







欢迎大家关注我们近期发表在CVPR2024上的工作《SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution》[1]
项目主页:
论文链接:
https://arxiv.org/abs/2312.11598
核心亮点
01直接根据人类复杂语言指令生成轨迹
02自动化从数据集中学习可解释的技能
03跨平台的技能泛化
04直接使用图像输入
这篇文章是我们在AIGC赋能智能机器人控制系列工作中在自动技能学习和可解释性上的进一步扩展。
我们先前的工作[2][3]已经展示了Diffusion Model 在Robotics Learning尤其是Manipulation任务上的卓越性能。但是对于语言指令输入的任务,人类自然语言的高度抽象以及时常有包含多个子任务的复合语义,给基于条件扩散模型的策略带来了很大的困难。先前的工作如Decision Diffuser[4]预定义了一个技能库将复杂语义分解到这个技能库中的某个技能来应对这个挑战。但是它就受限于一个预定义的技能库,以及难以捕捉复合语义的步骤间依赖关系。另外,相较于先前的工作使用状态感知,使用图像输入的感知,是一种更为自然且更具挑战性的情景。
本工作的核心思想在于先将模棱两可的指令分解为可学习和可复用的子技能子目标,然后使用可迁移的以这些子技能为条件的扩散策略进行规划,更好地使控制策略能够遵循复合语义的逻辑顺序,符合任务结构,并在不同任务之间迁移适用。我们的方法与之前方法的比较如下图。
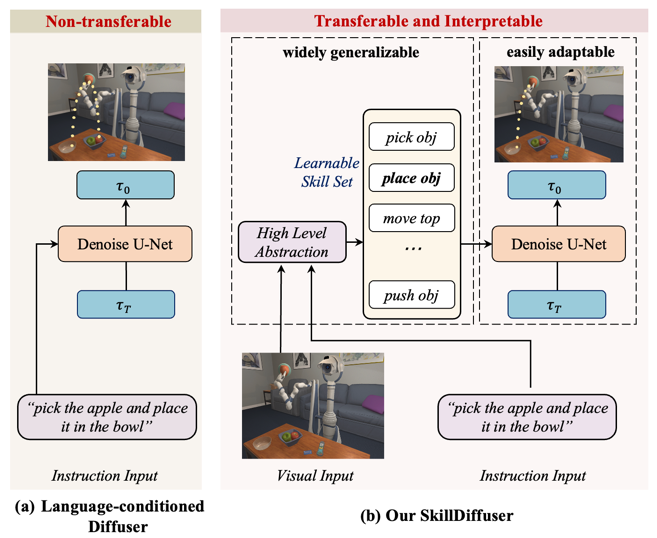
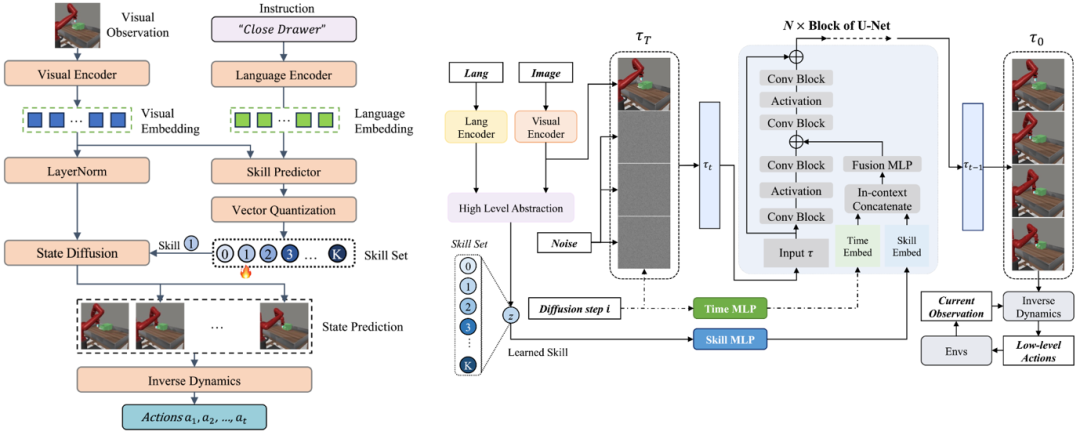
在具体的方法上,我们提出SkillDiffuser,一种将高层技能学习与底层条件扩散执行相结合的层级规划框架。SkillDiffuser首先通过学习嵌入任务指令语义的可重用技能,得到离散化的可解释的子潜变量目标。然后以这些学到的子潜变量目标(技能)为条件建立一个基于扩散模型的策略,以生成与总体指令语义目标一致的定制、连贯的轨迹。这种具有可学习技能的端到端方法使SkillDiffuser能够在不同的任务中遵循相似的离散化子技能。SkillDiffuser的架构如下图。
我们的方法LOReL Sawyer Dataset和MetaWorld Dataset(仅使用图像输入,不使用机械臂末端状态,我们在MetaWorld上重新采集的数据亦上传到我们的项目主页上)均取得了更优异的结果。
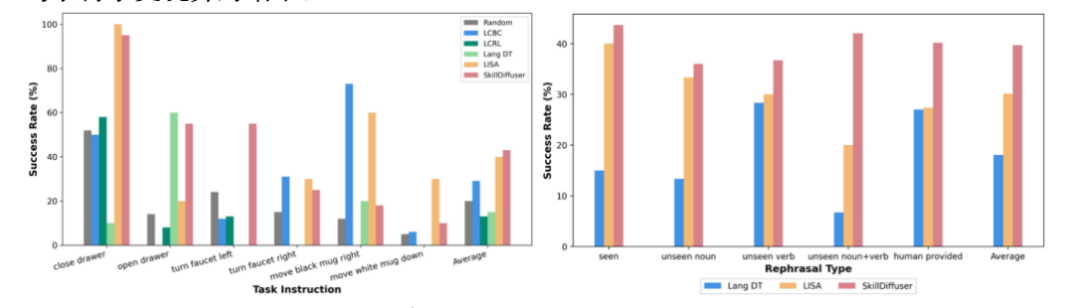
Performance Comparison in Compositional Tasks. (LOReL Planner[5], LISA[6].)
| METHOD | LANG DT | LOREL PLANNER | LISA | SKILLDIFFUSER |
| SUCCESS RATE | 13.33% | 18.18% | 20.89% | 25.21% |

我们同时开源了用于visual imitation learning 的Metaworld数据集,已经上载到我们的项目网站上,欢迎下载使用。
项目主页:
论文链接:
https://arxiv.org/abs/2312.11598
参考
[1] SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution https://arxiv.org/abs/2312.11598
[2] AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners https://arxiv.org/abs/2302.01877
[3] MetaDiffuser: Diffusion Model as Conditional Planner for Offline Meta-RL https://arxiv.org/abs/2305.19923
[4] Is Conditional Generative Modeling all you need for Decision-Making? https://arxiv.org/abs/2211.15657
[5] Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation https://arxiv.org/abs/2109.01115
[6] LISA: Learning Interpretable Skill Abstractions from Language https://arxiv.org/abs/2203.00054
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









