






 本文以CHIP2021 - Task3中文临床术语标准化任务为例,介绍用LLM微调实现特定NLP任务的方法。基于ChatGPT Training Pipeline训练LLM,进行增量预训练和有监督微调,用Micro - F1分数评估模型效果,还给出复现教程,指出扩大数据集或换模型可提升效果。
本文以CHIP2021 - Task3中文临床术语标准化任务为例,介绍用LLM微调实现特定NLP任务的方法。基于ChatGPT Training Pipeline训练LLM,进行增量预训练和有监督微调,用Micro - F1分数评估模型效果,还给出复现教程,指出扩大数据集或换模型可提升效果。
相关链接
本文源码获取:https://github.com/omigeft/Chinese-Clinical-Terminology-Standardization-Task,如果对你产生了启发,希望能给个小星星支持一下哦~
原题:http://cips-chip.org.cn/2021/eval3.
中文医疗信息处理数据集CBLUE:https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414.
底座生成模型使用的是shibing624/ziya-llama-13b-medical-merged.
参考代码仓库shibing624/MedicalGPT.
项目简介
本项目用LLM微调实现特定任务,以CHIP2021-Task3中文临床术语标准化任务为例,只要有数据集,此方法是通用的,用同样的方法可以实现你想要的其它NLP任务。以下内容只是对任务实现的简单介绍,具体代码实现请往本文文首github链接,里面的复现教程会有更详细的讲解。
题目
任务简介
临床术语标准化任务是医学数据统计分析中不可或缺的一项任务。临床上,关于同一种诊断、手术、药品、检查、化验、症状等往往会有成百上千种不同的写法。标准化(归一)要解决的问题就是为临床上各种不同说法找到对应的标准说法。有了术语标准化的基础,研究人员才可对电子病历进行后续的统计分析。本质上,临床术语标准化任务也是语义相似度匹配任务的一种。但是由于原词表述方式过于多样,单一的匹配模型很难获得很好的效果。
任务详情
本次评测任务主要目标是针对中文电子病历中挖掘出的真实诊断实体进行语义标准化。 给定诊断原词,要求给出其对应的诊断标准词,以《国际疾病分类 ICD-10 北京临床版v601》标准进行了标注。
相较于2020年诊断归一任务,我们额外提供部分手术实体以及手术标准词归一关系语料,预期额外加入手术归一信息能提升诊断归一效果。
标注样例如下
| 诊断原词 | 归一后的标准词(待预测值) |
|---|---|
| 右肺结节转移可能大 | 肺占位性病变##肺继发恶性肿瘤##转移性肿瘤 |
| 右肺结节住院 | 肺占位性病变 |
| 左上肺胸膜下结节待查 | 胸膜占位 |
| 手术原词 | 手术标准词 |
| 右额叶病损切除术(神经导航+电生理) | 额叶病损切除术 |
| 右颈部静脉瘤切除术 | 颈部血管瘤切除术 |
| 眼睑肿物切除术 | 去除眼睑病损 |
实验总览
本项目是基于ChatGPT Training Pipeline训练LLM实现的,即第一阶段进行PT(Continue PreTraining)增量预训练,第二阶段进行SFT(Supervised Fine-tuning)有监督微调,后续强化学习阶段不太适合于我们的任务和数据集,因此只要进行PT和SFT就好了。我们选用的模型是HuggingFace上的shibing624/ziya-llama-13b-medical-merged,它在240万条中英文医疗数据集shibing624/medical数据集上SFT微调了一版Ziya-LLaMA-13B模型,医疗问答效果有提升,发布微调后的完整模型权重(单轮对话),更适合于临床术语标准化任务。
该项目的算法实现难度较高。为了节省时间,便基于Github开源项目代码MedicalGPT对模型进行PT和SFT。需要针对临床术语标准化任务的特点进行定制化的数据处理和预处理,以供LLM进行训练,其中1万个标准词表用于PT,归一化标准化训练集用于SFT。测试的时候用类似ChatGPT问答的方式完成临床术语标准化任务,最后使用Micro-F1分数进行模型预测效果评估。
也可以不直接在问答就标准化,询问LLM,让其逐个进行匹配,但这种方法效率过低,对1万个标准词逐个匹配的时间成本过高,因此没有采用这种方式。
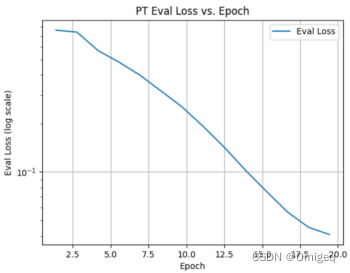
以下图表是训练了50个epochs,但是实验结果显示其实用不着这么多轮,由于数据集限制,不到10个epochs预测效果就饱和了。
在PT阶段,eval loss值随训练epoch变化情况进行可视化如下图 所示,其中y轴是对数刻度。
在SFT阶段,eval loss值随训练epoch变化情况进行可视化如下图所示,其中y轴是对数刻度。
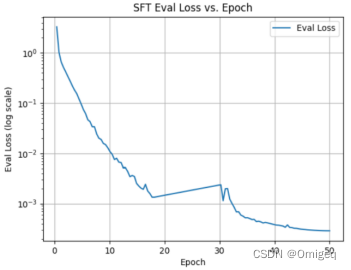
由loss变化情况,基本可以看出模型的训练已经比较充分,SFT的loss经过50轮的训练,已经比一开始时降低了至少上千倍。选取了验证集中7条数据组合的真实数据与预测数据对比作为模型预测效果的示例,如下表所示。
| 诊断原词 | 归一化后的标准词(真实) | 归一化后的标准词(预测) |
|---|---|---|
| 盲肠腺瘤 | 盲肠良性肿瘤##腺瘤 | 盲肠良性肿瘤##腺瘤 |
| 冠心病-不稳定心绞痛 | 冠状动脉粥样硬化性心脏病##不稳定性心绞痛 | 冠状动脉粥样硬化性心脏病##不稳定性心绞痛 |
| 窦房结功能不全 | 窦房结功能低下 | 窦房结功能紊乱 |
| 右附睾头囊肿 | 附睾囊肿 | 附睾囊肿 |
| 双跟骨骨折 | 跟骨骨折 | 跟骨骨折 |
| G周宫内妊娠引产后 | 引产 | 妊娠状态 |
| 前列腺动态未定肿瘤 | 前列腺动态未定或动态未知的肿瘤 | 前列腺恶性肿瘤 |
Micro-F1分数能够有效地衡量临床术语标准化任务的模型预测效果。因为Micro-F1考虑了各种类别的数量,所以更适用于数据分布不平衡的情况。在这种情况下,数量较多的类别对F1的影响会较大。
本次实验在同一份训练集和验证集下调整不同参数训练了两次,不同的训练参数的Micro-F1分数如下表所示。
| 训练Epochs轮数 | 精确率 | 召回率 | Micro-F1 |
|---|---|---|---|
| PT: 1, SFT: 10 | 0.684 | 0.705 | 0.694 |
| PT: 20, SFT: 50 | 0.681 | 0.684 | 0.682 |
这个效果还不错了,当年天池比赛冠军的Micro-F1也才百分之七十几。第一次测试的时候PT训练了1个epochs,SFT阶段训练了10个epochs,训练集和验证集比例一样。它得到的Micro-F1分数约比PT训练20个epochs、SFT训练50个epochs的分数还高大约0.01,说明在该数据集该基座模型下,训练出来的模型的预测能力已经饱和,加多了59个epochs模型预测能力不仅没有增加,还衰减了一点点。分析此结果,可猜测不管再怎么加多epochs,只能达到大约0.7的极限Micro-F1,很难再提升。如果想要突破这个值,最好的也是最根本的方法是扩大数据集,其次是更换更好的模型。
复现教程
准备工作
大模型训练配置要求较高,我们在AutoDL网站上租用了服务器,中途曾多次更换不同配置的服务器,综合考虑模型训练时间和金钱的成本,最终主要使用的服务器配置如下:

先将本文文首所说的的源码clone到服务器上(该源码基于shibing624/MedicalGPT项目实现)。
git clone https://github.com/omigeft/Chinese-Clinical-Terminology-Standardization-Task
上传代码文件到服务器上,进入src目录,根据requirements.txt安装必备库。
cd src
pip install -r requirements.txt --upgrade
大模型下载时文件较大,如果要更改下载的大模型保存位置,方法如下:
vim ~/.bashrc
将以下内容保存到~/.bashrc文件中
export HUGGINGFACE_HUB_CACHE=保存位置
export TRANSFORMERS_CACHE=保存位置
“保存位置”要自己修改。
source ~/.bashrc
后面训练的时候也要加上cache_dir=保存位置的参数。
准备工作阶段完成。
快速测试
因为base model文件过大,所以实验文件不包含base model。本notebook记录了详细的工作复现流程,但如果您非常熟悉这些工作,并且只是想快速测试模型效果,可直接下载模型shibing624/ziya-llama-13b-medical-merged以及github仓库readme里提供下载的训练完毕的lora模型,然后到增量预训练和有监督微调这两章,找到合并模型的部分合并lora模型(请注意检查读取保存模型和数据的目录!),合并完就可直接到模型测试一章进行测试。
数据预处理
查看数据集。

由于文件名显示乱码,故将文件名根据数据条数分别改为40474.xlsx和2500.tsv,并将关键内容字符串(标准化术语)都分别转换存储到40474.txt和2500.txt文本文件里,位于src/data/pretrain,作为 预训练(PreTraining, PT) 数据,为模型注入标准化术语的知识。2500.txt可直接由2500.tsv修改拓展名得到,40474.txt由以下代码从40474.xlsx转换得到:
import openpyxl
# 打开Excel文件
workbook = openpyxl.load_workbook('40474.xlsx')
# 选择工作表
sheet = workbook.active
# 打开一个文本文件来写入内容
with open('40474.txt', 'w', encoding='UTF-8') as txt_file:
# 遍历第二列内容并写入文本文件
for row in sheet.iter_rows(min_col=2, max_col=2, values_only=True):
for cell_value in row:
if cell_value is not None:
txt_file.write(str(cell_value) + '\n')
用于 有监督微调(Supervised FineTuning, SFT) 的数据包括train.json和dev.json,我们使用了以下代码转换为大模型训练所需要的jsonl格式:
import json
def json2jsonl(input_name, output_name):
# 读取输入 JSON 文件
with open(input_name, 'r', encoding='UTF-8') as input_file:
data = json.load(input_file)
# 转换数据格式
output_data = []
for item in data:
item = [
{"from": "human", "value": item["text"]},
{"from": "gpt", "value": item["normalized_result"]}
]
output_data.append({"conversations": item})
# 将转换后的数据写入输出 JSON 文件
with open(output_name, 'w', encoding='UTF-8') as output_file:
for item in output_data:
json.dump(item, output_file, ensure_ascii=False)
output_file.write("\n")
json2jsonl('train.json', 'train.jsonl')
json2jsonl('dev.json', 'dev.jsonl')
由于大模型预测较慢,几秒才能推理出一个结果,如果使用全部验证集来验证模型预测准确率,时间过长,故仅选用2000条数据验证集的最后100个数据来进行验证,其余1900条数据并入训练集。这个处理比较简单,是人工直接分割dev.jsonl为dev100.jsonl和dev1900.jsonl。train.jsonl和dev1900.jsonl放入src/data/pretrain作为训练集,dev100.jsonl将每一个问题按行存储到dev100.txt,dev100.txt放入data/test文件夹作为验证集,dev100.jsonl保留用于计算Micro-F1值。以下是将dev100.jsonl转换成dev100.txt的代码:
import json
# 打开输出文件以写入数据
with open('dev100.txt', 'w', encoding='UTF-8') as output_file:
# 逐行读取JSONL文件
with open('dev100.jsonl', 'r', encoding='UTF-8') as input_file:
for line in input_file:
data = json.loads(line)
conversations = data.get("conversations", [])
# 遍历对话
for conv in conversations:
if conv.get("from") == "human":
value = conv.get("value")
# 将来自"human"的值写入文本文件,一句一行
output_file.write(value + '\n')
数据预处理阶段完成。
增量预训练
增量预训练,在海量领域文本数据上二次预训练GPT模型,以注入领域知识。
底座生成模型使用的是类型为llama的shibing624/ziya-llama-13b-medical-merged模型。shibing624/ziya-llama-13b-medical-merged模型在中文开放测试集中的表现优异,继承了两方面的优势:1)微调训练的底座是Ziya-LLaMA-13B模型,是较强的中英文底座模型,2)微调使用的是高质量240万条中英文医疗指令数据集,和多种通用指令数据集,微调后的模型在医疗行业答复能力达到领先水平,在通用问题上的答复能力不弱于LLaMA-13B。
数据集PT阶段使用的是40474.txt和2500.txt,位于src/data/pretrain文件夹。
下面的代码是进行预训练的命令,执行前请仔细检查参数,尤其请检查--cache_dir参数,是大模型下载保存位置,如果指定位置无相应大模型则会自动从HuggingFace下载(需要使用学术网络加速方法才能访问和下载,如果使用AutoDL服务器可参考帮助文档),这个保存位置应与开头在~/.bashrc设置的保存位置相一致。这个模型大约25GB,后面还会合并两次模型,请注意选择一个容量大的区域,建议在该区域至少预留80GB。我们在开头介绍的服务器配置下执行以下代码训练了约3.5小时。
确认训练集和模型位置等参数无误后,在src文件夹下终端执行代码:
python pretraining.py \
--model_type llama \
--model_name_or_path shibing624/ziya-llama-13b-medical-merged \
--cache_dir /root/autodl-tmp \
--train_file_dir ./data/pretrain \
--validation_file_dir ./data/pretrain \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--do_train \
--do_eval \
--use_peft True \
--seed 42 \
--fp16 \
--max_train_samples -1 \
--max_eval_samples -1 \
--num_train_epochs 20 \
--learning_rate 2e-4 \
--warmup_ratio 0.05 \
--weight_decay 0.01 \
--logging_strategy steps \
--logging_steps 10 \
--eval_steps 50 \
--evaluation_strategy steps \
--save_steps 500 \
--save_strategy steps \
--save_total_limit 3 \
--gradient_accumulation_steps 1 \
--preprocessing_num_workers 64 \
--block_size 1024 \
--output_dir outputs-pt-v2 \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--target_modules all \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--torch_dtype float16 \
--device_map auto \
--report_to tensorboard \
--ddp_find_unused_parameters False \
--gradient_checkpointing True
模型训练结果:
使用lora训练模型,则保存的lora权重是adapter_model.bin, lora配置文件是adapter_config.json,合并到base model的方法见merge_peft_adapter.py。日志保存在--output_dir目录的runs子目录下,可以使用tensorboard查看,启动tensorboard方式如下:tensorboard --logdir output_dir/runs --host 0.0.0.0 --port 8009。
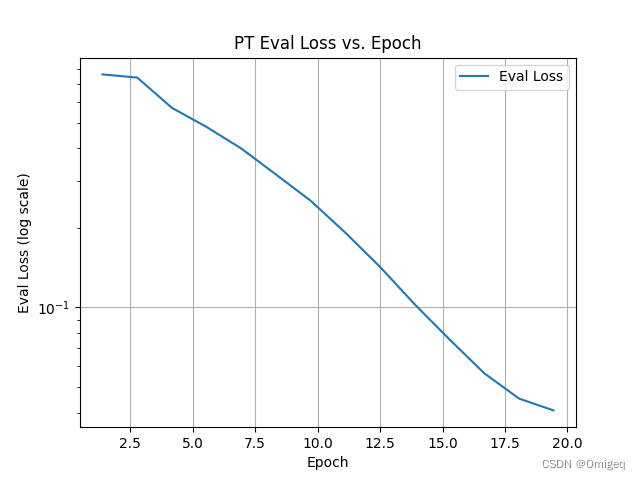
对日志记录的eval loss值随epoch变化情况进行可视化如下(y轴是对数刻度):
lora模型权重合并到base model,合并后的模型保存在--output_dir参数对应的目录下,合并后的模型大约25GB,请注意检查该参数以防磁盘分区容量不足,合并方法如下:
python merge_peft_adapter.py \
--model_type llama \
--base_model_name_or_path shibing624/ziya-llama-13b-medical-merged \
--peft_model_path outputs-pt-v2 \
--output_dir /root/autodl-tmp/merged-pt-v2/
PT阶段增量预训练完成。
有监督微调
有监督微调,构造指令微调数据集,在预训练模型基础上做指令精调,以对齐指令意图。
底座生成模型使用的是增量预训练阶段得到的预训练模型,即为merge_peft_adapter.py合并生成的模型,保存位置在它--output_dir参数对应的目录下。
数据集SFT阶段使用的是train.jsonl和dev100.jsonl,位于src/data/finetune文件夹。
与PT阶段类似,确认训练集和模型位置等参数无误后,在src文件夹下终端执行代码(我们在开头介绍的服务器配置下执行以下代码训练了约21小时):
python supervised_finetuning.py \
--model_type llama \
--model_name_or_path /root/autodl-tmp/merged-pt-v2 \
--train_file_dir ./data/finetune \
--validation_file_dir ./data/finetune \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 64 \
--do_train \
--do_eval \
--use_peft True \
--fp16 \
--max_train_samples -1 \
--max_eval_samples -1 \
--num_train_epochs 50 \
--learning_rate 5e-5 \
--warmup_ratio 0.05 \
--weight_decay 0.05 \
--logging_strategy steps \
--logging_steps 10 \
--eval_steps 50 \
--evaluation_strategy steps \
--save_steps 500 \
--save_strategy steps \
--save_total_limit 3 \
--gradient_accumulation_steps 1 \
--preprocessing_num_workers 64 \
--output_dir outputs-sft-v2 \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--target_modules all \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--torch_dtype float16 \
--device_map auto \
--report_to tensorboard \
--ddp_find_unused_parameters False \
--gradient_checkpointing True \
--cache_dir /root/autodl-tmp
模型训练结果:
使用lora训练模型,则保存的lora权重是adapter_model.bin, lora配置文件是adapter_config.json,合并到base model的方法见merge_peft_adapter.py。日志保存在--output_dir目录的runs子目录下,可以使用tensorboard查看,启动tensorboard方式如下:tensorboard --logdir output_dir/runs --host 0.0.0.0 --port 8009。
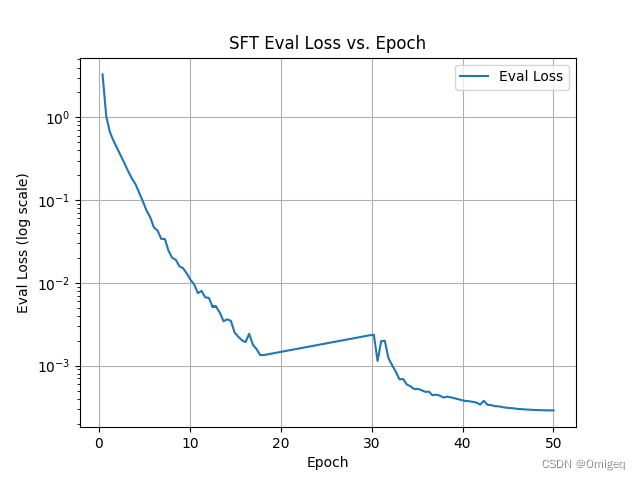
对日志记录的eval loss值随epoch变化情况进行可视化如下(y轴是对数刻度):
lora模型权重合并到base model,合并后的模型保存在--output_dir目录下,合并方法如下:
python merge_peft_adapter.py
--model_type llama \
--base_model_name_or_path /root/autodl-tmp/merged-pt-v2 \
--peft_model_path outputs-sft-v2 \
--output_dir /root/autodl-tmp/merged-sft-v2/
SFT阶段有监督微调完成。
模型测试
接下来就可以测试模型了。请注意调整参数。--base_model是模型的保存位置,一般来说需要修改成自己的模型位置;--data_file是测试数据保存位置;--predictions_file是预测结果保存位置;其它参数不用修改。
python inference.py
--model_type llama \
--base_model /root/autodl-tmp/merged-sft-v2 \
--data_file ./data/test/dev100.txt \
--predictions_file /root/autodl-tmp/dev100_predict_v2.jsonl \
--max_new_tokens 128
预测得到了dev100_predict.jsonl文件,我们需要用这个文件和dev100.jsonl计算Micro-F1值,以衡量模型效果。
Micro-F1计算公式如下:
P r e c i s i o n = ∑ i = 1 n T P i ∑ i = 1 n T P i + ∑ i = 1 n F P i Precision=\frac{\sum^{n}_{i=1}TP_i}{\sum^{n}_{i=1}TP_i+\sum^{n}_{i=1}FP_i} Precision=∑i=1nTPi+∑i=1nFPi∑i=1nTPi
R e c a l l = ∑ i = 1 n T P i ∑ i = 1 n T P i + ∑ i = 1 n F N i Recall=\frac{\sum^{n}_{i=1}TP_i}{\sum^{n}_{i=1}TP_i+\sum^{n}_{i=1}FN_i} Recall=∑i=1nTPi+∑i=1nFNi∑i=1nTPi
F 1 m i c r o = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l F1_{micro}=2\cdot\frac{Precision\cdot Recall}{Precision+Recall} F1micro=2⋅Precision+RecallPrecision⋅Recall
其中 T P i TP_i TPi是第 i i i条数据预测正确的词数, F P i FP_i FPi是第 i i i条数据预测了但真实数据没有的词数, F N i FN_i FNi是第 i i i条数据真实数据有但没预测出来的词数。
因为Micro-F1考虑了各种类别的数量,所以更适用于数据分布不平衡的情况。在这种情况下,数量较多的类别对F1的影响会较大。
以下是根据真实数据dev100.jsonl和预测数据dev100_predict_v2.jsonl计算Micro-F1的代码:
import json
# 打开输入文件和输出文件
with open('new_dev100.jsonl', 'r', encoding='utf-8') as true_file, \
open('dev100_predict_v2.jsonl', 'r', encoding='utf-8') as pred_file, \
open('dev100_eval_v2.jsonl', 'w', encoding='utf-8') as output_file:
# 初始化数值用于计算Micro-F1
total_TP, total_FP, total_FN = 0, 0, 0
# 逐行读取输入文件
for true_line, pred_line in zip(true_file, pred_file):
true_data = json.loads(true_line)
pred_data = json.loads(pred_line)
# 获取来自gpt的value值
true_value = true_data['conversations'][1]['value']
pred_value = pred_data['Output']
# 根据井号分割字符串为列表(用set去重)
true_values_list = list(set(true_value.split('##')))
pred_values_list = list(set(pred_value.split('##')))
# 计算TP, FP, FN
TP, FP, FN = 0, 0, 0
for true_item in true_values_list:
for pred_item in pred_values_list:
if true_item == pred_item:
TP += 1
FP = len(pred_values_list) - TP
FN = len(true_values_list) - TP
total_TP += TP
total_FP += FP
total_FN += FN
# 创建新的数据格式
new_data = {"TP": TP, "FP": FP, "FN": FN,
"true": true_values_list, "pred": pred_values_list}
# 将新数据写入输出文件
output_file.write(json.dumps(new_data, ensure_ascii=False) + '\n')
# 计算Micro-F1
precision = total_TP / (total_TP + total_FP)
recall = total_TP / (total_TP + total_FN)
micro_F1 = 2 * precision * recall / (precision + recall)
print(f"precision: {precision}, recall: {recall}, micro-F1: {micro_F1}")
经以上代码计算得到precision: 0.680628272251309, recall: 0.6842105263157895, micro-F1: 0.6824146981627297,也就是说Micro-F1约0.7。
每条数据分割后的标准化词列表,以及
T
P
TP
TP,
F
P
FP
FP,
F
N
FN
FN都可以在文件dev100_eval_v2.jsonl中查看。

模型测试阶段完成。
后记
第一次测试的时候PT训练了1个epochs,SFT阶段训练了10个epochs,训练集和验证集比例一样,可用outputs-pt-v2和outputs-sft-v2按顺序与基座模型shibing624/ziya-llama-13b-medical-merged合并得到。它得到的预测评价结果是precision: 0.6836734693877551, recall: 0.7052631578947368, micro-F1: 0.694300518134715。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









