







InternVid 是一个开源的大规模视频-文本数据集,旨在促进视频理解和生成任务的发展,由上海人工智能实验室与南京大学、中国科学院等单位联合发布,相关的工作已经被ICLR2024接收。它包含超过 700 万个视频,总时长近 76 万小时,并附带详细的文本描述。InternVid 的发布将推动文本-视频的多模态理解和生成的进步,并为相关研究和应用提供新的机遇,包含以下特点:
-
规模庞大:InternVid 是目前公开的最大的视频-文本数据集之一,包含超过 700 万个视频,总时长近 76 万小时。
-
内容丰富: 视频内容涵盖日常生活、体育运动、娱乐、教育等多个领域,能够满足不同研究和应用的需求。
-
高质量: 视频和文本都经过精心挑选和处理,保证了数据集的高质量,提供了丰富的描述,CLIP-SIM,视频美学分数。
InternVid 可用于以下任务:
-
视频理解: 视频分类、视频检索、视频描述生成、视频摘要生成等。
-
视频生成: 视频编辑、视频合成、视频特效等。
-
多模态学习: 视频-文本语义匹配、视频-文本检索、视频-文本生成等。

论文:
https://arxiv.org/abs/2307.06942
开源链接:
https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid
HuggingFace:
https://huggingface.co/datasets/OpenGVLab/InternVid
InternVid的出发点
学习可迁移的视频-文本表示对于视频理解至关重要,尤其是在自动驾驶、智能监控、人机交互和视觉搜索等实际应用中。近期,OpenAI发布的Sora模型在文生视频领域取得了显著进展。Sora不仅打破了视频连贯性的局限,还在多角度镜头切换中保持一致性,并展示出对现实世界逻辑的深刻理解。这一突破为视频-语言领域的多模态对比学习提供了新的可能性,尽管目前Sora尚未开放给公众使用,但其在视频生成领域的GPT-3时刻,预示着通用人工智能的实现可能比预期来得更快。
但是限制住目前探索的一个关键原因是缺乏用于大规模预训练的高质量视频-语言数据集。当前的研究依赖于如HowTo100M [1]、HD-VILA [2] 和 YT-Temporal [3, 4] 等数据集,其文本是使用自动语音识别(ASR)生成的。尽管这些数据集规模庞大,但它们在视频和相应文本描述之间的语义相关性通常较低。这类的数据一方面不太符合文生视频等生成任务的需要,另一方面提高这种相关性(例如,通过将视频与描述对齐以改善它们的匹配度)显著有利于下游任务,如视频检索和视频问答。
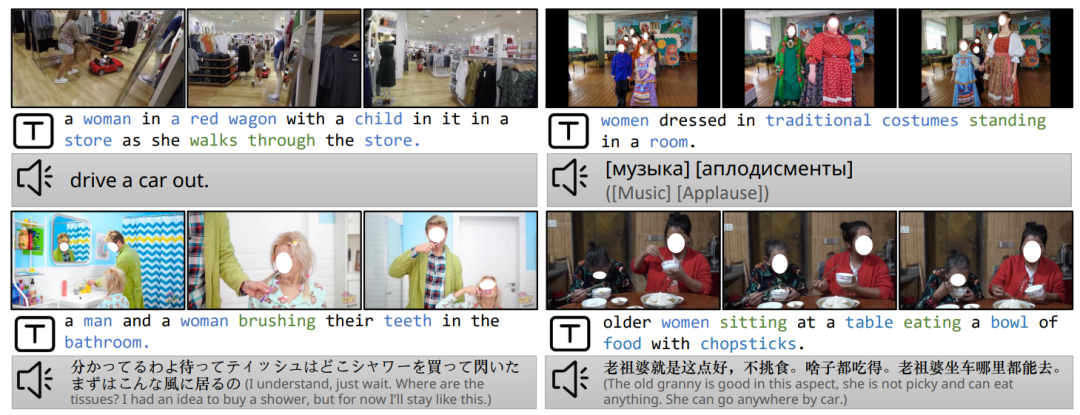
为了解决扩大视频语言建模规模的挑战,同时保持高视频-文本对应性,我们提出了一个大规模的以视频为中心的数据集InternVid,见图1。ASR转录几乎没有描述视频中的视觉元素,而生成的描述则涵盖有更多的视觉内容。该数据集包含高度相关的视频-文本对,包括超过700万视频,总计760,000小时,产生234M个视频片段,涵盖16种场景和约6,000个动作描述。为了提高视频-文本匹配度,我们采用了多尺度方法生成描述。在粗略尺度上,我们对每个视频的中间帧进行描述,并使用描述作为视频描述。在精细尺度上,我们生成逐帧描述,并用语言模型对它们进行总结。
通过InternVid,我们学习了一个视频表示模型ViCLIP,实现了较强的零样本性能。对于文生视频,我们筛选了一个具有美学的子集InternVid-Aes,并涵盖1800万个视频片段。与WebVid-10M[5]一起,InternVid可以显著提高基于diffusion的视频生成模型的生成能力。
数据集收集
我们确定了构建此数据集的三个关键因素:显著的时序信息、丰富多样的语义以及很强的视频-文本相关性。为了确保高时序性,我们基于action和activity的查询词来收集原始视频。为了丰富和多样的语义,我们不仅爬取了各个类别中的流行视频,还故意增加了从不同国家和语言的数据比例。为了加强视频-文本相关性,我们使用图像描述和语言模型从特定帧的注释生成视频描述。接下来,我们将详细阐述数据集构建过程,并讨论其统计数据和特征。
#01-数据集的多样性描述
16个流行类别中收集了各种百分比的视频。为了确保多样性,我们选择了来自不同语言的国家的视频,而非依赖于一个主导语言环境。我们采样的国家包括英国、美国、澳大利亚、日本、韩国、中国、俄罗斯和法国等。在时长方面,每个视频平均持续351.9秒。几乎一半(49%)的视频时长不超过五分钟,而四分之一(26%)的视频时长在五到十分钟之间。只有8%的视频超过20分钟。在策划的视频中,85%是高分辨率(720P),其余15%的分辨率从360P至720P不等。虽然低分辨率的视频在内容生成任务中可能表现不如高分辨率的视频,但只要配有适当的描述,它们仍可用于视频-语言表示学习。
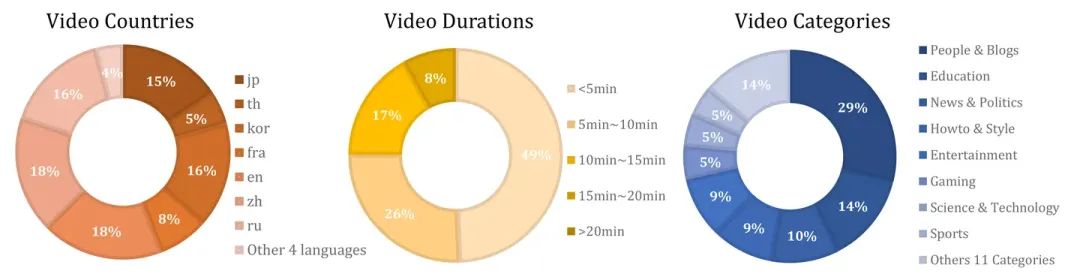
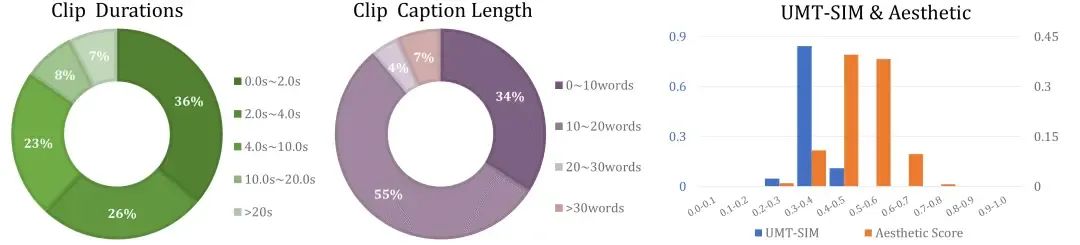
InternVid展示了在分割剪辑级别上具有不同剪辑时长和描述长度的多样性。美学分数和剪辑-描述相似度均匀分布。大部分剪辑的长度在0-10秒之间,占所有剪辑的85%。大约一半的剪辑描述含有10-20个单词,而三分之一的剪辑描述含有少于10个单词。大约11%的剪辑具有超过20个单词的长描述。
#02-原始数据收集
我们从互联网收集视频,考虑到其数据的多样性和丰富性,以及其对学术使用。总共,我们获得了700万个视频链接,平均时长为6.4分钟。我们通过创建视频ID的数据库,并排除在2023年4月之前公开可用的数据集中已存在的任何视频,来确保我们数据集的独特性。一方面,我们选择了流行频道及其相应的热门或高评分视频,从新闻、游戏等类别中,共获得200万视频。另一方面,我们创建了与动作/活动相关的动词列表。有了这个列表,我们也通过选择检索结果顶部的视频,获得了510万视频。
#03-定义动作和视频检索词
我们从ATUS[6]、公共视频数据集和文本语料库中定义了大约6.1K个动作短语。然后它们经过模型的精炼和手动的剔除。我们利用2017年至2022年的ATUS动作,将它们合并并去除重复项。对于参考的公共视频数据,我们利用了Kinetics [7]、SomethingSomething系列 [8,9]、UCF101 [10]等。这为我们提供了1103个动作标签。此外,我们还访问了几个grounding的数据集。我们使用语言模型从语料库中提取动作及其相应的目标(如果存在),形成短语,经过人工检查后共有5001个动作。总共,我们收集了6104个视频查询词,用于在网络上搜索视频。
#04-收集策略
为了确保我们数据集的质量,我们建立了特定的爬取规则。我们只收集时长在10秒到30分钟之间,分辨率从360P到720P的视频。在这个过程中,我们优先考虑可用的最高分辨率。为了提供一个全面的多模态数据集,我们收集了视频及其音频、描述、标题和摘要。
#05-多尺度视频描述生成
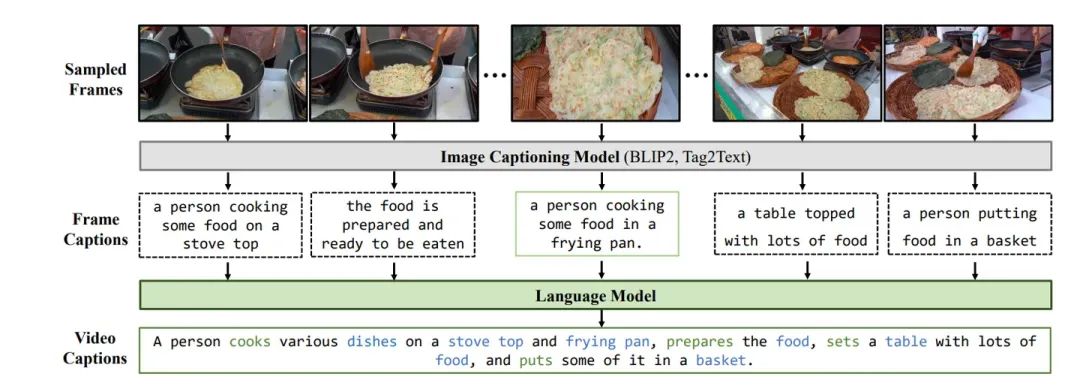
为了生成可扩展、丰富和多样化的视频描述,我们采用了多尺度方法,包含两种不同的描述策略,如图4所示。在更细的尺度上,我们通过专注于视频片段中常见的对象、动作和场景描述来简化视频描述过程。我们故意忽略了复杂细节,如微妙的面部表情和动作,以及其他细微元素。在更粗的尺度上,仅对视频的中心帧进行描述。鉴于我们关注的是通过场景分割过滤的短视频片段(大约10秒),大多数视频主要显示一致的对象,没有显著的外观变化。这避免了在处理视频时从图像角度处理身份保留问题。技术上,我们使用轻量级图像描述模型Tag2Text[11]进行更细的尺度描述,它以低fps逐帧描述视频。在更粗的尺度上,我们使用BLIP2 [12]对片段的中间帧进行描述。然后,这些描述被合成成一个综合视频描述,使用预训练的语言模型[13, 14]。
多模态视频表征模型 ViCLIP
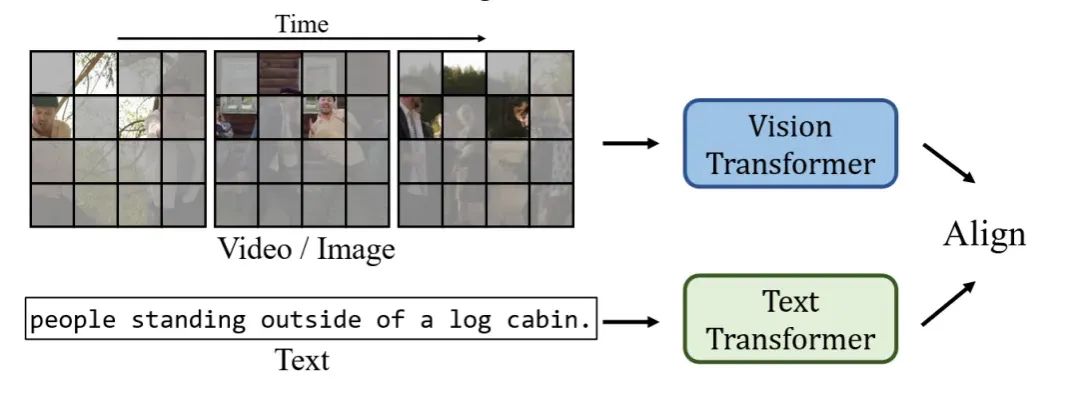
基于InternVid和CLIP[15],我们还提出了ViCLIP,一个视频-文本对比学习的模型,它基于ViT-L,并采用了视频遮盖和对比损失的方法,来学习可迁移的视频-文本表示,如图5所示。通过引入 DeepSpeed 和 FlashAttention,ViCLIP 在 64 个 NVIDIA A100 GPU 上训练了 3 天。与之前的Video CLIP变体相比,ViCLIP在零样本设置下表现出显著的性能提升。
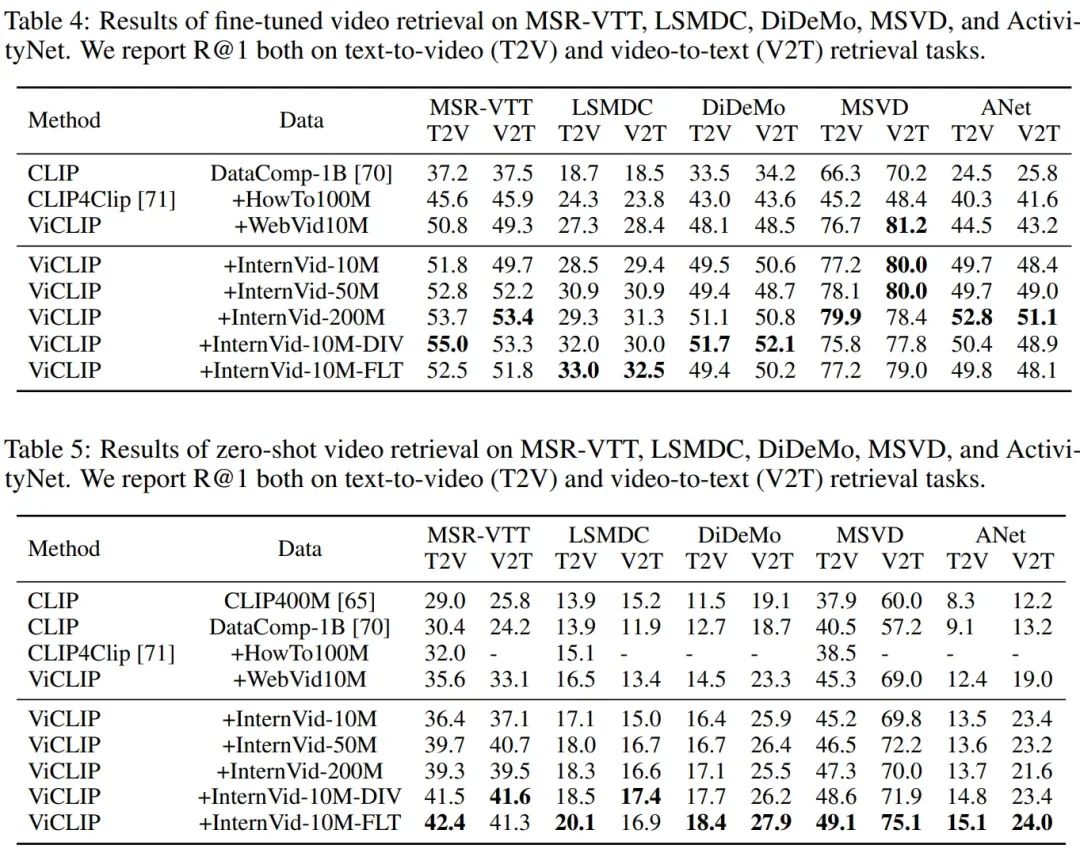
我们在InternVid的五个子集上学习ViCLIP,并在多个流行的视频相关基准测试中评估其性能,包括零样本和全微调设置。这五个子集分别是:随机采样的InternVid-10M、InternVid-50M,InternVid-200M,假设训练视频片段的多样性比数量更重要的InternVid-10M-DIV和假设文本-视频匹配度更重要的InternVid-10M-FLT。我们将InternVid-10M和InternVid-10M-DIV/-FLT与WebVid10M进行比较,同时使用InternVid-50M和InternVid-200M进一步验证视频-语言对比学习的数据显示性。具体性能表格可以参考原文,图6列出了检索任务的性能。
文生视频的探索
此外,我们还提供了一个经过特定的视频-文本关系和视觉美学过滤的子集,InternVid-Aes,它有助于生成高分辨率、无水印的视频。利用InternVid-Aes,一个简单的文本到视频的基线模型的视觉和定量的结果都可以明显提升。这些提供的资源为有兴趣进行多模态视频理解和生成的研究者和从业者提供了一个有力的工具。

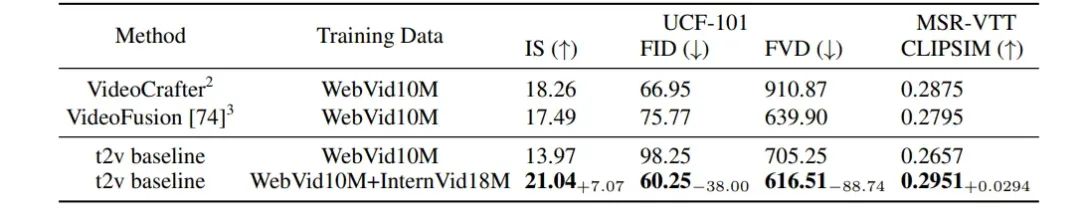
为了定量评估我们的模型,我们进行了零样本文本到视频的实验,并随机从UCF-101数据集中抽取了2020个视频,从MSRVTT数据集中抽取了2990个视频,并在图8中测试了CLIPSIM、IS、FID和FVD指标。
下载
InternVid 数据集可通过以下方式获取:
Hugging Face
·数据集metainfo:
https://huggingface.co/datasets/OpenGVLab/InternVid
·ViCLIP权重:
https://huggingface.co/OpenGVLab/ViCLIP
目前HuggingFace上已经开源了有InternVid-10M-FLT(默认)、InternVid-10M-DIV、InternVid-18M-Aes,通过选择不同的subset即可进行预览,这里提供了视频的id,开始和结束的时间戳,视频描述,美学分数和视频文本匹配度。您可以通过配合yt-dlp或video2dataset进行下载。
下载meta文件,您也可以通过以下指令(请第一次先登录网页获取权限后操作):
pip install -U huggingface_hubhuggingface-cli download --repo-type dataset --token hf_***(请注意替换成您的token) --resume-download --local-dir-use-symlinks False OpenGVLab/InternVid --local-dir InternVid_metainfo
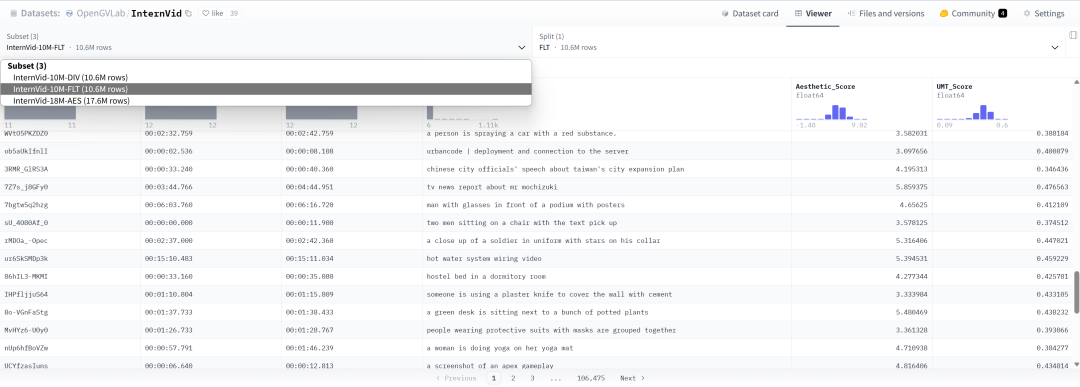
同时,我们也提供了涵盖了来源语种的信息您可以通过https://huggingface.co/datasets/OpenGVLab/InternVid-10M-FLT-INFO/下载
OpenDataLab (国内访问更加友好)
·InternVid-10M-FLT:
https://opendatalab.com/shepshep/InternVid
·InternVid-Aes: h
https://opendatalab.com/yinanhe/InternVid-14M-Aes
Github
·数据集信息及Model Zoo:
https://github.com/OpenGVLab/InternVideo/tree/main/Data/InternVid
·ViCLIP训练代码:
https://github.com/OpenGVLab/InternVideo/tree/main/Pretrain/ViCLIP
InternVid 的发布将推动视频理解和生成领域的研究和发展。未来,通用视频团队将继续对 InternVid 进行更新和完善,并致力于为研究人员和开发者提供更加优质的数据集和工具。
引用信息
如果您在研究或应用中使用了 InternVid 数据集或ViCLIP,欢迎您引用以下文献:
@inproceedings{wang2023internvid,
title={InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation},
author={Wang, Yi and He, Yinan and Li, Yizhuo and Li, Kunchang and Yu, Jiashuo and Ma, Xin and Chen, Xinyuan and Wang, Yaohui and Luo, Ping and Liu, Ziwei and Wang, Yali and Wang, Limin and Qiao, Yu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2023}
}

















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









