







【Spark案例】本地访问cdh集群不将配置文件放入resource目录方式
背景故事
今天我领导,他想用pyspark连接集群中的hive,作数据分析用。于是这变成了一个在本地集群中如何访问远程集群的问题。
在python环境中使用pyspark构建sparkSession的过程当中,config参数选项里面配置了一个hive.metastore.uris的时候,sparkSession能够访问hive的数据库,及表信息。但是读取数据的时候会发生报错。
问题分析
在java中
如果是maven构建的java项目当中,使用spark远程连接集群的话,需要在项目中的resource文件目录下面将hadoop的配置文件如hdfs-site.xml,core-site.xml,mapred-site.xml,yarn-site.xml文件放置进resource目录中。接下来运行的时候,maven会将这些配置文件打包到classpath中。然后源代码中,就会加载这些配置文件,相关的代码如下:
代码路径:org/apache/hadoop/conf/Configuration.java

在python中
那么python中没有似乎没有resource文件夹,好像也不能像java一样package,那么我们如何做呢?
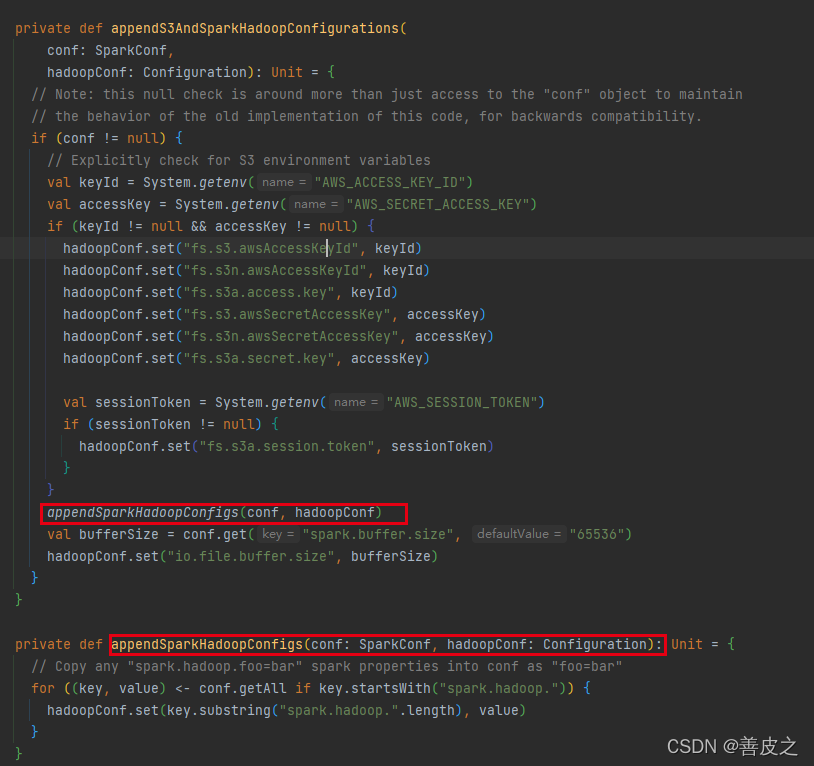
我们将里面这些xml里面的配置文件,用文本编辑器打开。提取出所有的键值对,然后在启动sparkSession的时候调用config(key,value)添加这些键值对,在每个键的前面加上spark.hadoop前缀,该代码写在这里:
代码路径:org/apache/spark/deploy/SparkHadoopUtil.scala
返回来的SparkSession就可以访问正常调用sql方法访问数据啦。
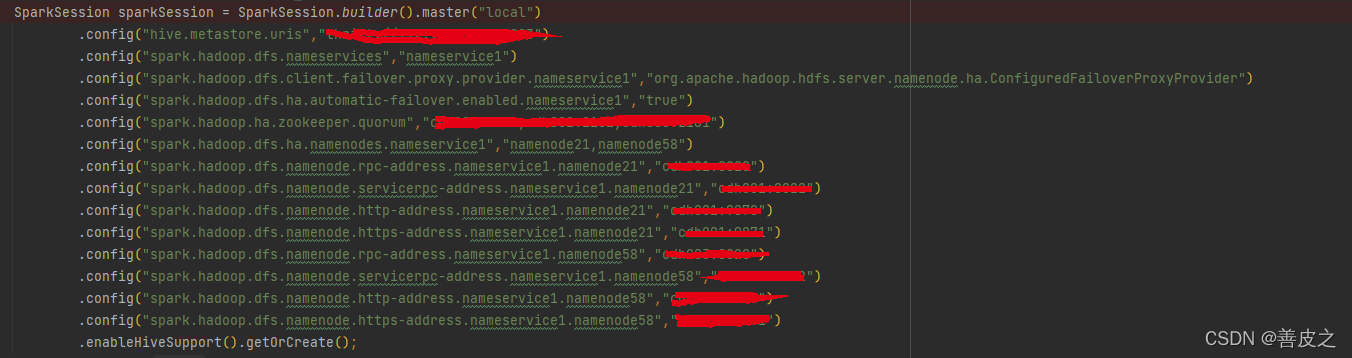
总结:
这样实现了不通过将core-site.xml,hdfs-site.xml文件就能够访问集群读取数据 了。如果各位路过的大佬有什么更好的方法,欢迎在下方留言!谢谢大家~














 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









