







http://blog.csdn.net/oliverkingli/article/details/79108486
上一篇实现了一元一次的线性拟合,这次我们来实现多元线性拟合,以y=sin(x)函数为例:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (14,8)
# 生成随机数
n_observations = 200
xs = np.linspace(-3,3,n_observations)
ys = np.sin(xs) + np.random.uniform(-0.5, 0.5, n_observations)
plt.scatter(xs, ys)
plt.show()
# 定义容器,放入X和Y
X = tf.placeholder(tf.float32, name="X")
Y = tf.placeholder(tf.float32, name="Y")
# 定义权重和偏置,对应与一次线性函数y = wx + b
w = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.random_normal([1]), name="bias")
# 进行计算预测Y_Pre
Y_Pre = tf.add(tf.multiply(X,w), b)
# 添加高次项,改进成多项式的拟合
w_2 = tf.Variable(tf.random_normal([1]), name="weight_2")
Y_Pre = tf.add(tf.multiply(tf.pow(X, 2), w_2)/6, Y_Pre)
w_3 = tf.Variable(tf.random_normal([1]), name="weight_3")
Y_Pre = tf.add(tf.multiply(tf.pow(X, 3), w_3)/120, Y_Pre)
# 计算损失的函数值,计算均方差
sample_nums = xs.shape[0]
print(xs.shape[0])
print()
loss = tf.reduce_sum(tf.pow(Y_Pre - Y, 2))/sample_nums
# 训练的梯度
learning_rate = 0.01
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# 给出迭代次数,并且加入 Session执行
n_samples = xs.shape[0]
init = tf.global_variables_initializer()
with tf.Session() as sess:
# 首先初始化所有的变量
sess.run(init)
# 写入日记,使用tensorboard观察
writer = tf.summary.FileWriter('./graphs', sess.graph)
# 训练模型
for i in range(1000):
total_loss = 0
for x, y in zip(xs, ys):
# 通过feed_dic把数据feed进去
_, l = sess.run([optimizer, loss], feed_dict={X: x, Y:y})
total_loss += l
if i%5 ==0:
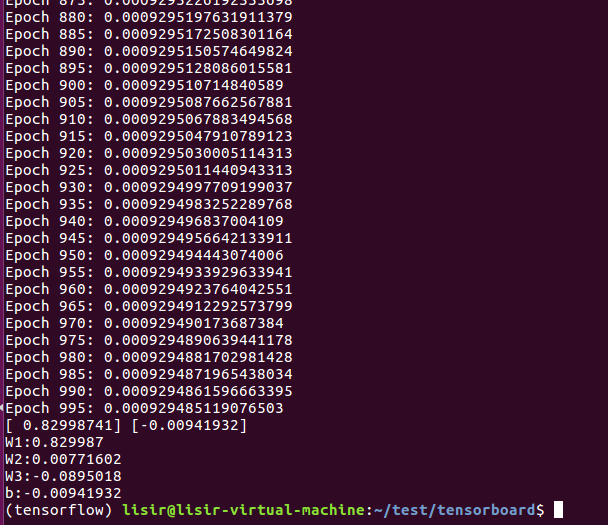
print('Epoch {0}: {1}'.format(i, total_loss/n_samples))
# 关闭writer
writer.close()
w, w_2, w_3, b = sess.run([w, w_2, w_3, b])
print(w,b)
print("W1:"+str(w[0]))
print("W2:"+str(w_2[0]))
print("W3:"+str(w_3[0]))
print("b:"+str(b[0]))
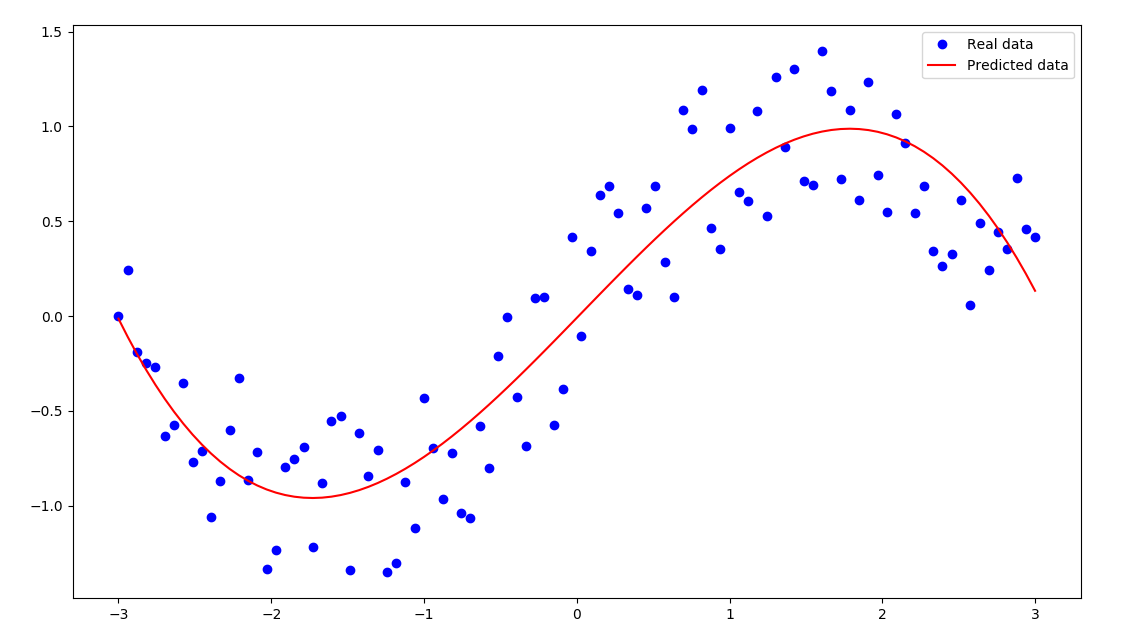
plt.plot(xs,ys,"bo",label="Real data")
plt.plot(xs,xs*w + np.power(xs, 3)*w_2 + np.power(xs, 5)*w_3 + b,'r',label="Predicted data")
plt.legend()
plt.show()

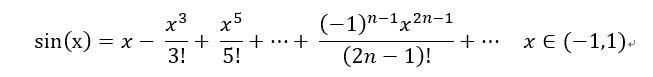















 7247
7247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









