






 本文介绍如何将Python中Pandas库的DataFrame默认从0开始的索引调整为从1开始的方法。通过简单的代码示例,展示如何使用df.index = df.index + 1来实现这一需求,适用于各种数据处理场景。
本文介绍如何将Python中Pandas库的DataFrame默认从0开始的索引调整为从1开始的方法。通过简单的代码示例,展示如何使用df.index = df.index + 1来实现这一需求,适用于各种数据处理场景。
设置 python的pandas的dataFrame的索引值从1开始
假设有一个dataFrame:
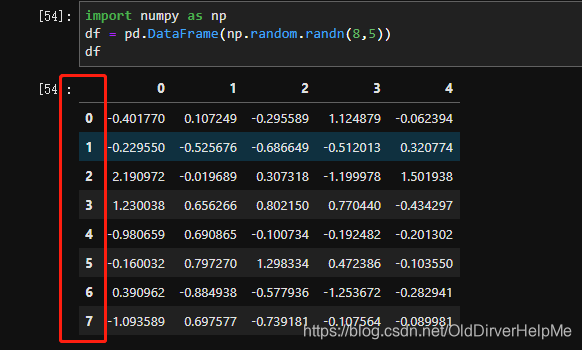
这里的index的索引列是从0开始的,那么现在我想要让它从1开始怎么做?
我搜了几篇文章,发现有的是:
df.index = range(len(df)) //这样的
data_df = pd.DataFrame({'a':a,},index=list(range(1,n))) //这种是创建的时候,不满足我当前的需求
df.reindex(index=list(range(1, df.shape[0]))) //还有这样的,少了一条数据
突然间我就悟出来了,如下所示:
df.index=df.index+1
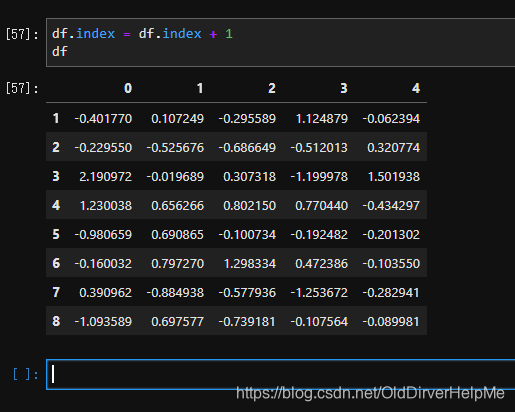
这样!就好了!
总结
这个操作比较简单,如果你有什么其它的操作,希望你能在下面留言,共同学习,共同进步,谢谢!


















 3634
3634









 到【灌水乐园】发言
到【灌水乐园】发言







