系统之间的中间层,基于底层不同的源系统,为上层多个业务系统提供形式统一、质量更好且完备的数据。如下图所示:

从数据治理平台的这个定位来看,其实数据治理平台应该尽量和数据仓库、数据集市、数据中台等设计统一协调起来,避免重复设计,冗余开发。(可以关注了解一下我们的大数据平台 XSailboat 的功能)
这样可以避免各个上层业务系统独自对接底层系统。这样至少具有以下好处:
a. 各个业务系统厂家不用自己找各个源系统厂家对接,减少寻找业务人员沟通的时间成本。
b. 各个业务系统厂家只需要对接数据治理平台,减少了对接和数据获取的工作量和难度。
c. 由数据治理平台统一处理,极大减少了各个厂家各自整合数据、规范化数据、处理异常数据的工作量,可以更快推进业务系统开发落地。
d. 由数据治理平台提供统一形式的,处理过后的数据,数据的一致性将会更好。统计计算结果在各个业务系统中的数据一致性将会更好。
3. 数据治理的架构和过程
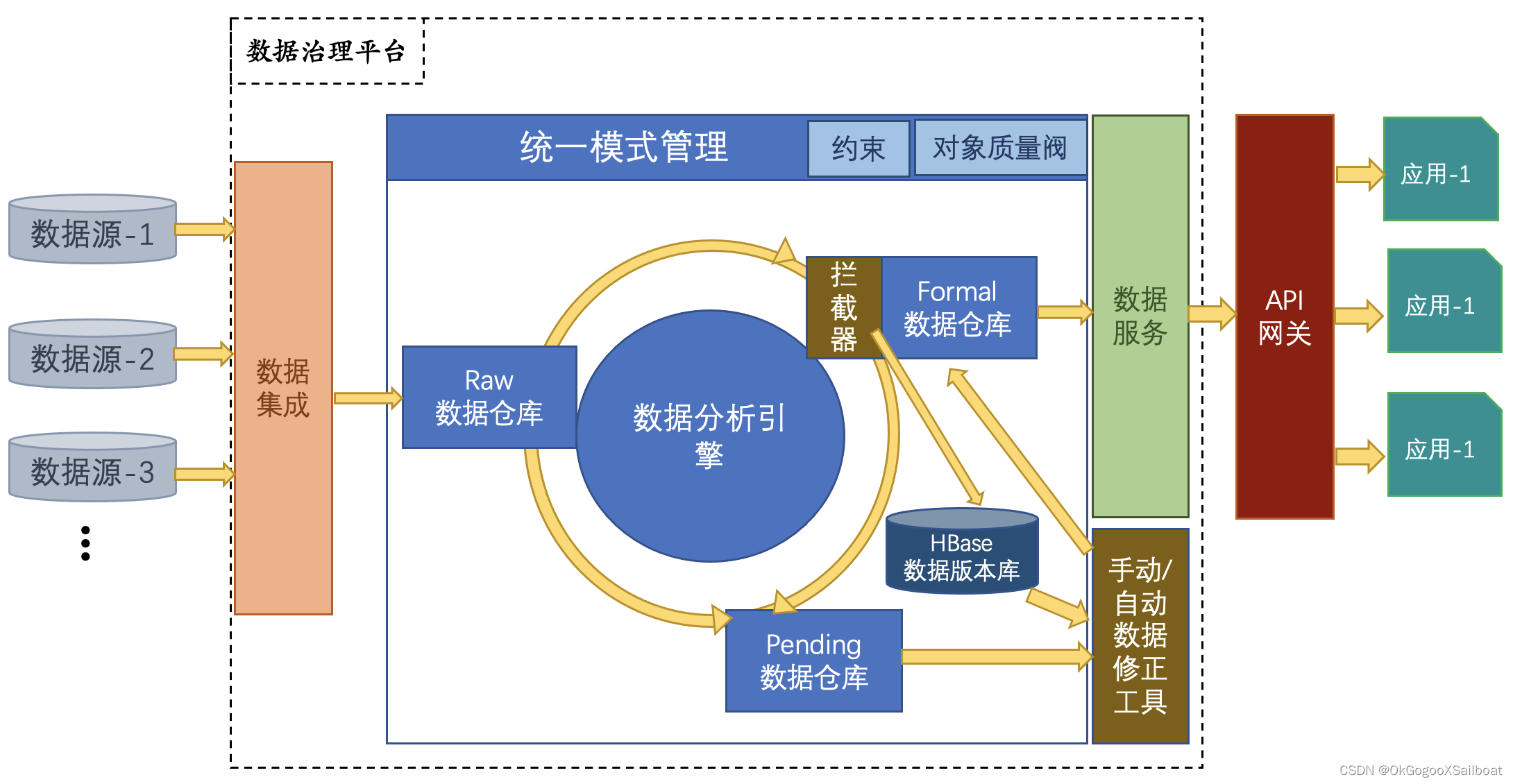
首先数据治理的关键是要有统一的模式设计,能覆盖将要接入到数据平台的各类型数据,并且能合理地描述各类对象之间的关联关系。模式设计的基本原则是:从领域内的事物本质出发,以兼容业务需要为考量,回顾底层数据对模式的支撑性。这种支撑性指的是当前能拿到的各类型数据,是否能转换成当前设计的模式形式以及转换过来的结果质量如何。避免造就一个理想化模型,以致数据无法填充,业务需求无法满足。
数据治理的主要过程是:
整合–>分析–>修缮–>发布。(分析和修缮的过程可能需要循环进行)
为了支撑起这个过程,需要有“Raw数据仓库”、“Formal数据仓库”、和“Pending数据仓库”三个数据仓库。这三种数据仓库都受统一模式的约束,符合模式的设计要求。它们的底层数据库技术可以不一致。一个仓库也可有有多种类型数据库共同组成。一般有以下几种类型的数据库可选择(不同类型数据库有不同的特性,结合开发技术、数据写入和查询要求选择):
- OLAP型数据。例如Hive、MaxCompute等。
- 传统关系型数据库:例如MySQL、PostgreSQL,DM(达梦)等
- 时序数据库。例如 TDengine,InfluxDB等
Raw数据仓库,存储的是通过数据集成任务整合、经过初发规范化和修缮的的符合统一模式的生数据。
Formal数据仓库,存储的是经过数据分析确定符合输出条件的数据。
Pending数据仓库,存储的是经过数据分析,发现不符合输出条件,待决的数据。
数据分析引擎基于统一模式上定义的约束,对数据进行分析。每条约束都有以下信息:
- id
- 名称
- 范围(scope)。有三种形式:
a. 类名。表示约束针对的不是单个属性,而是多属性。如果约束不成立,将描述为某个对象不满足某个约束要求。
b. 类名.属性名。表示约束针对的是单个属性。如果约束不成立,将描述为某个对象的某个属性不满足要求。
c.空。表示约束是针对多类型的对象综合判定。可以认为它是全局性的,避免这种约束绑定在多个类上,造成多次重复分析。 - 数据集(数据查询方式)
- 数据判定条件。
- 顺序(order)。缺省都是1,顺序小的先开始分析;顺序相同的,可以并行,无所谓先后。
- 是否是强约束。如果是强约束,当强约束不成立时,即时对象数据质量阀决定放行,这个对象会输出,但这个属性不会输出。不会输出的意思是,当目标数据库存在这个对象时,不会去更新这个属性,如果原先对象不存在,则新建对象此字段会留空。
数据分析引擎根据全局的、类上的、属性上定义的约束进行分析规则进行分析。判定约束条件在各个对象上是否成立。
Raw数据仓库的数据是否可以流转到Formal数据仓库,首先需要经过数据分析,得到结果后由数据对象质量阀来判定。数据质量阀是一条规则链,由判定规则组成,最后是一个最终缺省判定。每条规则有一个判定目标(拒绝或允许),第1条成立的规则,它的判定目标是拒绝还是允许,就是数据质量阀对这个对象的判定。当所有规则都不成立的时候,最终缺省判定将作为对象数据质量阀的最终判定。一般都是允许。得到允许的对象将流转到Formal数据仓库,得到拒绝判定的对象将流转到Pending数据仓库。对象质量阀的判定依据是约束条件的执行结果。例如“A.约束1 && A.约束2”
数据在进入Formal数据仓库的时候会经过一个拦截器。拦截器主要是为了获得Formal仓库的增、删、改操作,以在HBase数据版本仓库写入对象的新版本数据。属性变化了,才记录。如果用Formal仓库存储数据,则可以考虑使用BinLog机制获得数据的增、删、改操作。
之所以要使用HBase数据库作为对象版本记录数据库,是为了使用HBase的字段值多版本记录的特性。
手动和自动数据修缮工具可以利用Pending库中的数据和对象版本库中的数据,修缮数据。修缮之后,写入到Formal仓库。数据分析引擎也会分析formal仓库中的数据,当质量不满足对象质量阀要求时会将它从Formal数据仓库流转到Pending数据仓库。经过修缮之后再写入Formal仓库。
Formal数据仓库的数据,通过数据服务对外发布。
4. 如何解决自动同步和手动修缮数据的被覆盖的问题
当数据不符合对象质量阀的要求,被输出到了pending仓库,人工修正以后,写入到了Formal仓库。下次数据同步分析,如果数据符合对象质量阀要求了,那这个人工修缮后的数据是该被覆盖,还是被保留?
这其实应该取决于修缮数据的人。他可以有两种选择:
- 如果他觉得他修缮的数据是标准的最终答案,那么可以锁定对象或属性,不允许被覆盖;
- 如果它觉得源端只要改成符合他的某种检查规则,那么就采用源端的。
这两种选择其实都可以用约束来表示。锁定一个id为123的对象的属性,可以定义一条针对某个对象的单属性强约束,它的判定目标是拒绝,:
id == '123'
第2种选择就是一般的强约束。














 1336
1336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









