






一、前言
你是否曾经遇到过打开一个文件,却发现里面全是乱码的情况?或者收到一封邮件,内容却显示成一堆看不懂的符号?这些令人头疼的乱码问题不仅影响我们的工作效率,还可能导致重要信息的丢失。
首先,让我们来了解一下什么是文字乱码。简单来说,乱码就是计算机无法正确解读文本编码,导致显示出错误或无意义的字符。这个问题常常发生在我们使用不同的操作系统、软件或者在不同语言环境下传输文件时。
二、乱码产生的可能原因
1. 编码不一致
这是最常见的乱码原因。当文件的实际编码和打开文件时使用的编码不一致时,就会出现乱码。例如,一个用UTF-8编码的文件,如果用GBK编码打开,就会出现乱码。
2. 字符集不支持
有时候,我们使用的字符集可能不支持某些特殊字符,这时也会导致乱码。比如,如果一个文本中包含中文字符,但是使用的是不支持中文的字符集,就会出现乱码。
3. 传输过程中的编码转换错误
在网络传输过程中,如果没有正确处理编码转换,也可能导致乱码。例如,一个网站使用UTF-8编码,但服务器却以GBK编码发送数据,接收端就会看到乱码。
4. 软件或系统默认编码设置不当
有些软件或操作系统有默认的编码设置,如果这个设置与实际文件的编码不符,也会导致乱码。
5. 文件损坏或格式错误
有时候,文件本身可能已经损坏或格式错误,这也可能导致乱码的出现。
三、基础知识
1. 什么是字符、字符集合、字符编码、字符集、字符序?
1. 字符
字符是计算机和电信技术中的一个单位,可以是字母、数字、标点符号、控制字符、图形符号或其他符号。在计算机系统中,字符通常以数字形式存储和处理,这些数字形式称为字符编码。
2. 字符集合
字符集合(Character Set)是指多个字符的集合,不同的字符集会包含不同数量和种类的字符。例如,ASCII字符集包含了基本的拉丁字母、数字和一些标点符号,而Unicode字符集则旨在包含世界上所有的字符,包括各种语言的文字、符号等。
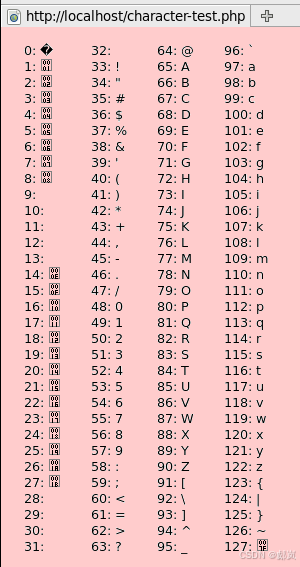
3. 字符编码
字符编码(Character Encoding)是一种映射规则,它将字符集中的字符映射到特定的数字或字节序列,以便在计算机系统中存储和传输。例如,ASCII编码使用一个字节的7位来表示字符,而Unicode编码使用不同长度的字节序列(如UTF-8、UTF-16、UTF-32)来表示字符。
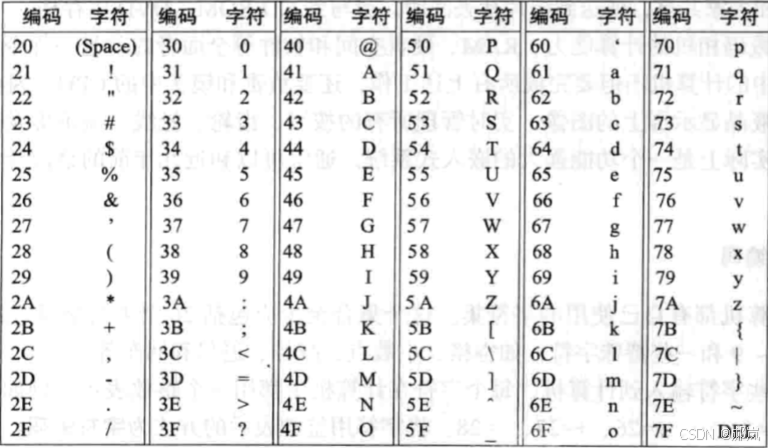
4. 字符集
字符集通常与字符编码混用,但严格来说,字符集定义了字符和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将字符的编号存储到计算机中。一个字符集可以有多种编码实现,就像一个接口可以有多种实现类一样。
5. 字符序
字符序(Collation)定义了字符的比较规则,它决定了字符在排序和检索时的行为。字符序通常与字符集相关联,并且可以指定是否区分大小写、重音等特性。例如,utf8_general_ci字符序表示使用UTF-8字符集,并且不区分大小写。
2.常见的字符编码以及使用场景
UTF-8编码
UTF-8 使用变长编码方式。最常用的字符编码之一,支持全球范围内的字符表示。每个字符的长度可以从 1 到 4 个字节不等。
UTF-16编码
定长编码方式,用于表示 Unicode 字符集。在 Java 中,字符串的内部表示采用 UTF-16 编码。
GBK编码
双字节编码方式。中文字符集编码,支持汉字和其他中文字符。
UTF-32编码
定长编码方式,用于表示 Unicode 字符集。每个字符占用固定的 4 个字节空间,适用于对字符随机访问或精确控制字符长度的需求。
Base64编码
用于将二进制数据转换成可打印字符的编码方式
ASCII编码
最早的字符编码方式,用于表示基本的英文字母、数字和特殊字符。ASCII 编码使用一个字节表示一个字符,范围为 0-127。
ISO-8859-1编码
也称为Latin-1编码,用于表示西欧语言字符集。ISO-8859-1 使用一个字节表示一个字符,范围为 0-255。
URL编码
用于在 URL 中表示特殊字符和非 ASCII 字符。通过将特殊字符转换为 %xx 的形式,其中 xx 是字符的 ASCII 值的十六进制表示。
HTML编码
用于在 HTML 中表示特殊字符和保留字符。将特殊字符转换为 &entity; 的形式,其中 entity 是特定字符的名称或编号。
Unicode编码
Unicode 是一种字符集,定义了字符与码点之间的映射关系。在 Java 中,字符串使用 UTF-16 编码表示 Unicode 字符。
Hex编码
Hex编码是一种将字节数据转换为十六进制字符串的编码方式。它将每个字节转换为两个十六进制字符,从而以可读的方式表示二进制数据。
3. 使用场景
| 编码方式 | 使用场景 |
|---|---|
| UTF-8编码 | 互联网文本传输和存储,多语言环境和国际化应用 |
| UTF-16编码 | Windows操作系统,Java编程语言,多语言字符文本处理 |
| GBK编码 | 中文汉字编码和处理,中国大陆和台湾地区常见 |
| UTF-32编码 | 精确表示所有Unicode字符,不常用于存储空间敏感的场景 |
| Base64编码 | 二进制数据传输和存储,例如在电子邮件中传输附件 |
| ASCII编码 | 英文字符编码,常用于文本传输、数据存储、编程和键盘输入等场景 |
| SO-8859-1编码 | 常用于西欧语言环境下的文本处理和传输 |
| URL编码 | 将URL中的非ASCII字符转换为%xx形式,保证传输和处理的正确性 |
| HTML实体编码 | 将HTML中的特殊字符转换为实体引用,避免与HTML标记冲突 ,常用于Web开发和网页显示中 |
| Unicode编码 | 对全球范围字符的唯一标识,字符转换和互通的基础,用于处理多语言字符文本和实现Unicode字符的精确表示 |
| Hex编码 | 二进制数据转换为十六进制字符串,常用于调试和数据处理 |

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









