









自定义测试报告
先来看下最终的实现效果:
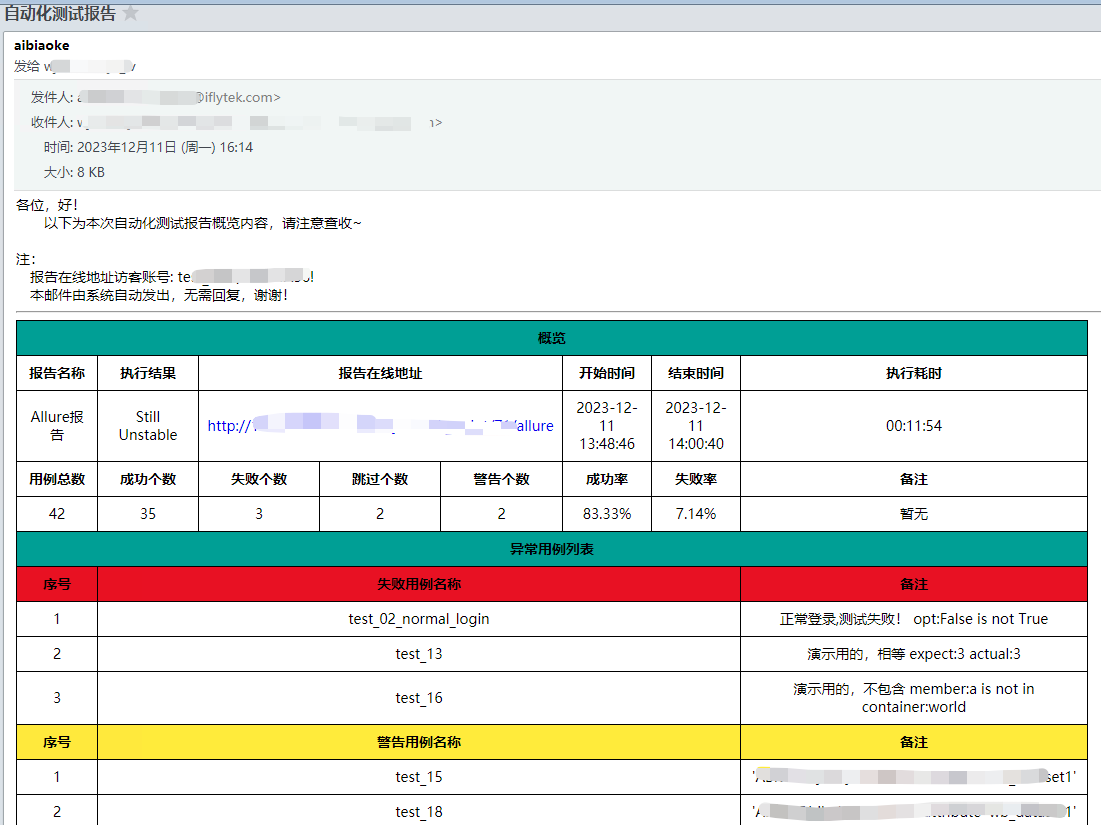
准备测试报告模版
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Demo</title>
<style>
table {
border-collapse: collapse;
width: 80%;
}
th, td {
border: 1px solid black;
padding: 8px;
text-align: center;
}
th, th {
border: 1px solid black;
padding: 8px;
text-align: center;
}
</style>
</head>
<body>
各位,好!<br>
以下为本次自动化测试报告概览内容,请注意查收~<br><br>
注:<br>
报告在线地址访客账号: xxxx/xxxx<br>
本邮件由系统自动发出,无需回复,谢谢!
<hr>
<table>
<tbody>
<tr>
<th colspan="8" style="background-color: #009f95">概览</th>
</tr>
<tr>
<th>报告名称</th>
<th>执行结果</th>
<th colspan="3" style="text-align: center">报告在线地址</th>
<th>开始时间</th>
<th style="width:auto">结束时间</th>
<th>执行耗时</th>
</tr>
<tr>
<td>Allure报告</td>
<td>${BUILD_STATUS}</td>
<td colspan="3"><a href="${PROJECT_URL}${BUILD_NUMBER}/allure">${PROJECT_URL}${BUILD_NUMBER}/allure</a></td>
<td>s_time</td>
<td>e_time</td>
<td>all_time</td>
</tr>
<tr>
<th>用例总数</th>
<th>成功个数</th>
<th>失败个数</th>
<th>跳过个数</th>
<th>警告个数</th>
<th>成功率</th>
<th>失败率</th>
<th>备注</th>
</tr>
<tr>
<td>${TEST_COUNTS,var="total"}</td>
<td>${TEST_COUNTS,var="pass"}</td>
<td>fail_cnt</td>
<td>${TEST_COUNTS,var="skip"}</td>
<td>broken_cnt</td>
<td>pass_pct</td>
<td>fail_pct</td>
<td>暂无</td>
</tr>
<tr>
<th colspan="8" style="background-color: #009f95">异常用例列表</th>
</tr>
</tbody>
</table>
</body>
</html>
展示效果如下:
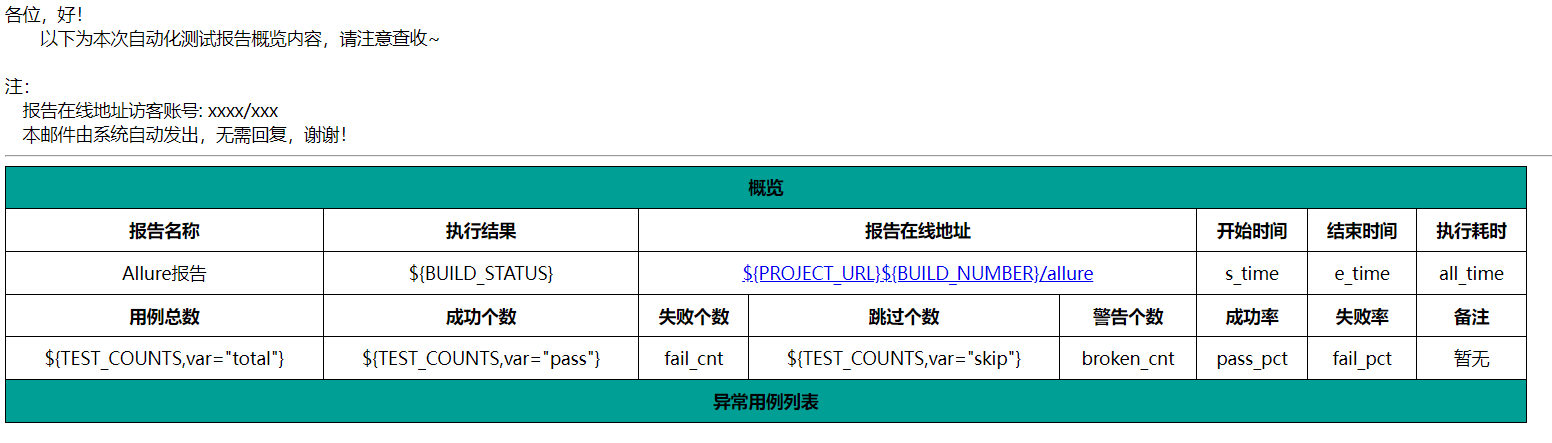
模板中的部分信息直接用字符串代替了,后面通过解析测试结果文件获取开始时间、结束时间、耗时、成功、失败跳过用例信息后替换部分内容,增加异常用例信息。
为什么不直接使用
Content Token Reference中的成功、失败、跳过信息呢?

jenkins的变量中有成功、失败、跳过数量,但是这里的告警状态也算到了失败中。它会影响最后计算失败率,这里由于单独统计了告警的数量,所以不使用默认模版的变量。
解析测试结果
虽然这里配置了构建后生成allure报告,但是为了方便读取结果所以在构建时就生成了allure报告,然后自己实现从allure报告中获取执行过程数据。
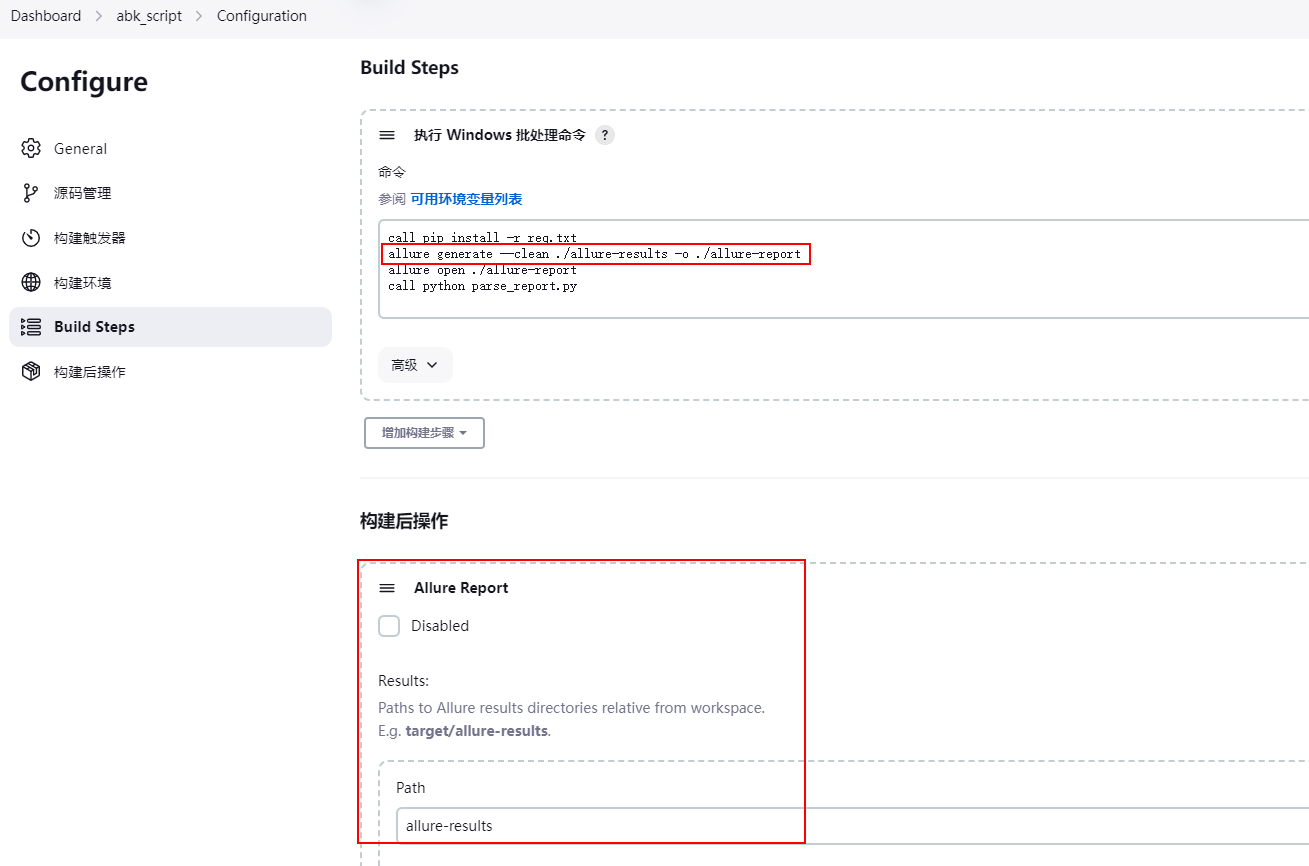
解析结果生成邮件html脚本:
# -*- coding:utf8 -*-
"""
@ Author: wjlv4
@ File: parse_report.py
@ Time: 2023/12/7
@ Contact: wenju_lv@163.com
@ Desc: 解析allure报告数据
"""
from datetime import datetime
import json
from pathlib import Path
from os import sep
import sys
from pathlib import Path
sys.path.append(str(Path(__file__).parent.parent / 'auto_model'))
from Base.common.operate_log import Log
class ParseReport:
def __init__(self, report_path, email_tmp_file='template.html'):
if Path(report_path).exists():
self.report_path = report_path
self.cases_file = report_path + sep + 'data' + sep + 'behaviors.json'
self.detail_dir = report_path + sep + 'data' + sep + 'test-cases'
else:
raise NotADirectoryError(f'dir not exist! {report_path}')
self.email_file = email_tmp_file
def get_res_data(self):
# 初始化计数器和其他变量
res = {
'all_cnt': 0,
'pass_cnt': 0,
'fail_cnt': 0,
'skip_cnt': 0,
'broken_cnt': 0,
'other_cnt': 0,
'pass_pct': 0,
'fail_pct': 0,
'fail_tests': [],
'skip_tests': [],
'broken_tests': [],
'other_tests': [],
's_time': 0,
'e_time': 0,
'all_time': None
}
Log.info('开始收集测试报告结果 ...')
data = self._load_json(self.cases_file)
# 遍历数据集
for result in data['children']:
# 统计测试结果
if 'status' in result:
if result['status'] == 'passed':
res['pass_cnt'] += 1
elif result['status'] == 'failed':
res['fail_cnt'] += 1
res['fail_tests'].append(self.get_overview(result['uid']))
elif result['status'] == 'skipped':
res['skip_cnt'] += 1
res['skip_tests'].append(self.get_overview(result['uid']))
elif result['status'] == 'broken':
res['broken_cnt'] += 1
res['broken_tests'].append(self.get_overview(result['uid']))
else:
res['other_cnt'] += 1
res['other_tests'].append(self.get_overview(result['uid']))
res['all_cnt'] += 1
res['pass_pct'] = '%.2f%%' % (res['pass_cnt'] / res['all_cnt'] * 100)
res['fail_pct'] = '%.2f%%' % (res['fail_cnt'] / res['all_cnt'] * 100)
# 获取开始和结束时间
if result['time'] and 'start' in result['time']:
start = result['time']['start'] // 1000
if not res['s_time'] or start < res['s_time']:
res['s_time'] = start
if result['time'] and 'stop' in result['time']:
stop = result['time']['stop'] // 1000
if not res['e_time'] or stop > res['e_time']:
res['e_time'] = stop
# 计算总耗时
if res['s_time'] and res['e_time']:
res['all_time'] = self.format_time_difference(res['e_time'], res['s_time'])
res['s_time'] = datetime.fromtimestamp(res['s_time']).strftime('%Y-%m-%d<br>%H:%M:%S')
res['e_time'] = datetime.fromtimestamp(res['e_time']).strftime('%Y-%m-%d<br>%H:%M:%S')
return res
@staticmethod
def _load_json(file_path):
path = Path(file_path).absolute()
if not path.exists():
print(f'file not exist! {file_path}')
else:
return json.load(open(path, 'r', encoding='utf8'))
def get_overview(self, uid):
"""
根据uid对应对的详情文件获取总览信息
:param uid:
:return:
"""
detail_data = self._load_json(self.detail_dir + sep + uid + '.json')
status_msg = detail_data.get('statusMessage', '')
msg = status_msg.split(':', 1)[-1]
name = detail_data.get('name', '')
return name, msg
@staticmethod
def format_time_difference(timestamp1, timestamp2):
time_difference = abs(timestamp2 - timestamp1)
# 计算时间差的各个组成部分
hours = time_difference // 3600
minutes = (time_difference % 3600) // 60
seconds = time_difference % 60
hours = str(hours).rjust(2, '0')
minutes = str(minutes).rjust(2, '0')
seconds = str(seconds).rjust(2, '0')
# 根据时间差返回相应的字符串表示
if int(hours) > 0:
return f"{hours}:{minutes}:{seconds}"
elif int(minutes) > 0:
return f"00:{minutes}:{seconds}"
else:
return f"00:00:{seconds}"
def update_file(self):
"""
主入口,读取模版文件后生成测试报告文件
:return:
"""
res_data = self.get_res_data()
Log.info('生成邮件模板中 ...')
with open(self.email_file, 'r', encoding='utf8') as f_r:
content = f_r.read()
# 处理时间
new_content = content.replace('s_time', res_data['s_time']).replace('e_time', res_data['e_time']).replace(
'all_time', res_data['all_time'])
# 处理百分比
new_content = new_content.replace('fail_cnt', str(res_data['fail_cnt'])).replace('broken_cnt', str(res_data['broken_cnt'])).replace('pass_pct', str(
res_data['pass_pct'])).replace('fail_pct', str(res_data['fail_pct']))
# 增加异常用例类型
abnormal_case_temp = '<tr><td>index</td><td colspan="6">case_name</td><td>mark</td></tr>'
th_html_temp = '<tr><th style="xss">序号</th><th colspan="6" style="xss">失败用例名称</th><th style="xss">备注</th></tr>'
abnormal_html = ''
if res_data['fail_tests']:
f_html = th_html_temp.replace('xss', "background-color: #e81123")
for index, f_case in enumerate(res_data['fail_tests'], 1):
f_html += abnormal_case_temp.replace('index', str(index)).replace('case_name', f_case[0]).replace(
'mark', f_case[1])
abnormal_html += f_html
if res_data['broken_tests']:
f_html = th_html_temp.replace('xss', "background-color: #FFEB3B").replace('失败', '警告')
for index, f_case in enumerate(res_data['broken_tests'], 1):
f_html += abnormal_case_temp.replace('index', str(index)).replace('case_name', f_case[0]).replace(
'mark', f_case[1])
abnormal_html += f_html
if res_data['skip_tests']:
f_html = th_html_temp.replace('xss', "background-color: #9f9f9f").replace('失败', '跳过')
for index, f_case in enumerate(res_data['skip_tests'], 1):
f_html += abnormal_case_temp.replace('index', str(index)).replace('case_name', f_case[0]).replace(
'mark', f_case[1])
abnormal_html += f_html
with open('email.html', 'w', encoding='utf8') as f_w:
f_w.write(new_content.replace(r'</tbody>', abnormal_html + r'</tbody>'))
Log.info('邮件模板生成完成 ...')
if __name__ == '__main__':
pr = ParseReport('allure-report')
pr.update_file()
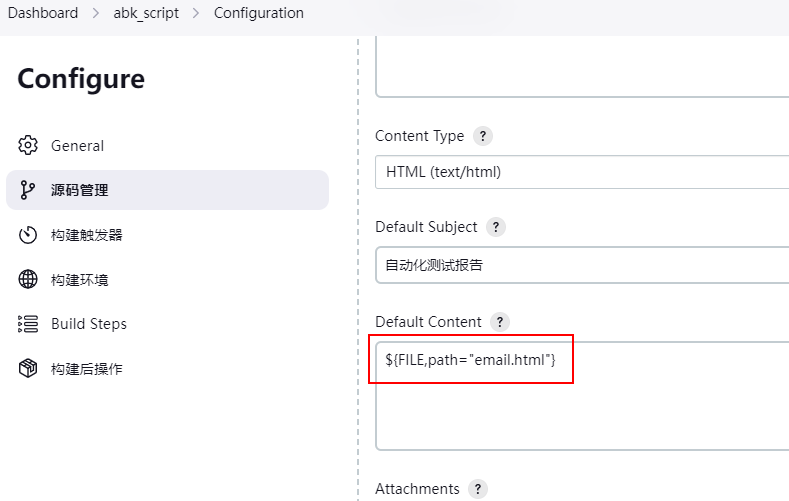
配置邮件内容
指定生成的html作为邮件内容发送:
大功告成~
















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









