






1. 背景
在我们的大数据平台XSailboat中的DataStudio中,提供了离线分析和实时计算的功能。
实时计算功能的计算引擎是Flink,我们提供了基于YARN容器,一键部署计算管道的能力。一个工作空间在生产环境下,可以运行有多个Flink集群。工作空间中的一条计算管道,可以部署到各个集群得到多个FlinkJob实例。
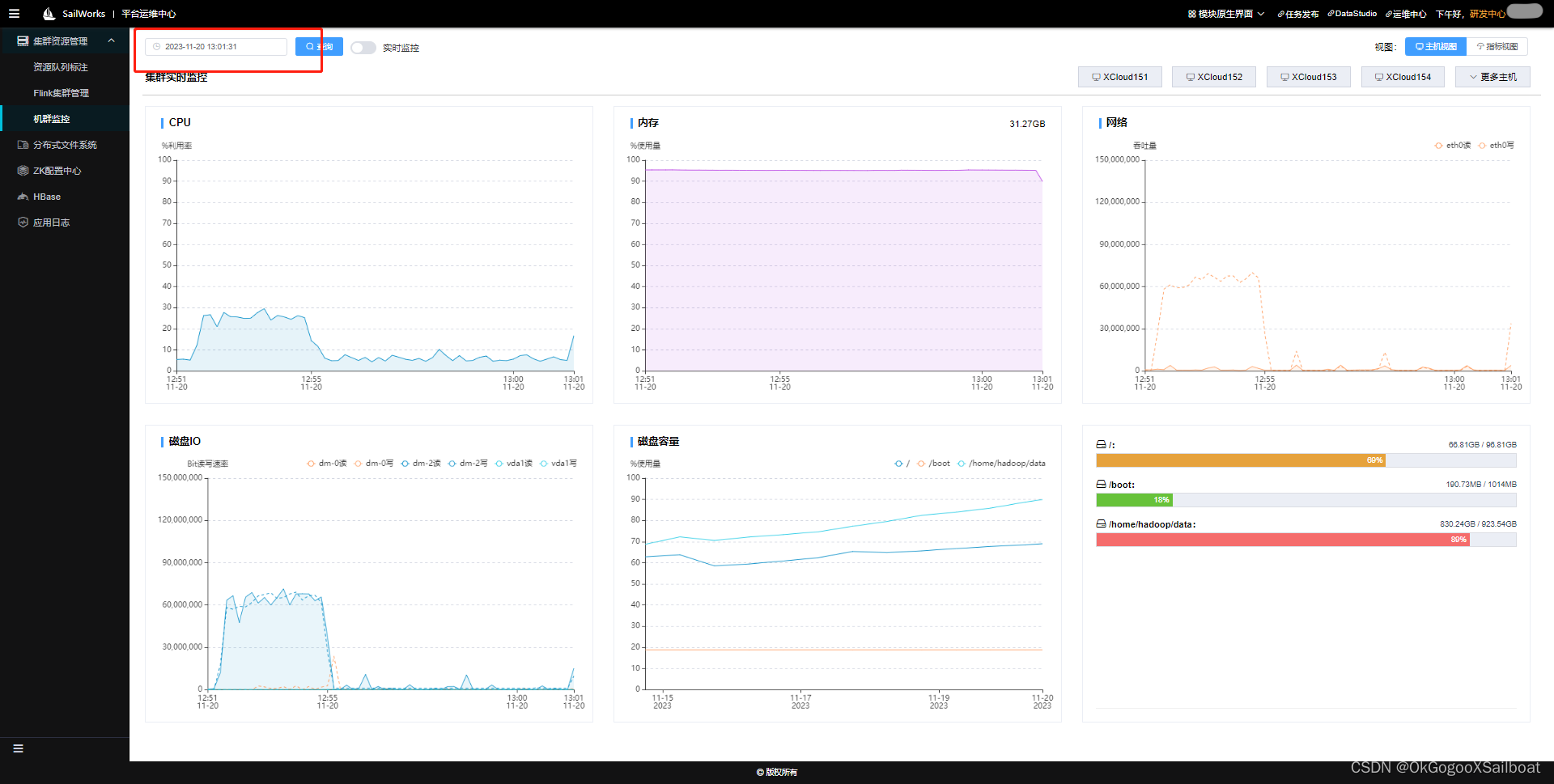
在我们的生产环境下,计算管道和集群数量都较多,在部署的时候,发现基本都在1两台机器上运行了Flink集群。而且这一两台机器还与另外一个运行XTask任务的YARN资源队列共享资源。所以造成一台机器的内存使用几近100%,最后Flink Job崩溃。
2 解决办法
主要从以下几个方面解决问题:
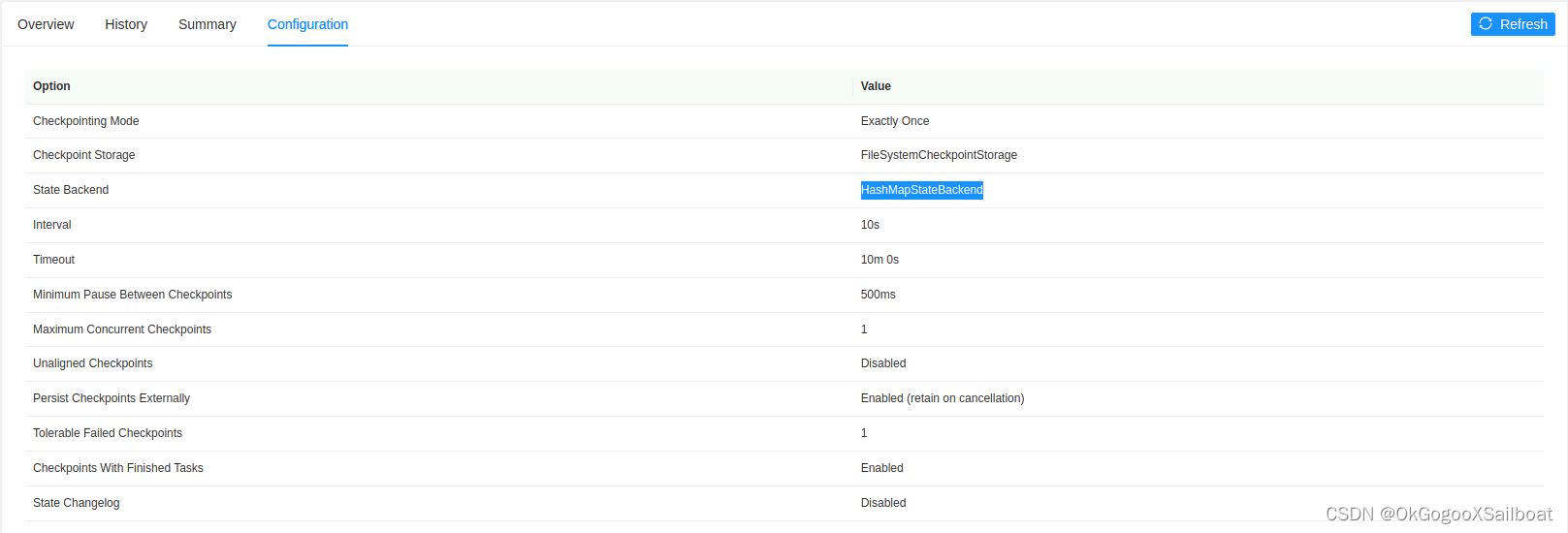
- 计算管道在部署到某个集群时,允许设定状态后端,但一般都不设置,使用集群缺省的状态后端。但检查配置后发现,集群也没有配置状态后端,使用Flink产品缺省的状态后端,发现使用了hashmap(内存)状态后端。在Job的检查点里面,可以看到当前Job使用的状态后端。
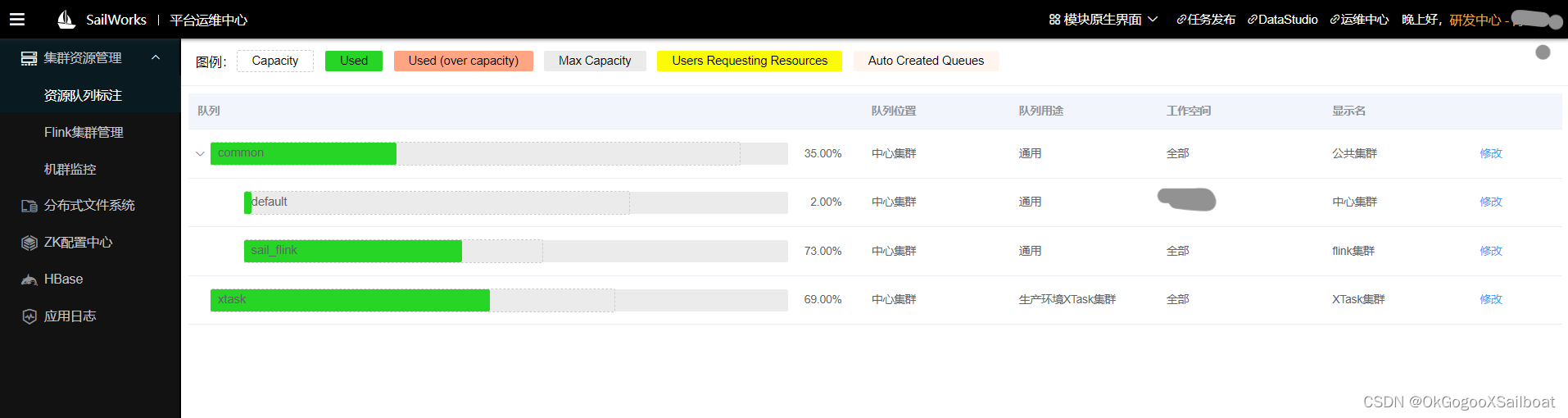
- 因为Flink有使用较多的堆外内存,如果Flink集群部署,有专门的资源队列,那么可以将这个队列的资源上限值调低一点,留出更多的内存裕度给Flink。如果这个资源队列还有其它用途,且部署的应用不怎么使用堆外内存,可能会使得内存利用率低的问题。我们使用的是CapacityScheduler,它建出用于Flink部署的子队列来是相对容易的,我们建出一个专用于Flink的资源队列sail_flink,将它在每台机器上的资源使用上限限定在50%,使得它在每个节点上都不会占用过多的内存,剩下的资源留给相对弹性的离线分析部分(MapReduce和执行引擎的动态容器需求)。
对于Flink的部署过于集中,FairScheduler是一种解决办法(参考:https://blog.csdn.net/nazeniwaresakini/article/details/105137788),Hadoop的官方资料《Fair Sheduler》 。但因为一直使用的是CapacityScheduler,在CapacityScheduler没有大的问题情况下,不想更换调整,带来不必要的风险和工作量。















 2166
2166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









