







 本文详细介绍了编译器从源码到可执行文件的全过程,包括配置、确定标准库和头文件位置、确定依赖关系、预编译、预处理、编译、连接、安装、操作系统连接、生成安装包和动态连接。通过这些步骤,编译器将源码转换为可在不同环境中运行的机器码。
本文详细介绍了编译器从源码到可执行文件的全过程,包括配置、确定标准库和头文件位置、确定依赖关系、预编译、预处理、编译、连接、安装、操作系统连接、生成安装包和动态连接。通过这些步骤,编译器将源码转换为可在不同环境中运行的机器码。
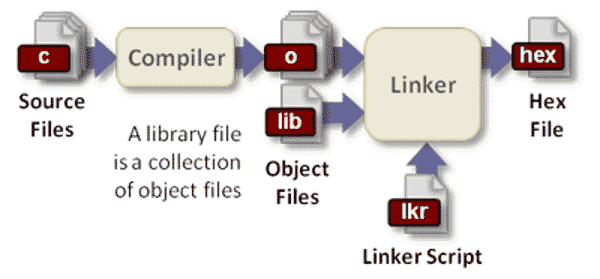
源码要运行,必须先转成二进制的机器码。这是编译器的任务。
比如,下面这段源码(假定文件名叫做test.c)。
#include <stdio.h>
int main(void)
{
fputs("Hello, world!\n", stdout);
return 0;
}
要先用编译器处理一下,才能运行。
$ gcc test.c
$ ./a.out
Hello, world!
对于复杂的项目,编译过程还必须分成三步。
$ ./configure
$ make
$ make install
这些命令到底在干什么?大多数的书籍和资料,都语焉不详,只说这样就可以编译了,没有进一步的解释。
本文将介绍编译器的工作过程,也就是上面这三个命令各自的任务。我主要参考了Alex Smith的文章《Building C Projects》。需要声明的是,本文主要针对gcc编译器,也就是针对C和C++,不一定适用于其他语言的编译。
第一步 配置(configure)
编译器在开始工作之前,需要知道当前的系统环境,比如标准库在哪里、软件的安装位置在哪里、需要安装哪些组件等等。这是因为不同计算机的系统环境不一样,通过指定编译参数,编译器就可以灵活适应环境,编译出各种环境都能运行的机器码。这个确定编译参数的步骤,就叫做"配置"(configure)。
这些配置信息保存在一个配置文件之中,约定俗成是一个叫做configure的脚本文件。通常它是由autoconf工具生成的。编译器通过运行这个脚本,获知编译参数。
configure脚本已经尽量考虑到不同系统
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









