






自从ChatGPT等大型语言模型(Large Language Model, LLM)出现以来,其类通用人工智能(AGI)能力引发了自然语言处理(NLP)领域的新一轮研究和应用浪潮。尤其是ChatGLM、LLaMA等普通开发者都能运行的较小规模LLM开源之后,业界涌现了大量基于LLM的二次微调和应用案例。
传神社区(Opencsg)旨在收集和整理与中文NLP相关的开源数据集。目前每篇文章整理的资源至少15个!如果本篇文章对您有帮助,欢迎点赞与收藏~
我们也欢迎大家贡献本文未收录的开源数据集,提供对应的资源,描述与链接,感谢您的支持!
目录
1. 语料库
-
-
-
1.1 人名语料库数据集
-
1.2 Chinese-Word-Vectors数据集
-
1.3 中文聊天语料数据集
-
1.4 中文谣言数据数据集
-
1.5 中文自然语言处理 语料、数据集
-
1.6 中文ULMFiT数据集
-
1.7 维基百科json版(wiki2019zh)数据集
-
1.8 新闻语料json版(news2016zh)数据集
-
1.9 百科类问答json版(baike2018qa)数据集
-
1.10 社区问答json版(webtext2019zh) :大规模高质量数据集
-
1.11 翻译语料(translation2019zh)数据集
-
-
-
2.词库及词法工具
-
-
2.1 textfilter词库
-
2.2 人名抽取功能词法工具
-
2.3 中文缩写库数据集
-
2.4 汉语拆字词典数据集
-
2.5 词汇情感值数据集
-
2.6 中文词库、停用词、敏感词数据集
-
2.7 汉字拼音转换工具
-
2.8 中文繁简体互转数据集
-
-
01 语料库
1.1 人名语料库数据集
Chinese-Names-Corpus:
地址:https://opencsg.com/datasets/MagicAI/Chinese-Names-Corpus
简介:中文人名语料库。人名生成器。中文姓名,姓氏,名字,称呼,日本人名,翻译人名,英文人名。可用于中文分词、人名实体识别。

1.2 Chinese-Word-Vectors数据集
Chinese-Word-Vectors:
地址:https://opencsg.com/datasets/MagicAI/Chinese-Word-Vectors
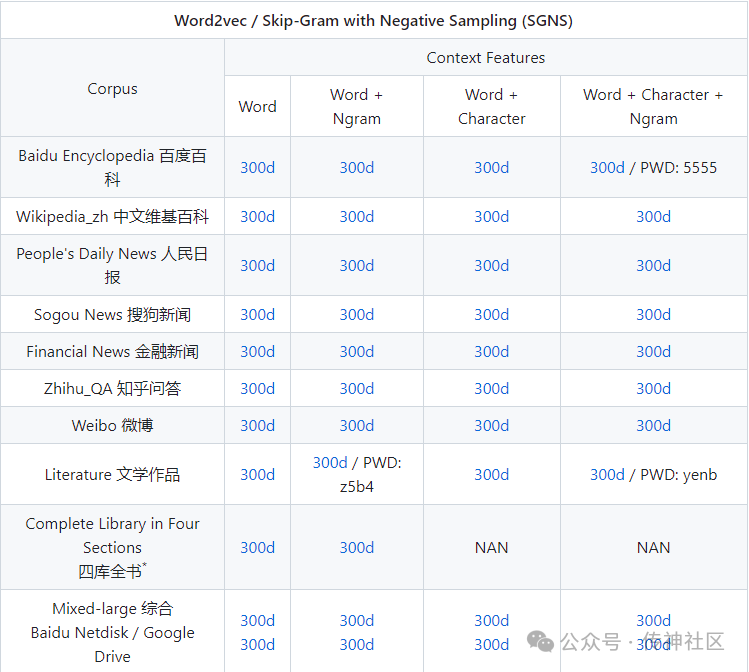
简介:本项目提供超过100种中文词向量,其中包括不同的表示方式(稠密和稀疏)、不同的上下文特征(词、N元组、字等等)、以及不同的训练语料。获取预训练词向量非常方便,下载后即可用于下游任务。此外,我们还提供了中文词类比任务数据集CA8和配套的评测工具,以便对中文词向量进行评估。
1.3 中文聊天语料数据集
chinese-chatbot-corpus:
地址:https://opencsg.com/datasets/MagicAI/chinese-chatbot-corpus
简介:该库是对目前市面上已有的开源中文聊天语料的搜集和系统化整理工作 该库搜集了包含 chatterbot 豆瓣多轮 PTT八卦语料 青云语料 电视剧对白语料 贴吧论坛回帖语料 微博语料 小黄鸡语料 共8个公开闲聊常用语料和短信,白鹭时代问答等语料。并对8个常见语料的数据进行了统一化规整和处理,达到直接可以粗略使用的目的。使用该项目,即可对所有的聊天语料进行一次性的处理和统一下载,不需要到处自己去搜集下载和分别处理各种不同的格式。
1.4 中文谣言数据数据集
Chinese_Rumor_Dataset:
地址:https://opencsg.com/datasets/MagicAI/Chinese_Rumor_Dataset
简介:该数据为从新浪微博不实信息举报平台抓取的中文谣言数据,分为两个部分。其中当前目录下的数据集仅包含谣言原微博,不包含转发/评论信息;而CED_Dataset中是包含转发/评论信息的中文谣言数据集。
1.5 中文自然语言处理 语料、数据集
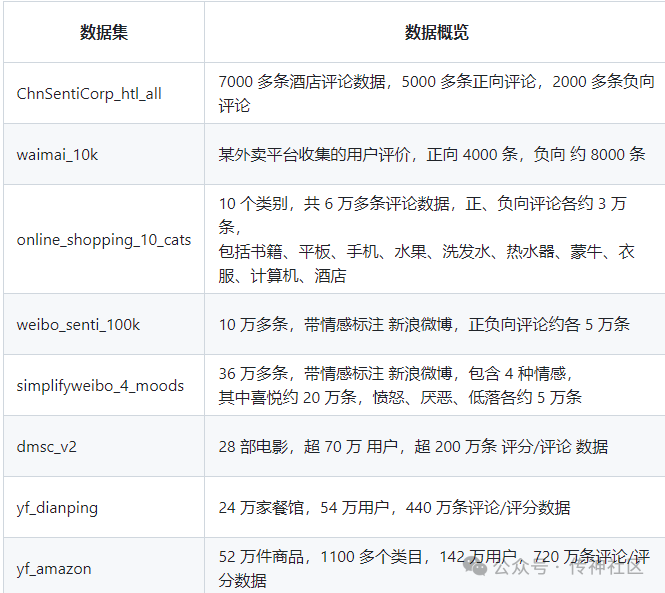
ChineseNlpCorpus:
地址:https://opencsg.com/datasets/MagicAI/ChineseNlpCorpus
简介:搜集、整理、发布中文自然语言处理语料/数据集,与有志之士共同促进中文自然语言处理的发展。
1.6 中文ULMFiT数据集
chinese_ulmfit:
地址:https://opencsg.com/datasets/MagicAI/chinese_ulmfit
简介:创建虚拟环境,解压中文维基百科语料,分词维基百科语料,分词领域语料等等。
1.7 维基百科json版(wiki2019zh)数据集
nlp_chinese_corpus:
地址:https://opencsg.com/datasets/MagicAI/nlp_chinese_corpus
简介:可以做为通用中文语料,做预训练的语料或构建词向量,也可以用于构建知识问答。
1.8 新闻语料json版(news2016zh)数据集
nlp_chinese_corpus:
地址:https://opencsg.com/datasets/MagicAI/nlp_chinese_corpus
简介:包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文。
数据集划分:数据去重并分成三个部分。训练集:243万;验证集:7.7万;测试集,数万。
1.9 百科类问答json版(baike2018qa)数据集
nlp_chinese_corpus:
地址:https://opencsg.com/datasets/MagicAI/nlp_chinese_corpus
简介:含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。
数据集划分:数据去重并分成三个部分。训练集:142.5万;验证集:4.5万;测试集,数万。

1.10 社区问答json版(webtext2019zh) :大规模高质量数据集
nlp_chinese_corpus:
地址:https://opencsg.com/datasets/MagicAI/nlp_chinese_corpus
简介:含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。从1400万个原始问答中,筛选出至少获得3个点赞以上的的答案,代表了回复的内容比较不错或有趣,从而获得高质量的数据集。除了对每个问题对应一个话题、问题的描述、一个或多个回复外,每个回复还带有点赞数、回复ID、回复者的标签。
数据集划分:数据去重并分成三个部分。训练集:412万;验证集:6.8万;测试集a:6.8万。

1.11 翻译语料(translation2019zh)
nlp_chinese_corpus:
地址:https://opencsg.com/datasets/MagicAI/nlp_chinese_corpus
简介:中英文平行语料520万对。每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。对于一个平行的中英文对,中文平均有36个字,英文平均有19个单词(单词如“she”)
数据集划分:数据去重并分成三个部分。训练集:516万;验证集:3.9万;测试集,数万。

2.词库及词法工具
2.1 textfilter词库
textfilter:
简介:敏感词过滤的几种实现+某1w词敏感词库
地址:https://opencsg.com/datasets/MagicAI/textfilter

2.2 人名抽取功能词法工具
cocoNLP:
简介:这是一个中文自然语言处理(NLP)包,可以从文本中提取信息。
地址:https://opencsg.com/datasets/MagicAI/cocoNLP

2.3 中文缩写库数据集
Chinese-abbreviation-dataset:
简介:这是论文《A Chinese Dataset with Negative Full Forms for General Abbreviation Prediction》发布的数据集。
地址:https://opencsg.com/datasets/MagicAI/Chinese-abbreviation-dataset

2.4 汉语拆字词典数据集
chaizi:
简介:膂 | 旅 肉 | 旅 月 鋓 | 金 利 | 釒 利 迴 | 辵 回 | 辶 回 証 | 言 正 | 訁 正
目前一字最多可以有六(6)種拆法,例如:
| 漢字 | 拆法 (一) | 拆法 (二) | 拆法 (三) | 拆法 (四) | 拆法 (五) | 拆法 (六) |
| 絕 | 絲 刀 巴 | 糹 刀 巴 | 糸 刀 巴 | 絲 色 | 糹 色 | 糸 色 |
| 拼 | 手 并 | 扌 并 | 才 并 | 手 幷 | 扌 幷 | 才 幷 |
| 鋶 | 金 亠 厶 川 | 釒 亠 厶 川 | 金 巟 | 釒 巟 | 金 㐬 | 釒 㐬 |
地址:https://opencsg.com/datasets/MagicAI/chaizi
2.5 词汇情感值数据集
SentiBridge:
简介:本词典包含:实体/属性—情感词。例如:“长城 宏伟”、“性价比 高”、“价格 高”。主要目的是刻画人们是怎么描述某个实体的,例如大家通常用 宏伟 来形容长城。
目前词典包含三个领域语料的抽取结果:新闻、旅游、餐饮,共计30万对。
地址:https://opencsg.com/datasets/MagicAI/SentiBridge

2.6 中文词库、停用词、敏感词数据集
Chinese_from_dongxiexidian:
简介:包含素材:Files --
分词词典: 综合了百度、搜狗等词库,以及手动整理的若干人名和新近出现的热词
中文停用词: 综合了"百度停用词表","哈工大停用词表","四川大学机器学习实验室停用词表"等若干停用词表,取交集并去除了不需要的标点符号和英文单词
地址:https://opencsg.com/datasets/MagicAI/Chinese_from_dongxiexidian
2.7 汉字拼音转换工具
python-pinyin:
简介:将汉字转为拼音。可以用于汉字注音、排序、检索(Russian translation_) 。
最初版本的代码参考了 hotoo/pinyin <https://github.com/hotoo/pinyin>__ 的实现。
-
Documentation: https://pypinyin.readthedocs.io/
-
GitHub: https://github.com/mozillazg/python-pinyin
-
License: MIT license
-
PyPI: https://pypi.org/project/pypinyin
-
Python version: 2.7, pypy, pypy3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 3.10, 3.11, 3.12
地址:https://opencsg.com/datasets/MagicAI/python-pinyin

2.8 中文繁简体互转
zhtools:
简介:一些大概没有用了的与 NScript 有关的东西。
License: GPLv2
但 nstemplate.py 和 portable.py 除外。它们并不依赖任何 GPL 项目,并且可以单独运行。这两者均是 Public Domain 的。
gbk2sjis.py 将简体 nscript.dat/00~99.txt 转换为日文编码。
对不支持 GBK 而仅支持日文编码的 ONS 模拟器,当运行简体移植的时候会乱码。这个工具能将原脚本转换为日文编码。
由于很多汉字在日文中并不存在,故会进行简繁转换和一些字符替换。部分无法自动处理的字符替换定义在 gbk2sjis.dat 中。
地址:https://opencsg.com/datasets/MagicAI/zhtools

欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https:// github.com/opencsg
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区
















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









