







之前结束了吴恩达老师的机器学习的15节课,虽然看得很艰辛,但是也算是对于机器学习的理论有了一个入门,很多的东西需要不断的思考以及总结。现在开始深度学习的学习,仍然做课程笔记,记录自己的一些收获以及思考。
第一周
1. ReLU (Rectified Linear Unit) 修正线性单元 ,顾名思义,作用为修正(线性回归会包含负值的情况),可以理解为 max(0,x),即 取不小于0的值。常用作sigmoid函数的一个替代。在具体的神经网络中,使用ReLU替代sigmoid,利用梯度下降法时,使算法收敛的速度更快。
2. 机智的选取x,y,会使问题的解决轻松不少。
3. 神经网络的一种分类

图像 序列数据(音频,语言)
4. 结构化数据:每一个特征都有清晰的定义 ,如数据库中的数据
非结构化数据:音频 、图像、 文本
第二周
主要利用逻辑回归的知识,对于深度学习的一些基础及python的使用做一些介绍。
1. 在二分类问题中,我们常常希望得到的是,测试样本属于哪一类的概率有多大,逻辑回归可用来解决这个问题。在逻辑回归中,使用的损失函数为:
这里注意两个概念,损失函数(loss function)针对一个样本而言,成本函数(cost function)针对所有样本而言。优化的目标是使成本函数最小,在这里,成本函数即为损失函数求和然后取均值。
2. 计算图(computation graph)
可以说,一个神经网络的计算都是按照前向传播和后向传播来组织的。前向计算,后向反馈(链式法则)。因此利用计算图,方便我们清晰得到参数与最终的复合函数的关系。我的理解是,计算图的主要目的是为了得到,对于单个样本而言,损失函数和待求参数的求导关系,其实简单点说就是链式法则。假设回归 y = w1x1 + w2x2 + b,待求参数即为w1,w2,b; 损失函数 L。其目的是为了得到 L分别对于w1、w2、 b的偏导,便于进行梯度下降。
3. 向量化(vectorization)与广播(broadcasting)
向量化应该作为编写程序时所采用的一种思想或者说是指导方式,从实数与实数的运算,上升为矩阵与矩阵的运算(多亏了强大的python包)。不仅仅是大幅提高程序的速度,更是一种良好的计算思维。
广播是python里面一个很方便的计算技巧。在使用二维矩阵(对应于向量),向量(实数),之间的四则运算时,可以非常方便的进行扩展。例如 a = [1,2,3,4] -- b = a + 100 -- b =[101,102,103,104]
4. Andrew Ng 对于python的编程给了一个建议:
消除代码中秩为1的数组:a为一个秩为1的数组,这种数组的表现和向量与矩阵不太一样,我们应该尽量避免对于这样数组的操作。如果非要操作,可尝试利用reshape操作将其转为向量(注意 reshape函数不改变原有的a数组),在进行操作。下图的a便是秩为1的数组:
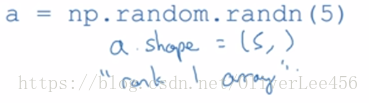















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









