






在Python中,fitz库可以用于多种任务,如打开PDF文件、遍历页面、添加注释、提取文本、旋转页面等,此外,它还可以用于在PDF页面上添加高亮注释、提取图像等操作,这篇文章主要介绍了Python根据页码处理PDF文件的内容,需要的朋友可以参考下
1.环境准备
pymupdf: 是wxWidgets在Python语言下的封装,处理PDF文件的库,提供了读取、提取和创建PDF文件的功能;wxWidgets是一个跨平台的GUI应用编程接口,使用C++编写。
wxPython: 基于wxWidgets的Python包,用于创建跨平台的图形用户界面(GUI)应用程序。
fitz: fitz库是一个基于Python开发的PDF处理库,它是PyMuPDF的前身。fitz提供了一系列的API和功能,可以用于读取、编辑和生成PDF文件。此外,它还可以处理其他类型的图像,如TIFF和JPEG,提供图像处理功能,如旋转、裁剪、缩放、调整亮度、对比度和色彩平衡等。
在Python中,fitz库可以用于多种任务,如打开PDF文件、遍历页面、添加注释、提取文本、旋转页面等。此外,它还可以用于在PDF页面上添加高亮注释、提取图像等操作。
pip install PIL
pip install fitz
pip install pymupdf
pip install wxpython
# pip install 库包名 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
# pip install wxpython -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
2.Python参考代码
创建1个简单的GUI应用程序,它将允许用户选择要打开的PDF文件,并输入开始页码和结束页码。然后,点击"Extract"按钮将提取指定范围内的页面并将其保存为新的PDF文件
import fitz
import wx
class PDFExtractor(wx.Frame):
def __init__(self, parent):
wx.Frame.__init__(self, parent, id=wx.ID_ANY, title=u"PDF Extractor", pos=wx.DefaultPosition,
size=wx.Size(500, 254), style=wx.DEFAULT_FRAME_STYLE | wx.TAB_TRAVERSAL,
name=u"PDF Extractor")
self.SetSizeHintsSz(wx.DefaultSize, wx.DefaultSize)
self.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_WINDOW))
self.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_ACTIVECAPTION))
bSizer2 = wx.BoxSizer(wx.VERTICAL)
self.m_filePicker2 = wx.FilePickerCtrl(self, wx.ID_ANY, wx.EmptyString, u"Select a file", u"*.*",
wx.DefaultPosition, wx.DefaultSize, wx.FLP_DEFAULT_STYLE)
self.m_filePicker2.SetFont(wx.Font(9, 74, 90, 92, False, "微软雅黑"))
self.m_filePicker2.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_HIGHLIGHT))
self.m_filePicker2.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_HIGHLIGHT))
bSizer2.Add(self.m_filePicker2, 0, wx.ALL | wx.EXPAND, 5)
self.m_staticText5 = wx.StaticText(self, wx.ID_ANY, u"Start Page:", wx.DefaultPosition, wx.DefaultSize, 0)
self.m_staticText5.Wrap(-1)
self.m_staticText5.SetFont(wx.Font(9, 74, 90, 92, True, "微软雅黑"))
self.m_staticText5.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_BTNTEXT))
bSizer2.Add(self.m_staticText5, 0, wx.ALL, 5)
self.m_textCtrl1 = wx.TextCtrl(self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, 0)
bSizer2.Add(self.m_textCtrl1, 0, wx.EXPAND, 5)
self.m_staticText6 = wx.StaticText(self, wx.ID_ANY, u"End Page:", wx.DefaultPosition, wx.DefaultSize, 0)
self.m_staticText6.Wrap(-1)
self.m_staticText6.SetFont(wx.Font(9, 74, 90, 92, True, "微软雅黑"))
self.m_staticText6.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_BTNTEXT))
bSizer2.Add(self.m_staticText6, 0, wx.ALL, 5)
self.m_textCtrl2 = wx.TextCtrl(self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.DefaultSize, 0)
bSizer2.Add(self.m_textCtrl2, 0, wx.EXPAND, 5)
self.m_button18 = wx.Button(self, wx.ID_ANY, u"Extract", wx.DefaultPosition, wx.DefaultSize, wx.NO_BORDER)
self.m_button18.SetFont(wx.Font(12, 74, 90, 92, False, "微软雅黑"))
self.m_button18.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_BTNTEXT))
self.m_button18.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_BTNHIGHLIGHT))
self.m_button18.Bind(wx.EVT_BUTTON, self.extract_pages)
bSizer2.Add(self.m_button18, 0, wx.ALIGN_CENTER_HORIZONTAL | wx.SHAPED, 5)
self.SetSizer(bSizer2)
self.Layout()
self.Centre(wx.BOTH)
def __del__(self):
pass
def extract_pages(self, event):
file_path = self.m_filePicker2.GetPath()
start_page = int(self.m_textCtrl1.GetValue())
end_page = int(self.m_textCtrl2.GetValue())
doc = fitz.open(file_path)
output_doc = fitz.open()
for page_num in range(start_page - 1, end_page):
output_doc.insert_pdf(doc, from_page=page_num, to_page=page_num)
output_path = file_path.replace(".pdf", "_extracted.pdf")
output_doc.save(output_path)
output_doc.close()
doc.close()
wx.MessageBox("Extraction complete!", "Success", wx.OK | wx.ICON_INFORMATION)
# app = wx.App()
# PDFExtractor(None, title="PDF Extractor")
# app.MainLoop()
if __name__ == '__main__':
app = wx.App() # 运行wx.App()方法。认为窗体是一个独立运行的app,所以要定义一个app的程序类来让窗体执行,调用wx类库对应的App方法来生成应用程序的类对象:wx.App()
frame = PDFExtractor(None) # 调用Frame类,并且不指定父类,当前就成为父类
frame.Show() # 运行展示界面的方法Show()
app.MainLoop() # 进入程序wx.App()循环
wxFormBuilder配置效果
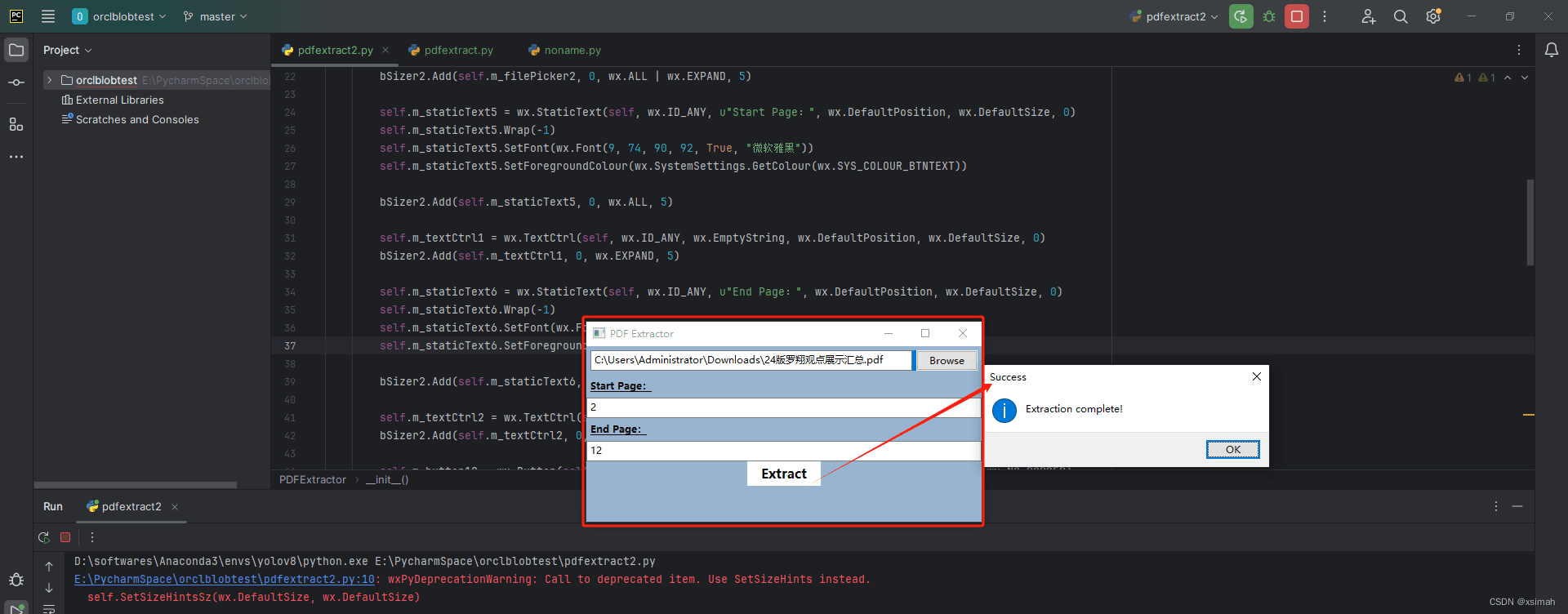
运行效果
3.其他参考
https://blog.csdn.net/winniezhang/article/details/134924216wxFormBuilder
工具下载地址【python012】
Python根据页码处理PDF文件的内容
到此这篇关于Python根据页码处理PDF文件的内容的文章就介绍到这了,更多相关Python页码处理PDF文件内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持vb.net教程C#教程python教程SQL教程access 2010教程xin3721自学网















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









