









全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。 它可以快速地储存、搜索和分析海量数据。
官方文档:英文官方文档
基本结构
1. index (索引) :在SlasticSearch中存在多个index,类似于mysql中的数据库。
2.type (类型) :在一个index中可以存在多个type,类似于数据库中的表。
3.document(文档) : 在type中存在多个,其放的是JSON数据,其中的储存方式类似key:value。
ElasticSearch结构图为下

ElasticSearch下载
1.拖取的对应的image。
docker pull elasticsearch:7.12.1 //存储和检索数据
docker pull kibana:7.12.1 //可视化检索数据
2.进行安装
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-netdocker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
#- `-e "cluster.name=es-docker-cluster"`:设置集群名称
#- `-e "http.host=0.0.0.0"`:监听的地址,可以外网访问
#- `-e "ES_JAVA_OPTS=-Xms512m -Xmx512m"`:内存大小
#- `-e "discovery.type=single-node"`:非集群模式
#- `-v es-data:/usr/share/elasticsearch/data`:挂载逻辑卷,绑定es的数据目录
#- `-v es-logs:/usr/share/elasticsearch/logs`:挂载逻辑卷,绑定es的日志目录
#- `-v es-plugins:/usr/share/elasticsearch/plugins`:挂载逻辑卷,绑定es的插件目录
#- `--privileged`:授予逻辑卷访问权
#- `--network es-net` :加入一个名为es-net的网络中
#- `-p 9200:9200`:端口映射配置
运行结果图为下:

访问对应的端口,结果图为下:

3.创建kibana容器
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://1.9.214.176:9200 -p 5601:5601 \
-d kibana:7.12.1访问5601端口,安装效果图:
安装IK分词器
进入elasticsearch容器中下载IK分词器。
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch进行测试
 在使用IK分词器使用我们可以设置analyzer的配置
在使用IK分词器使用我们可以设置analyzer的配置
可以设置的配置为下:
-
ik_smart:最少切分(优点:节省空间。缺点:模糊匹配是可能会匹配不到,如:分词成"程序员",但此时我们只搜索到"程序") -
ik_max_word:最细切分 (优缺点与ik_smart正好相反)
自定义禁用词汇和创建新型词汇
1.进入elasticsearch容器中。
docker exec -it 容器id /bin/bash2.下载vim (centos版本)
cd /etc/yum.repos.d/
sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
yum makecache
yum update -y
yum -y install vim
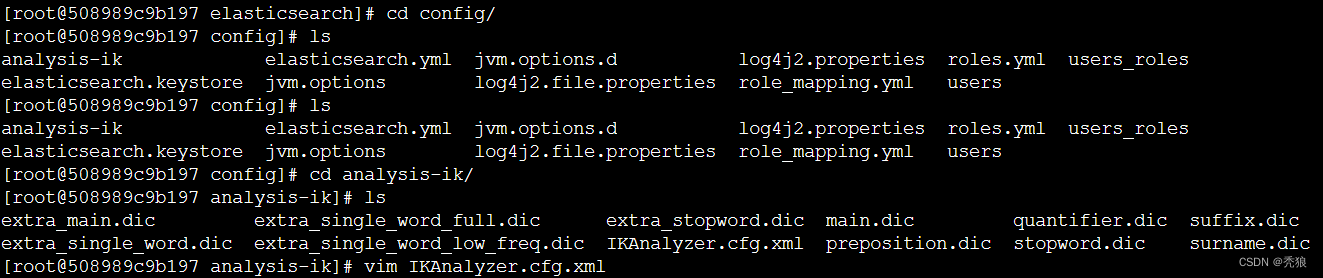
3.找到IKAnalyzer.cfg.xml
4.进行编辑
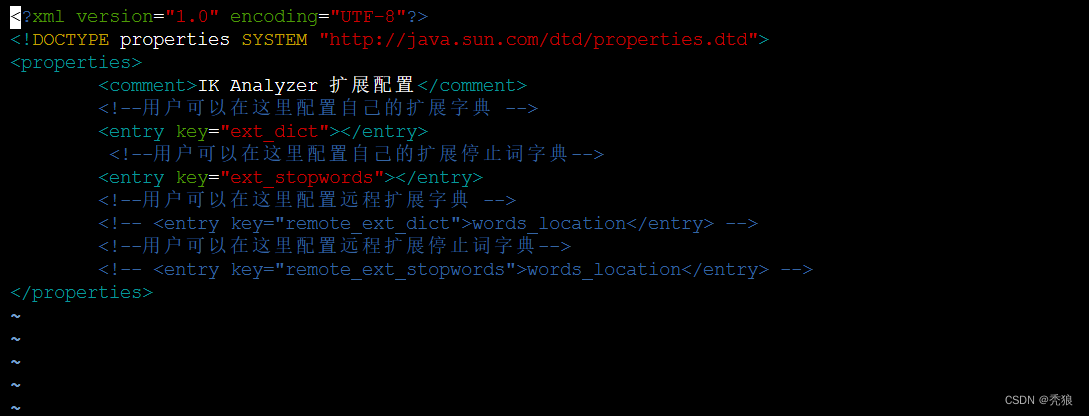 创建对应名称的文件,在此文件的同级目录下创建。
创建对应名称的文件,在此文件的同级目录下创建。
ext_dict文件就是拓展词汇的文件。
ext_stopwords文件就是禁用词汇的文件。
![]()
直接编辑即可。

重启对应的容器,测试结果为下:
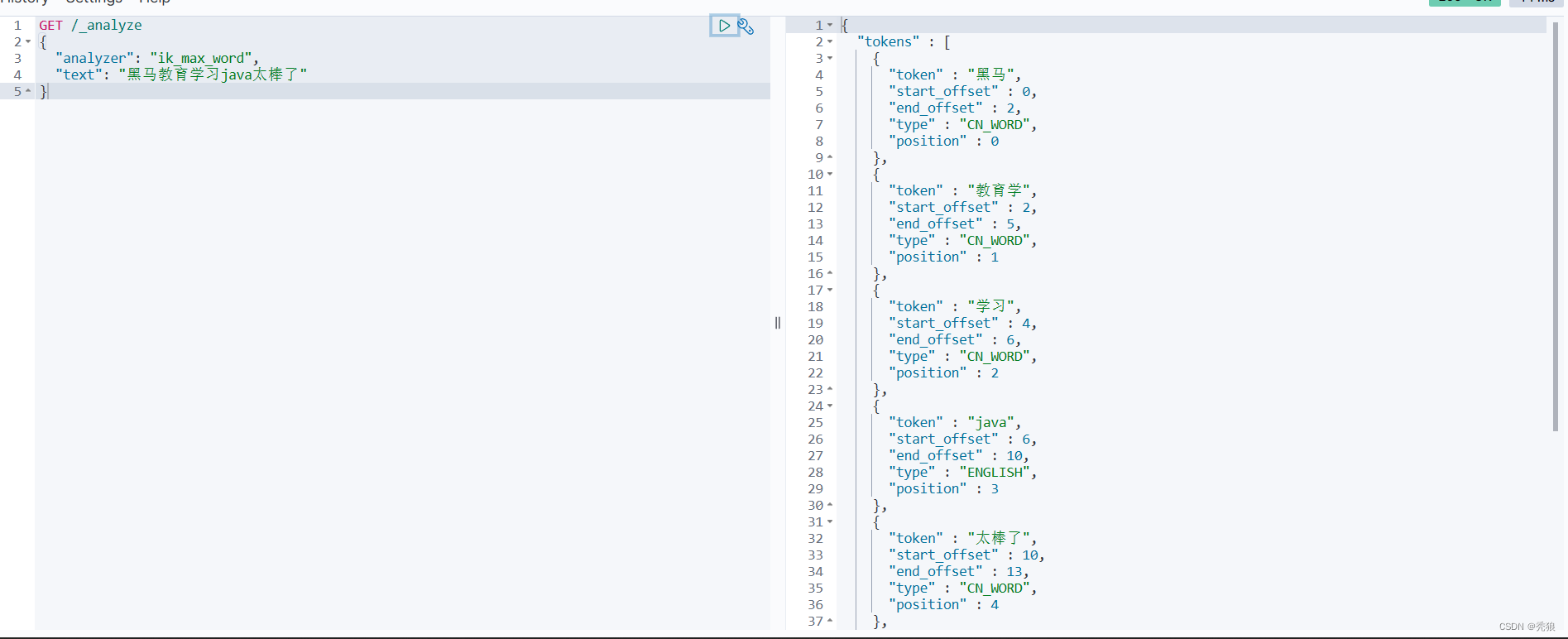
”教育”词汇就不会被识别。
ElasticSearch的使用
elasticSearch在mysql中的映射。
mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址),如果是keyword类型的话吗,我们在编写DSL时需要指定.keyword,否则会报错。
-
数值:long、integer、short、byte、double、float、
-
布尔:boolean
-
日期:date
-
对象:object
-
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
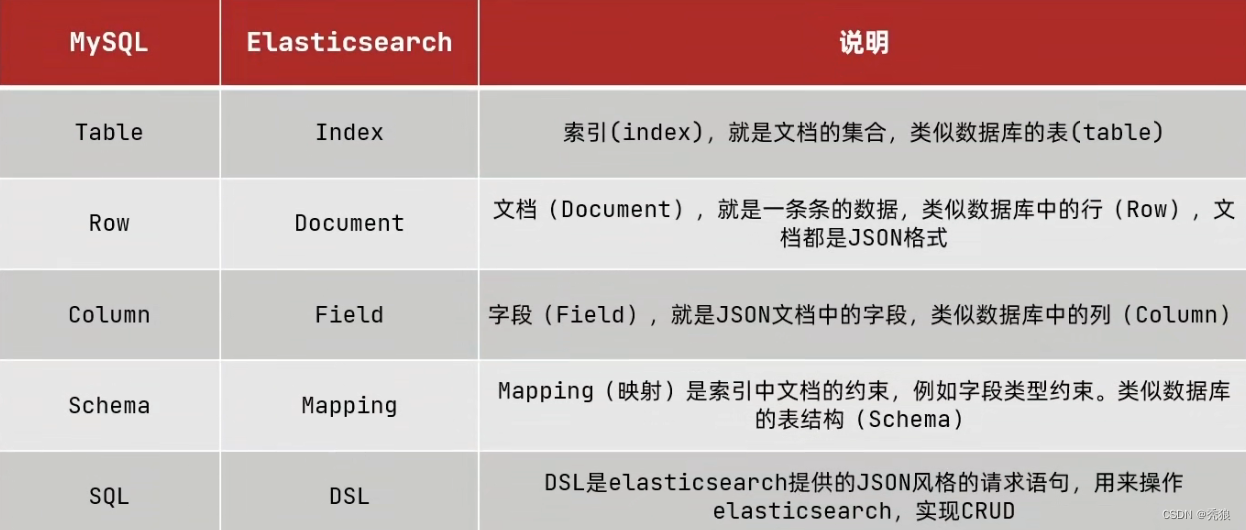
一个简单的DLS为下(json):
PUT /tolen
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart"
},
"age": {
"type": "integer",
"index": false
},
"email": {
"type": "keyword",
"index": false
},
"hobby": {
"type": "text"
}
}
}
}DSL查询用法
索引库的CRUD
新增操作:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}执行效果为下

更改操作 :
本质上索引库是不支持修改操作的,但其正常在原有的基础上新增。(新增的字段名是不能重复的,否则会修改失败)
格式为下:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}删除操作:
DELETE /索引库名称
执行效果为下

查询操作:
GET /索引库名称执行效果为下
文档的CRUD
-
创建文档:POST /{索引库名}/_doc/文档id { json文档 }
-
查询文档:GET /{索引库名}/_doc/文档id
-
删除文档:DELETE /{索引库名}/_doc/文档id
-
修改文档:
-
全量修改:PUT /{索引库名}/_doc/文档id { json文档 } (本质上就是先将对应的文档删除,如何再将对应的文档进行创建)
-
增量修改:POST /{索引库名}/_update/文档id { "doc": {字段}}
-
查询所有:查询出所有数据,一般测试用。例如:match_all。
格式代码为下:
#没有搜索条件
GET /索引库的名字/_search
{
"query": {
"match_all": {
}
}
}
效果图为下:

全文搜索查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。(可以理解成模糊匹配)
例如:
-
match_query
-
multi_match_query
格式代码为下:
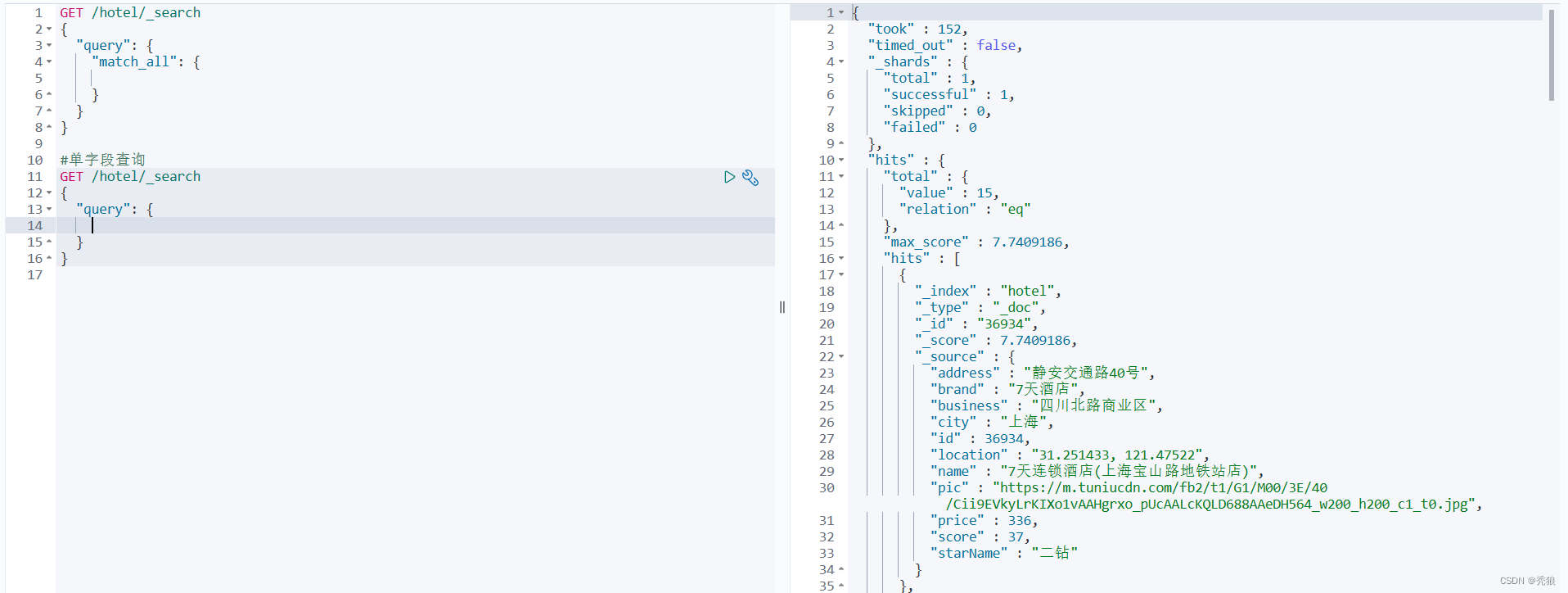
单字段查询
#单字段查询
#field中填写字段名,text中填写对应搜索的值
GET /索引库的名字/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
效果图为下:
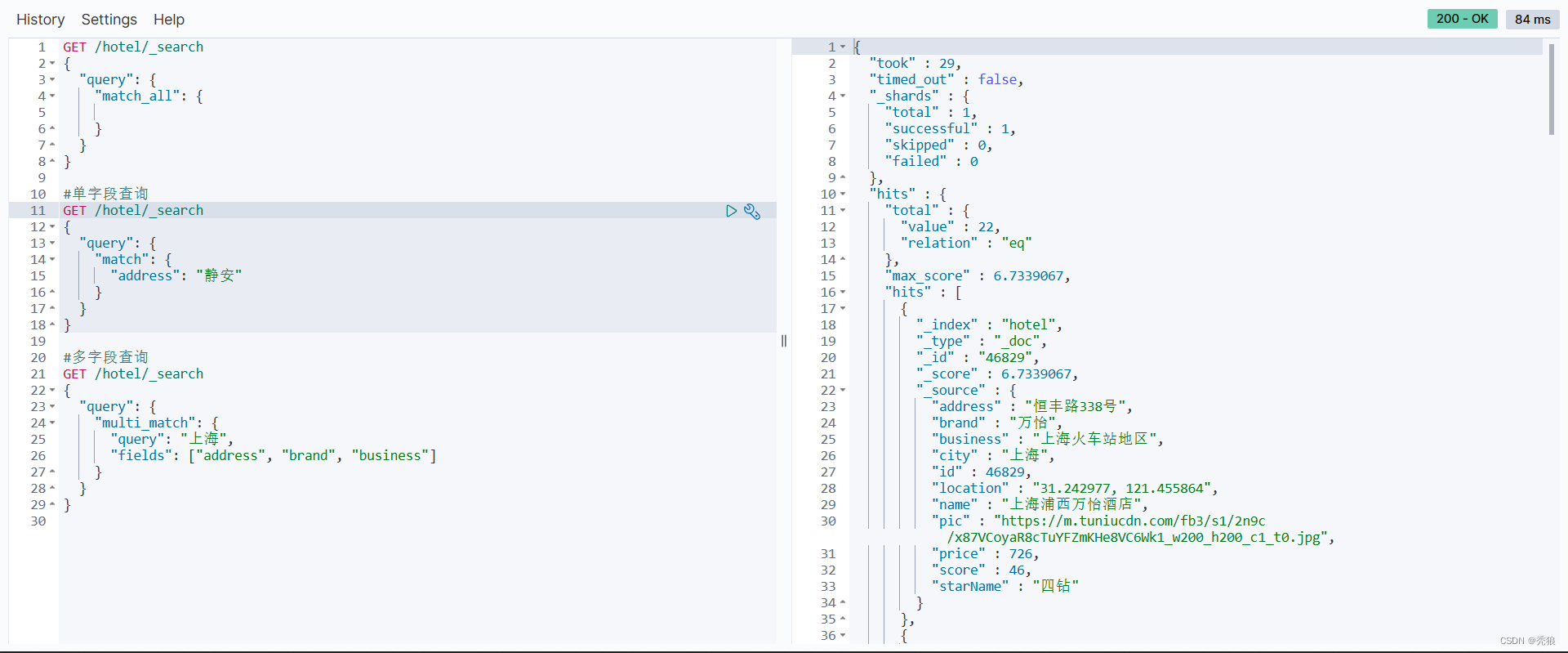
多字段查询
#多字段查询
#query中的值表示搜索的值
#fields表示应该字段数组
GET /索引库的名字/_search
{
"query": {
"multi_match": {
"query": "",
"fields": []
}
}
}效果图为下:
精准查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。(可以理解成精准匹配)
例如:
-
range
-
term
格式代码为下:
range查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段。
#range查询
#在field中填写对应的搜索字段
#gte表示大于等于, gt表示大于
#lte表示小于等于, lt表示小于
#range查询
GET /索引库的名字/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10,
"lte": 20
}
}
}
}效果图:
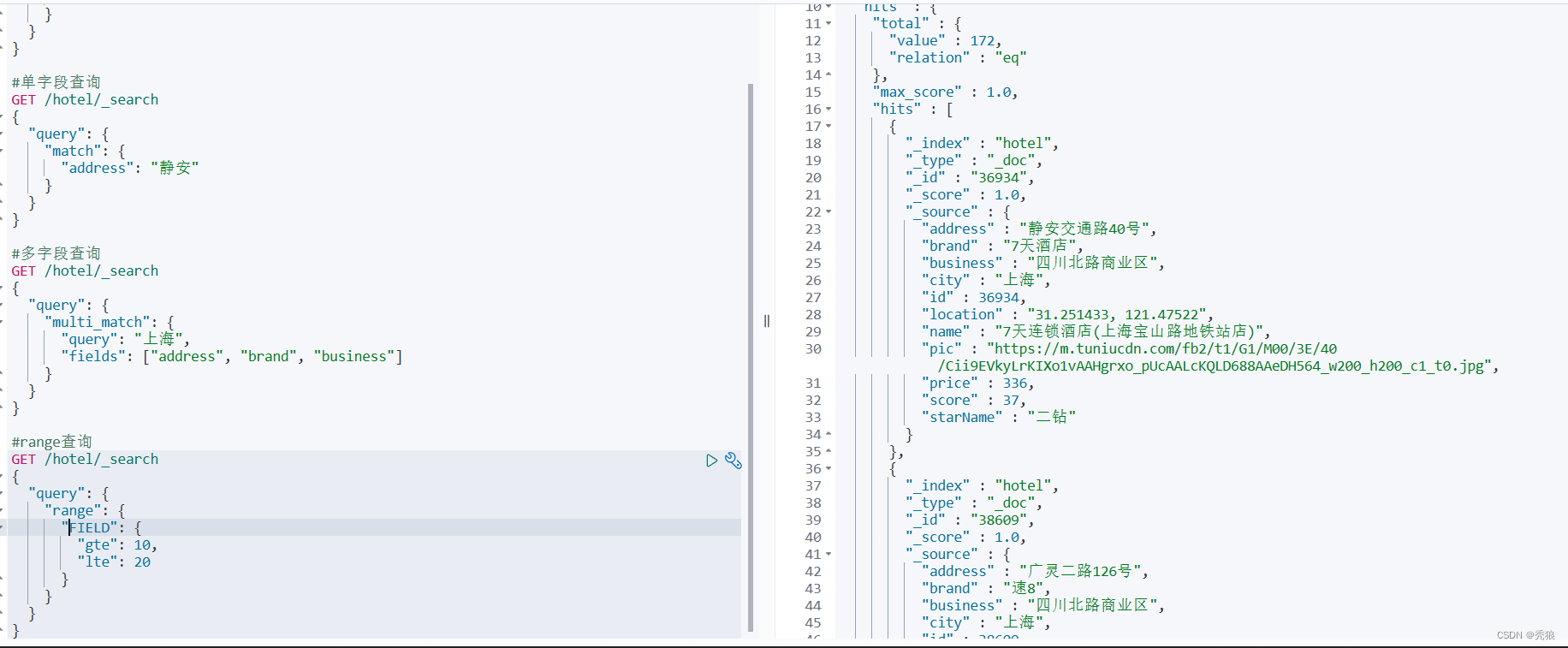
term查询:根据数值范围查询,可以是数值、日期的范围。
#field表示查询的字段,VALUE表示精准匹配的值
#如果FIELD的类型是keyword的话,我们的写法就是 FIELD.keyword
GET /索引库的名字/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}效果图:
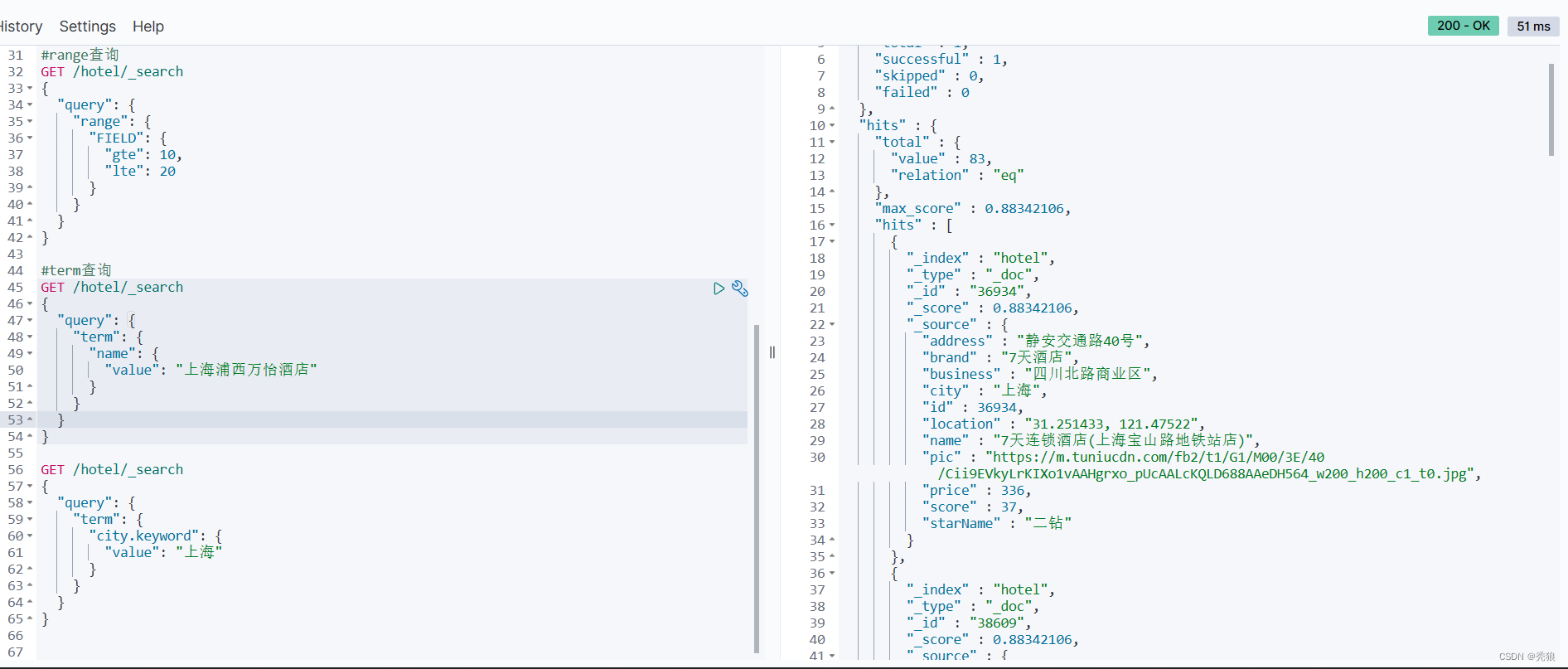
地理坐标查询:附近查询,就是以当前点为中心做一个圆。
格式代码为下:
#附近查询
#distance表示设置的最大搜索距离
#FIELD表示对应的位置字段
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": 15km,
"FIELD": ""
}
}
}
必须保证该字段是geo_point类型,否则会出现类型不匹配的问题。
相关性算分
在elasticsearch的早期版本中使用的算法

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法

elasticsearch会根据词条和文档的相关度做打分,算法由两种:
-
TF-IDF算法
-
BM25算法,elasticsearch5.1版本后采用的算法
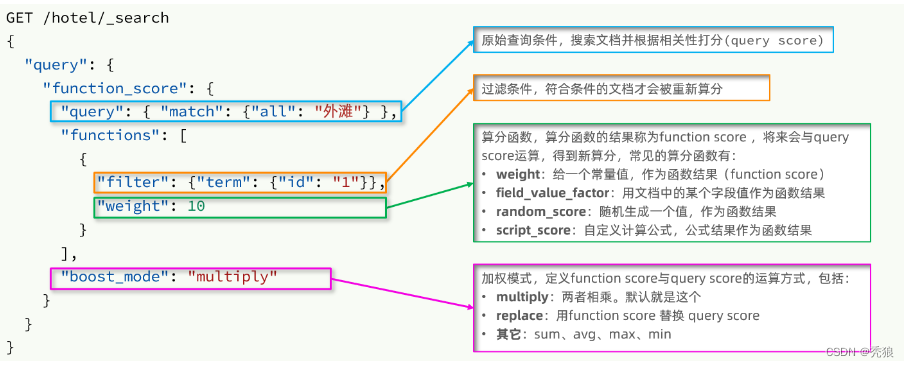
算分函数查询:要想控制相关性算分,就需要利用elasticsearch中的function score 查询。(打分的字段越多,查询的性能也越差 )
function score 查询中包含四部分内容:
-
原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
-
过滤条件:filter部分,符合该条件的文档才会重新算分
-
算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
-
weight:函数结果是常量
-
field_value_factor:以文档中的某个字段值作为函数结果
-
random_score:以随机数作为函数结果
-
script_score:自定义算分函数算法
-
-
运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
-
multiply:相乘
-
replace:用function score替换query score
-
其它,例如:sum、avg、max、min
-
格式代码为下:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"FIELD": "TEXT"
}
},
"functions": [
{"filter": {
},
"weight": 1
}
],
"boost_mode": "multiply"
}
}
}
效果图为下:
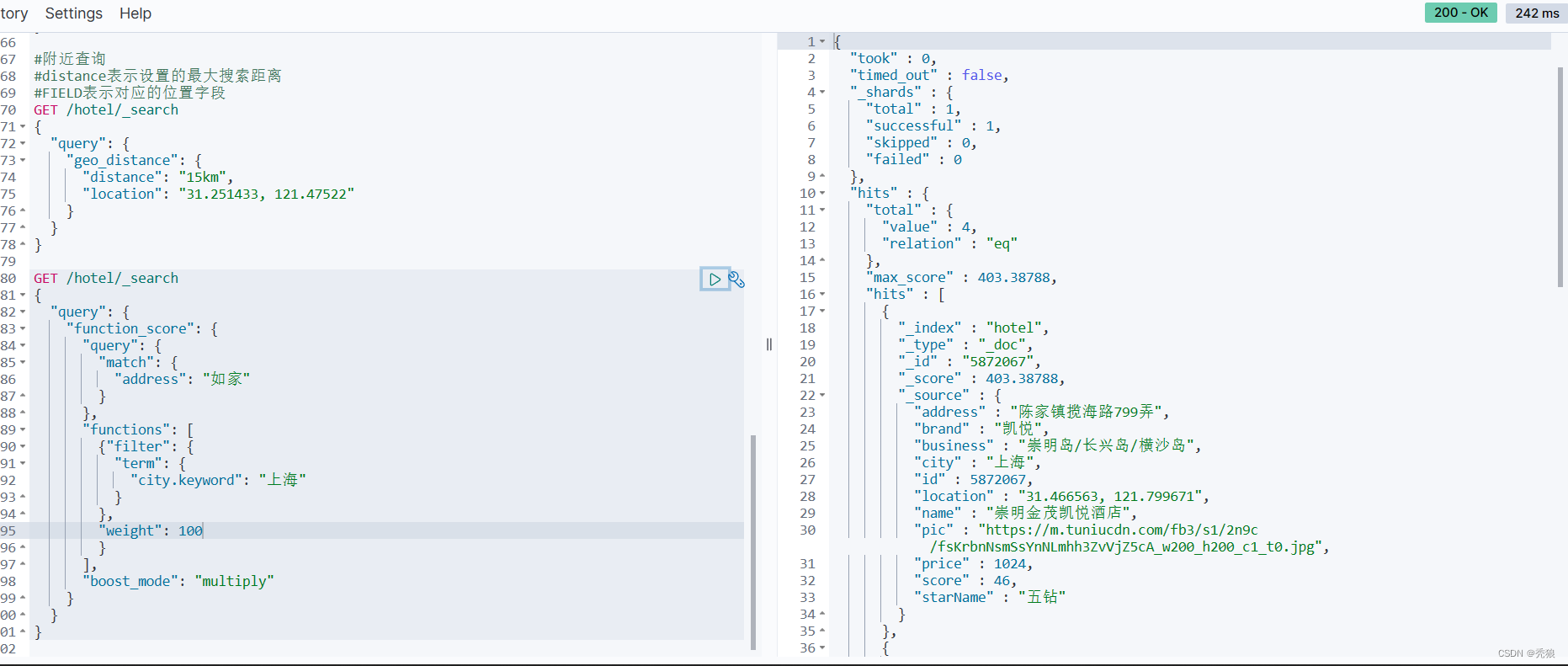
function score的运行流程如下:
-
1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
-
2)根据过滤条件,过滤文档
-
3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
-
4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
布尔查询 :布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。
子查询的组合方式有:
-
must:必须匹配每个子查询,类似“与”
-
should:选择性匹配子查询,类似“或”
-
must_not:必须不匹配,不参与算分,类似“非”
-
filter:必须匹配,不参与算分
格式代码为下:
#bool查询
#在[]中编写对应的条件
GET /hotel/_search
{
"query": {
"bool": {
"must": [],
"should": [],
"must_not": [],
"filter": []
}
}
}效果图为下:

bool查询有几种逻辑关系?
-
must:必须匹配的条件,可以理解为“与”
-
should:选择性匹配的条件,可以理解为“或”
-
must_not:必须不匹配的条件,不参与打分
-
filter:必须匹配的条件,不参与打分
排序:elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
普通字段排序
代码格式为下:
#在query中编写查询的条件
#sort中编写排序的字段,可以是多个
#排序有 desc, asc
GET /hotel/_search
{
"query": {},
"sort": [
{
"FIELD": {
"order": "desc"
}
}
]
}效果图为下:

地理位置排序
格式代码为下:
#query表示查询条件
#_geo_distance就是进行地理位置排序
#经纬度也可以写成字符串("经度", 纬度)
GET /hotel/_search
{
"query": {},
"sort": [
{
"_geo_distance": {
"FIELD": {
"lat": 40,
"lon": -70
},
"order": "asc",
"unit": "km"
}
}
]
}分页:elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
格式代码为下:
#query表示请求条件
#from表示分页的开始位置
#size表示每页的大小
GET /hotel/_search
{
"query": {},
"from": 0,
"size": 5,
"sort": [
{
"price": {
"order": "desc"
}
}
]
}效果图为下:
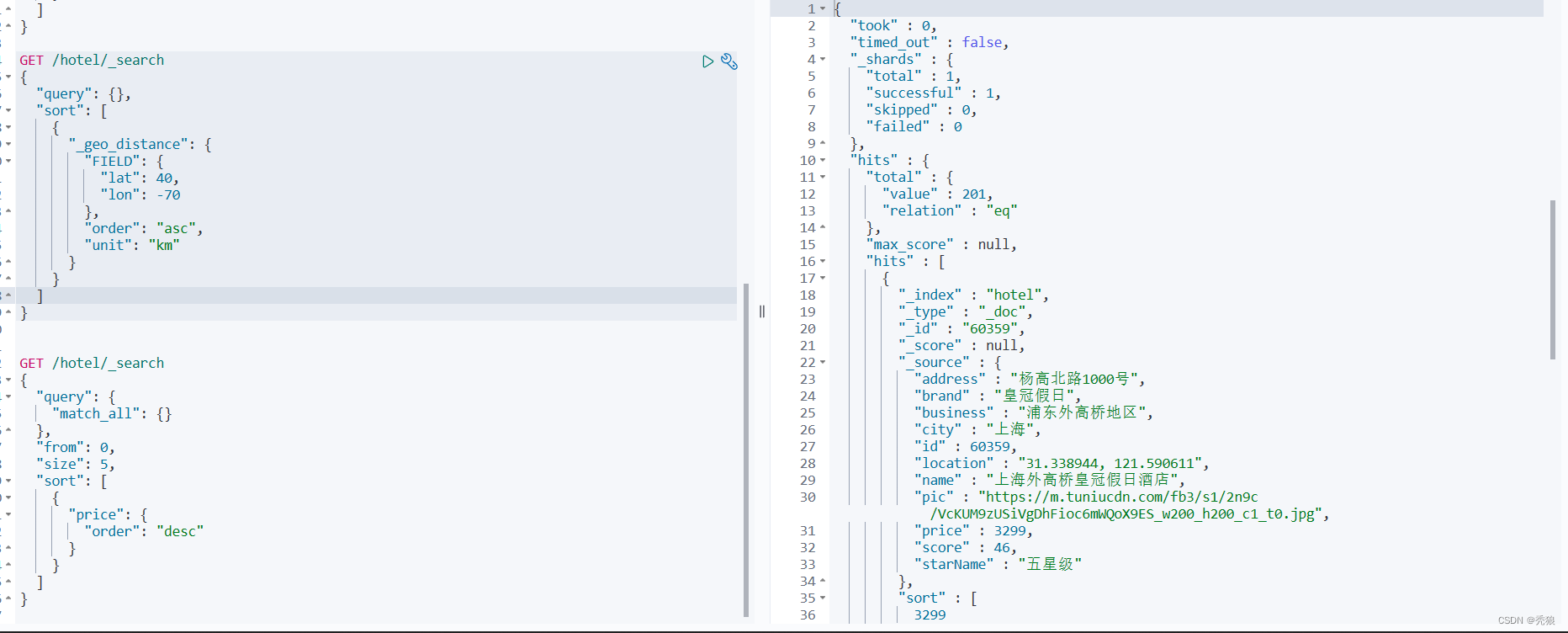
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,ES提供了两种解决方案,官方文档:
-
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
-
scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
分页查询的常见实现方案以及优缺点:
-
from + size:-
优点:支持随机翻页
-
缺点:深度分页问题,默认查询上限(from + size)是10000
-
场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
-
-
after search:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:只能向后逐页查询,不支持随机翻页
-
场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
-
-
scroll:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:会有额外内存消耗,并且搜索结果是非实时的
-
场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
-
高亮
高亮显示的实现分为两步:
-
1)给文档中的所有关键字都添加一个标签,例如
<em>标签 -
2)页面给
<em>标签编写CSS样式
格式代码为下:
#query表示查询的条件,就是要高亮的关键字
#fields中可以设置多个字段的高亮
#pre_tags表示在要高亮的字段前添加的标签
#pos_tags表示在要高亮的字段后添加的标签
#如果需要每个字段中包含对应的关键字就高亮的话,我们需要在FIELD中添加属性:required_field_match=false (不进行字段匹配)
GET /hotel/_search
{
"query": {
"match": {}
},
"highlight": {
"fields": {
"FIELD": {
"pre_tags": "",
"post_tags": ""
}
}
}
}
效果图为下:
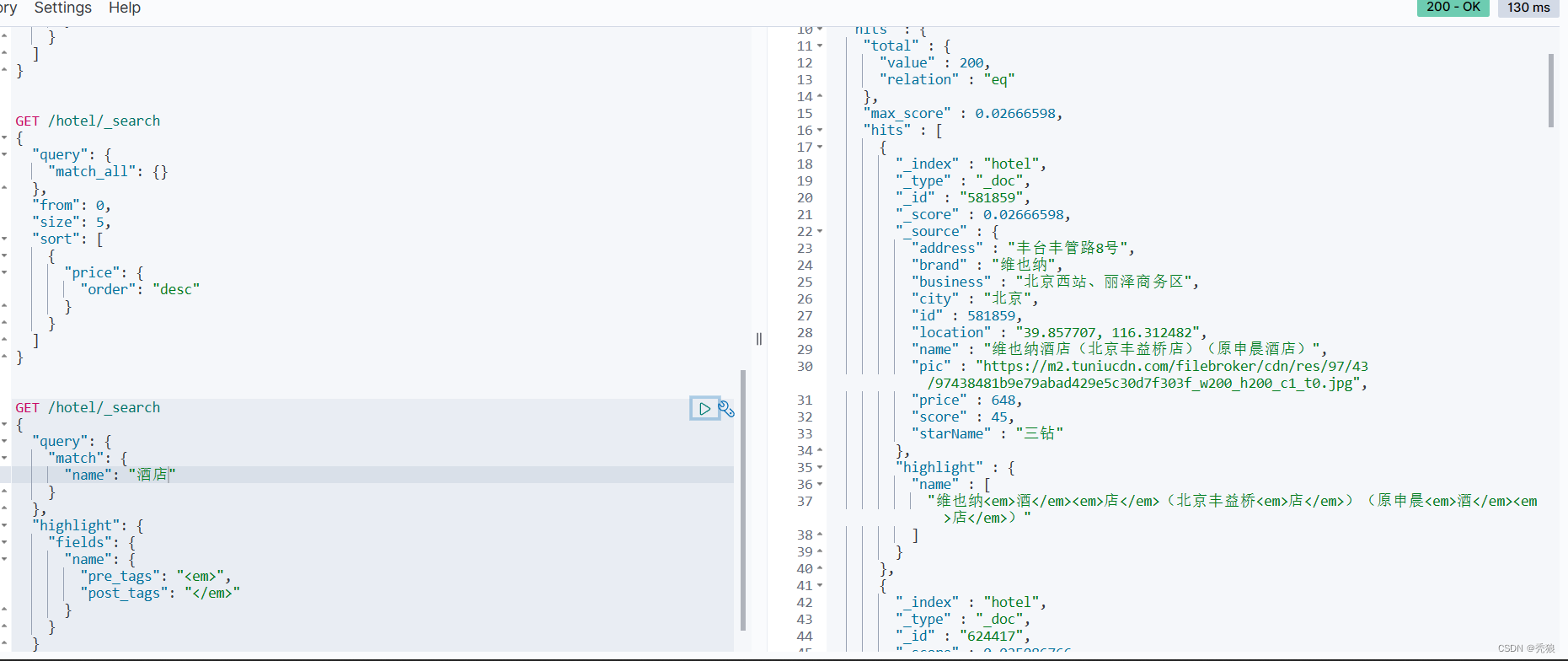
-
高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
-
默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
-
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false(就是在每个字段中有关键词就会高亮)
RestClient
操作索引表
导入对应的依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>因为springboot默认会设置elasticsearch的版本,所以为了保证版本统一,我们要手动是设置其版本。
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>进行索引表的CRUD
初始化 RestHighLevelClient
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.BeforeEach;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class HotelDemoApplicationTests {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
//会在执行@Test前执行
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://139.9.214.176:9200")
));
}
}
新增操作
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class HotelDemoApplicationTests {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
//会在执行@Test前执行
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://139.9.214.176:9200")
));
}
@Test
void test1() throws IOException {
//创建request对象,设置索引库的名字
CreateIndexRequest createIndexRequest = new CreateIndexRequest("hotel");
//创建DSL语句
String index_mapping = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"address\": {\n" +
" \"type\": \"keyword\"\n" +
" , \"index\": false \n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"city\": {\n" +
" \"type\": \"text\"\n" +
" },\n" +
" \"star_name\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"business\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"longitude\": {\n" +
" \"type\": \"geo_point\",\n" +
" \"index\": false\n" +
" },\n" +
" \"pic\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
//设置请求体的源,设置为JSON格式
createIndexRequest.source(index_mapping, XContentType.JSON);
//发送请求
client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
}
}
测试结果为为下:
删除操作
@Test
void deleteTest() throws IOException {
//创建request,设置索引库的名字
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("hotel");
//发送请求
client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
}效果图为下:
查询索引库是否存在
@Test
void isExitTest() throws IOException {
//创建request
GetIndexRequest getIndexRequest = new GetIndexRequest("hotel");
//发送请求
boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println("索引库是否存在:" + exists);
}测试效果为下:

索引库操作的基本步骤:
-
初始化RestHighLevelClient
-
创建XxxIndexRequest。XXX是Create、Get、Delete
-
准备DSL( Create时需要,其它是无参)
-
发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
文档的CURD操作
新增操作
新增步骤:
-
1)根据id查询酒店数据Hotel(例子)
-
2)将Hotel封装为HotelDoc
-
3)将HotelDoc序列化为JSON
-
4)创建IndexRequest,指定索引库名和id
-
5)准备请求参数,也就是JSON文档
-
6)发送请求
代码格式为下:
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class HotelDemoApplicationTests {
@Autowired
IHotelService iHotelService;
private RestHighLevelClient client;
@BeforeEach
void setUp() {
//会在执行@Test前执行
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://139.9.214.176:9200")
));
}
@Test
public void test01() throws IOException {
//创建request对象
IndexRequest indexRequest = new IndexRequest("hotel").id("36934");
//从数据库中查询对应id的数据,创建JSON数据
Hotel hotel = iHotelService.getById("36934");
//将得到的数据进行封装
HotelDoc hotelDoc = new HotelDoc(hotel);
String data = JSON.toJSONString(hotelDoc);
indexRequest.source(data, XContentType.JSON);
client.index(indexRequest, RequestOptions.DEFAULT);
}
}
效果为下:
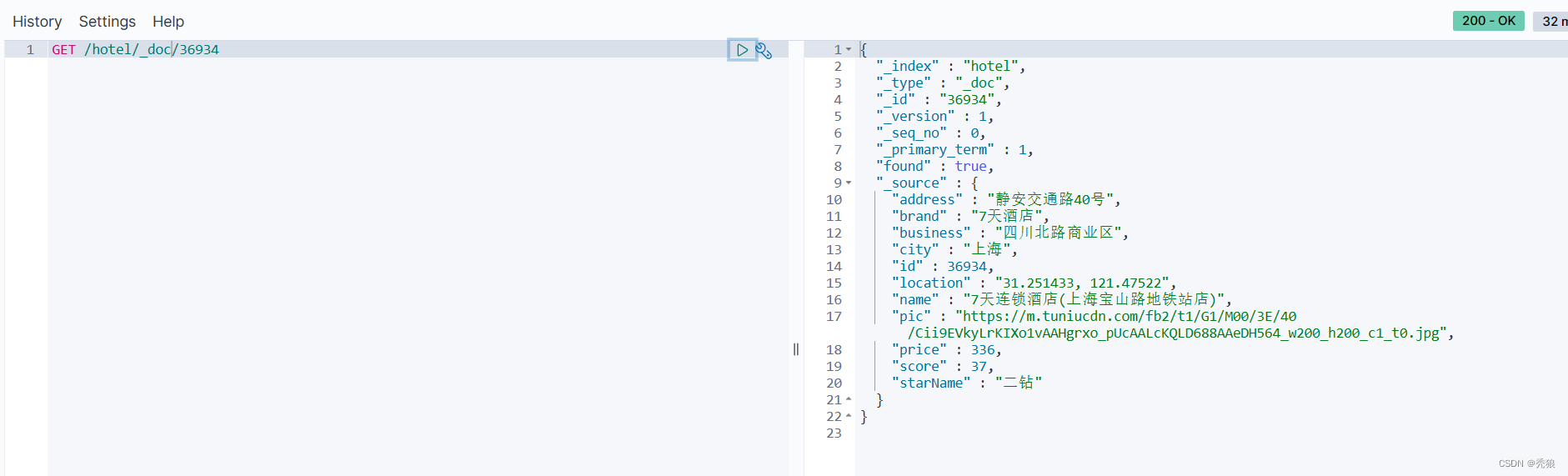
查询操作
查询步骤:
-
1)准备Request对象。这次是查询,所以是GetRequest
-
2)发送请求,得到结果。因为是查询,这里调用client.get()方法
-
3)解析结果,就是对JSON做反序列化
格式代码为下:
@Test
public void getTest() throws IOException {
//创建request
GetRequest getRequest = new GetRequest("hotel").id("36934");
//发送请求
GetResponse response = client.get(getRequest, RequestOptions.DEFAULT);
String sourceAsString = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}效果图为下:

删除操作
删除步骤:
-
1)准备Request对象,因为是删除,这次是DeleteRequest对象。要指定索引库名和id
-
2)准备参数,无参
-
3)发送请求。因为是删除,所以是client.delete()方法
格式代码为下:
@Test
public void deleteTest() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("hotel").id("36934");
client.delete(deleteRequest, RequestOptions.DEFAULT);
}效果图为下:

修改操作
修改有两种方式:
-
全量修改:本质是先根据id删除,再新增(先删除再进行增加)
-
增量修改:修改文档中的指定字段值
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
-
如果新增时,ID已经存在,则修改
-
如果新增时,ID不存在,则新增
格式代码为下:
@Test
public void updateTest() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("hotel", "36934");
//设置要改变的键值对
updateRequest.doc(
"price", "1",
"starName", "四钻"
);
client.update(updateRequest, RequestOptions.DEFAULT);
}效果图为下:

批量导入文档
格式代码为下:
@Test
public void add2List() throws IOException {
//创建Bulk请求
BulkRequest bulkRequest = new BulkRequest();
//再Bulk中添加对应的数据信息
List<Hotel> list = iHotelService.list();
list.forEach(hotel -> {
HotelDoc hotelDoc = new HotelDoc(hotel);
bulkRequest.add(new IndexRequest("hotel")
.id(String.valueOf(hotel.getId()))
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
});
client.bulk(bulkRequest, RequestOptions.DEFAULT);
}
效果图为下:
进行文档的CRUD
-
1)准备Request对象
-
2)准备请求参数
-
3)发起请求
-
4)解析响应
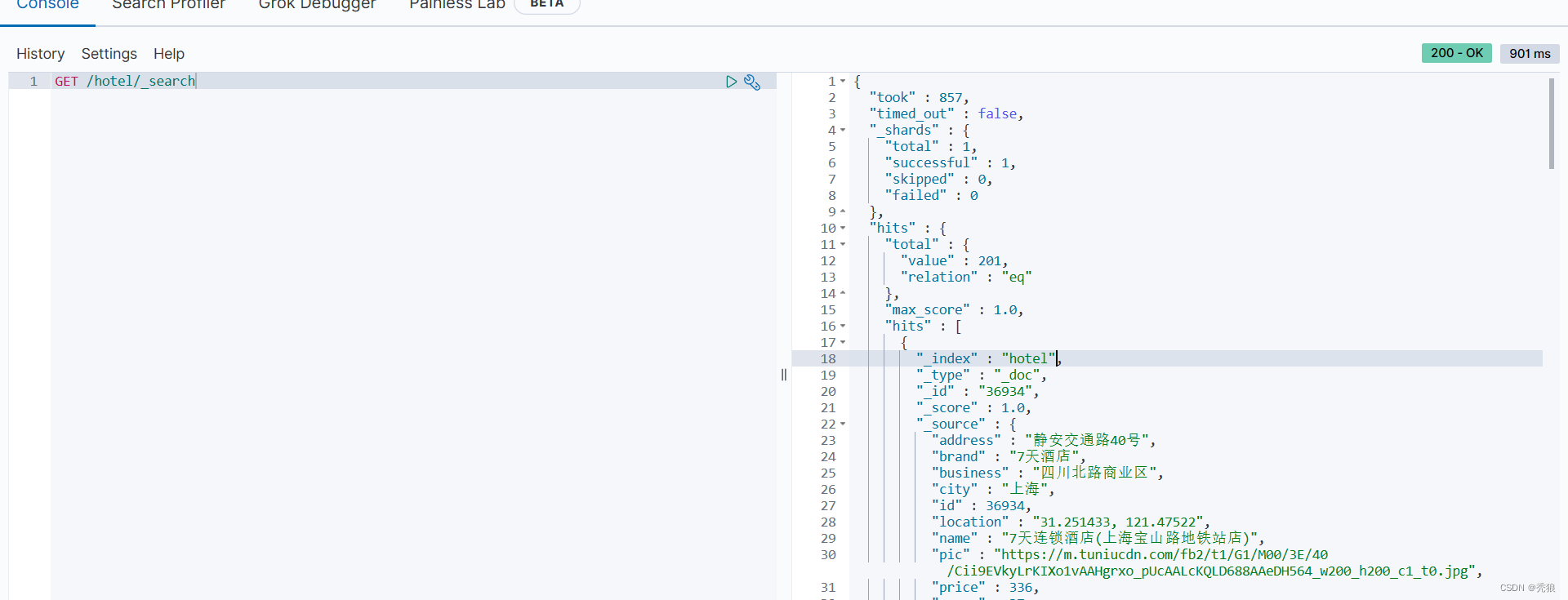
match_all查询
@Test
public void selectMatchAll() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL
request.source().query(QueryBuilders.matchAllQuery());
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i]);
}
}
效果图为下:

match查询
@Test
public void selectMatch() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL
request.source().query(QueryBuilders.matchQuery("name", "速8"));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i]);
}
}效果图为下:
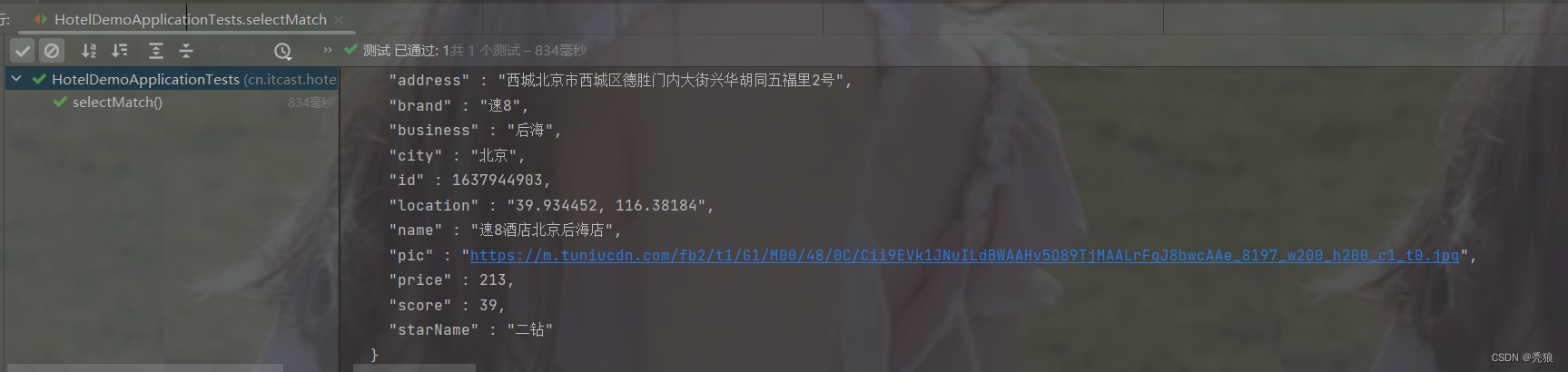
multi_match_query查询
@Test
public void selectMultiMatch() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL, 设置多个匹配字段
request.source().query(QueryBuilders.multiMatchQuery("速8", "name", "brand"));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i]);
}
}格式代码为下:
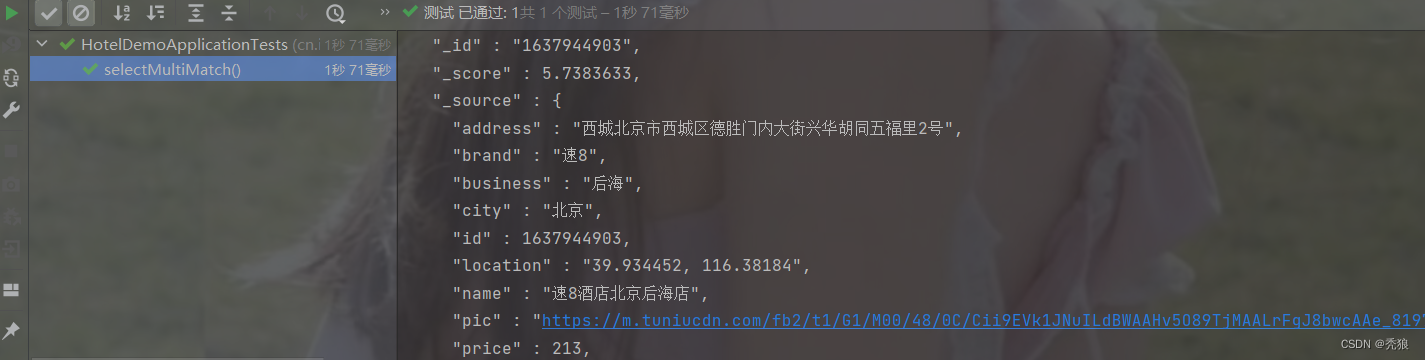
range查询
@Test
public void selectMultiMatch() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL, 设置多个匹配字段
request.source().query(QueryBuilders.multiMatchQuery("速8", "name", "brand"));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i]);
}
}效果图为下:
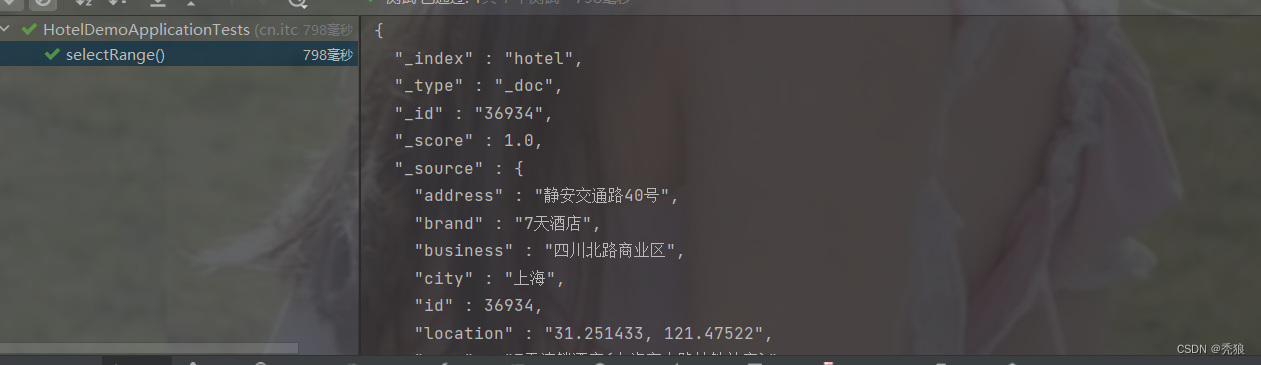
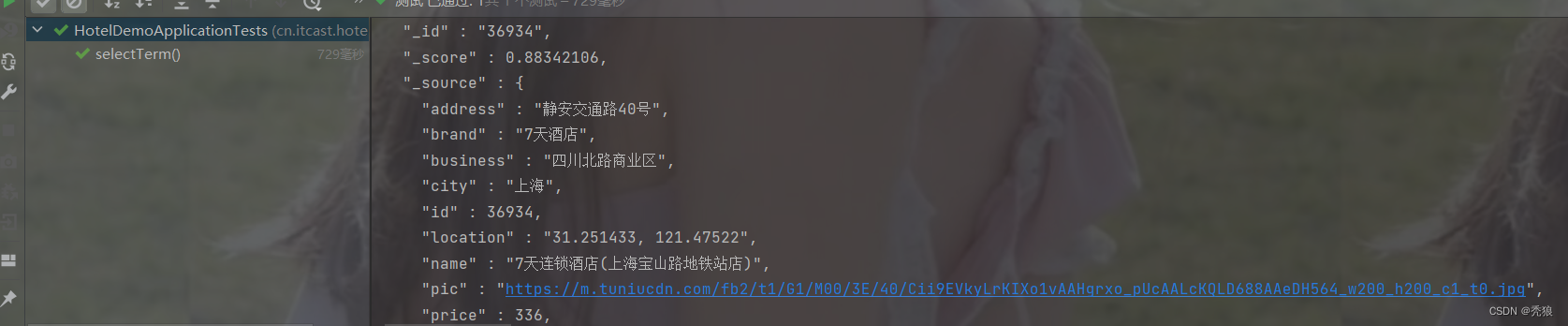
term精准匹配查询
@Test
public void selectTerm() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL, 设置多个匹配字段
request.source().query(QueryBuilders.termQuery("city.keyword", "上海"));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i]);
}
}效果图为下:
布尔查询
@Test
public void selectBool() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL, 设置多个匹配字段
request.source()
.query(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("city.keyword", "上海"))
.should(QueryBuilders.termQuery("brand.keyword", "凯悦"))
.mustNot(QueryBuilders.rangeQuery("price").gte(2000))
.filter(QueryBuilders.rangeQuery("score").gt(45)));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i]);
}
}效果图为下:

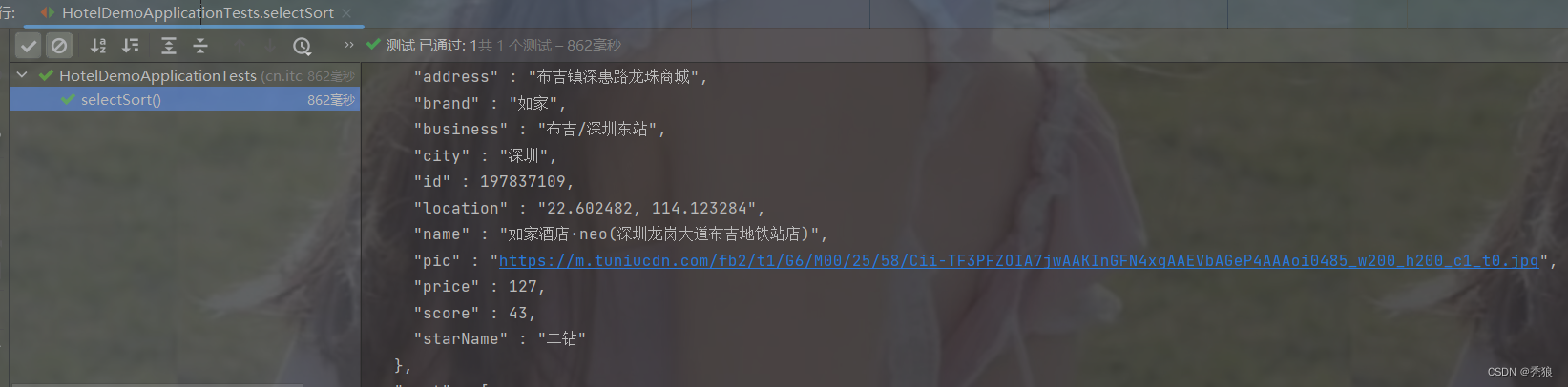
排序查询
@Test
public void selectSort() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL, 设置多个匹配字段
request.source().query(QueryBuilders.matchAllQuery()).sort("price", SortOrder.ASC);
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i]);
}
}效果图为下:
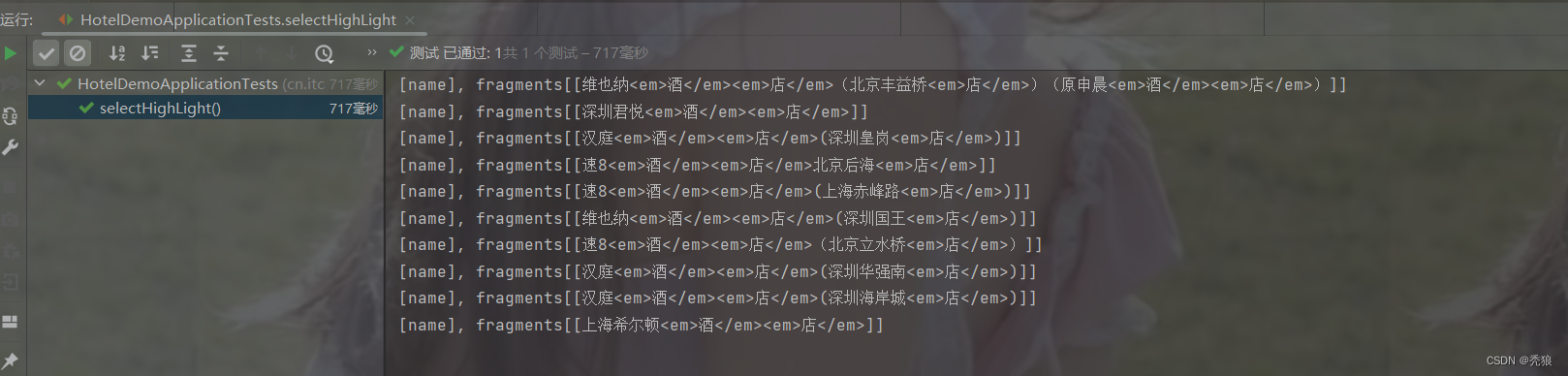
高亮查询
@Test
public void selectHighLight() throws IOException {
//编写查询请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL, 设置多个匹配字段
request.source().query(QueryBuilders.matchQuery("name", "酒店")).highlighter(new HighlightBuilder().field("name").requireFieldMatch(false).preTags("<em>").postTags("</em>"));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
SearchHit[] hits = response.getHits().getHits();
for (int i = 0; i < hits.length; i++) {
System.out.println(hits[i].getHighlightFields().get("name"));
}
}效果图为下:
数据聚合
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
-
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同时求max、min、avg、sum等
-
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
桶(Bucket)聚合
DSL写法
#bucket聚合
#size等于0就说明只需要聚合的结果
#按照对应的文档格数类进行升序
#field中设置聚合的字段
#query中可以设置查询信息,如果没有就不需要写query
GET /hotel/_search
{
"query": {},
"size": 0,
"aggs": {
"聚合的名":{
"terms": {
"field": "",
"size": 10,
"order": {
"_count": "asc"
}
}
}
}
}效果图为下:
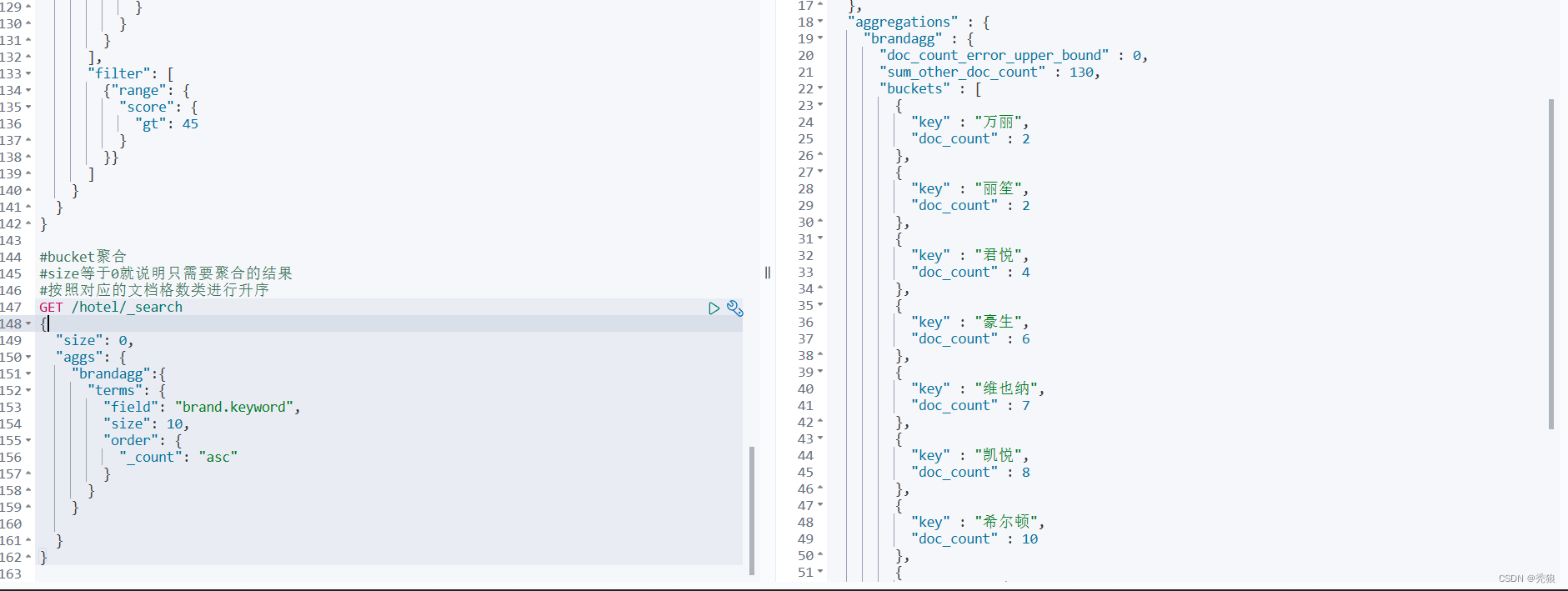
使用restClient实现代码为下:
@Test
public void bucketTest() throws IOException {
//编写请求
SearchRequest request = new SearchRequest("hotel");
//通过API编写DSL
request.source().size(0)
.aggregation(AggregationBuilders.terms("brand_agg")
.field("brand.keyword")
.size(10));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
Aggregations aggregations = response.getAggregations();
Terms terms = aggregations.get("brand_agg");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
buckets.forEach(bucket -> System.out.println(bucket.getKeyAsString()));
}效果图为下:
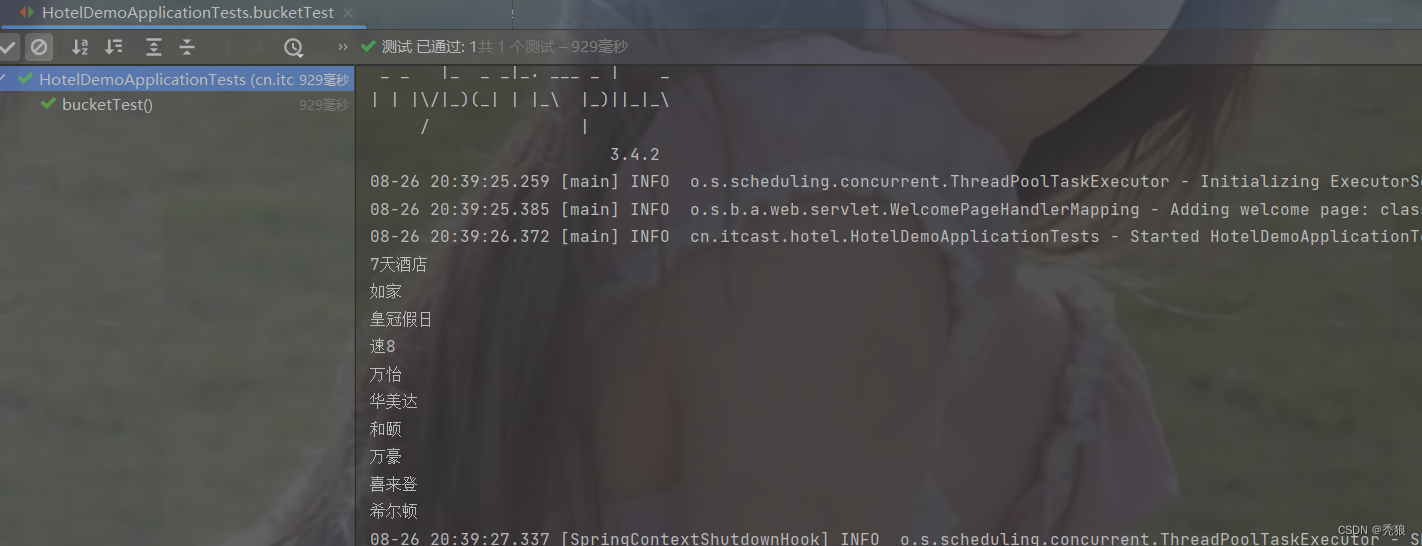
度量(Metric)聚合
DSL写法:
#metric聚合
#query就是查询的条件,如果没有条件,就不需要写query
#score_stats就是metric的聚合名字
#stats就是表示聚合类型,stats会查出 min, max, avg
#在stats中的filed就是metric的条件字段
#size等于0就说明只需要聚合的结果
GET /hotel/_search
{
"query": {},
"size": 0,
"aggs": {
"聚合名": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "asc"
}
}
, "aggs": {
"score_stats":{
"stats": {
"field": "score"
}
}
}
}
}
}
效果图为下:
自动补全
安装拼音分词器
pinyin分词器的下载地址:pinyin分词器
1.通过宝塔面板将对应的压缩包上传到服务器上,将内容解压到新创建的/pinyin文件夹中。
#在容器中进行离线安装
#通过copy将/pinyin文件复制到elasticsearch容器中
docker cp pinyin 对应的容器id:/usr/share/elasticsearch/plugins/
#重启对应的容器
docker restart 容器id
进行DSL测试

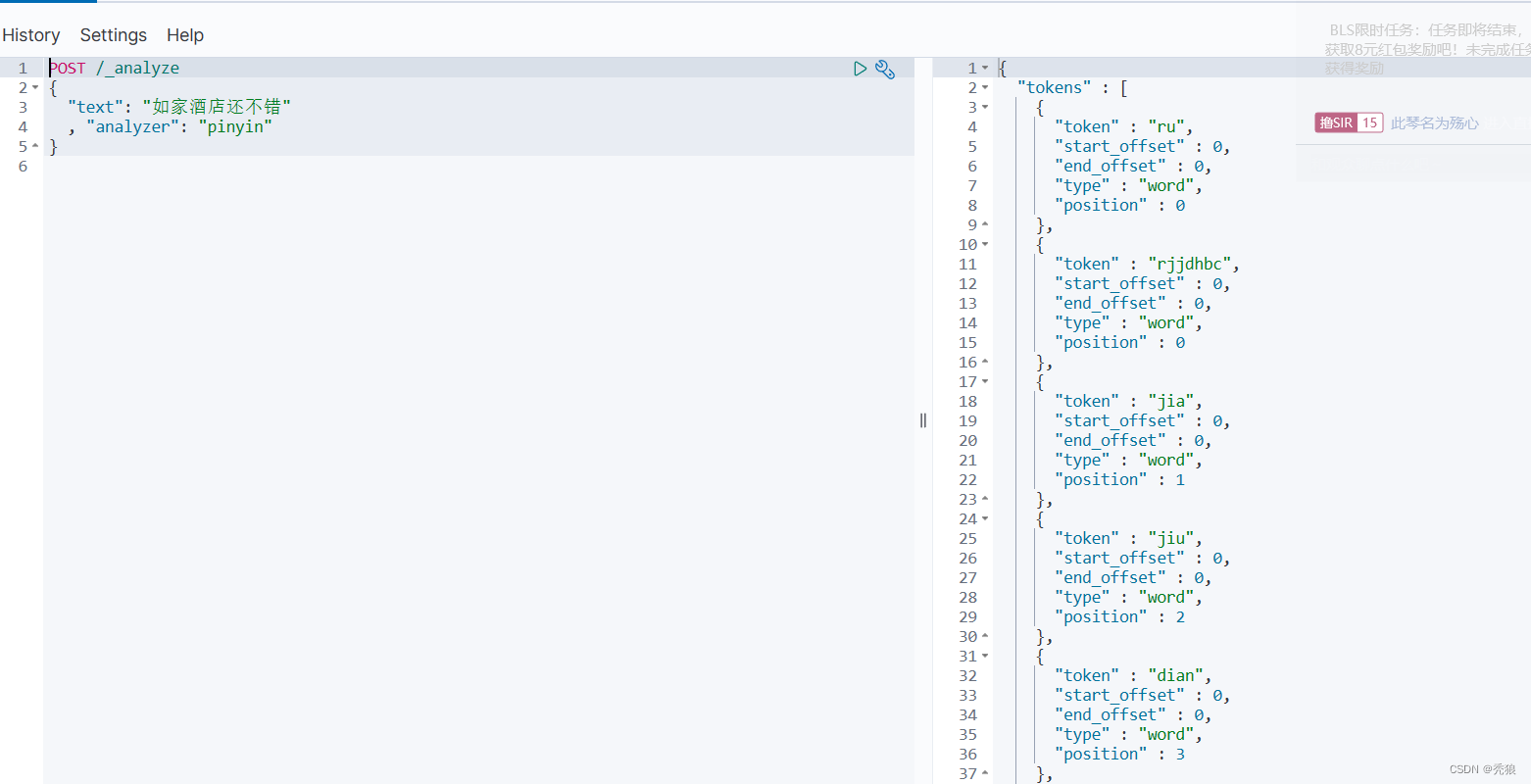
自定义分词器
elasticsearch中分词器(analyzer)的组成包含三部分:
-
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
-
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
-
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等

自定义分词器的DSL为下:
#my_analyzer表示分词器组
# "tokenizer": "ik_max_word",详细分词
#filter就是创建的过滤器
#keep_full_pinyin将每个字分词成拼音
#keep_joined_full_pinyin拼音组合
#
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}测试例子为下:
#插入数据1
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
#插入数据2
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
#匹配字段
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}测试结果为下:
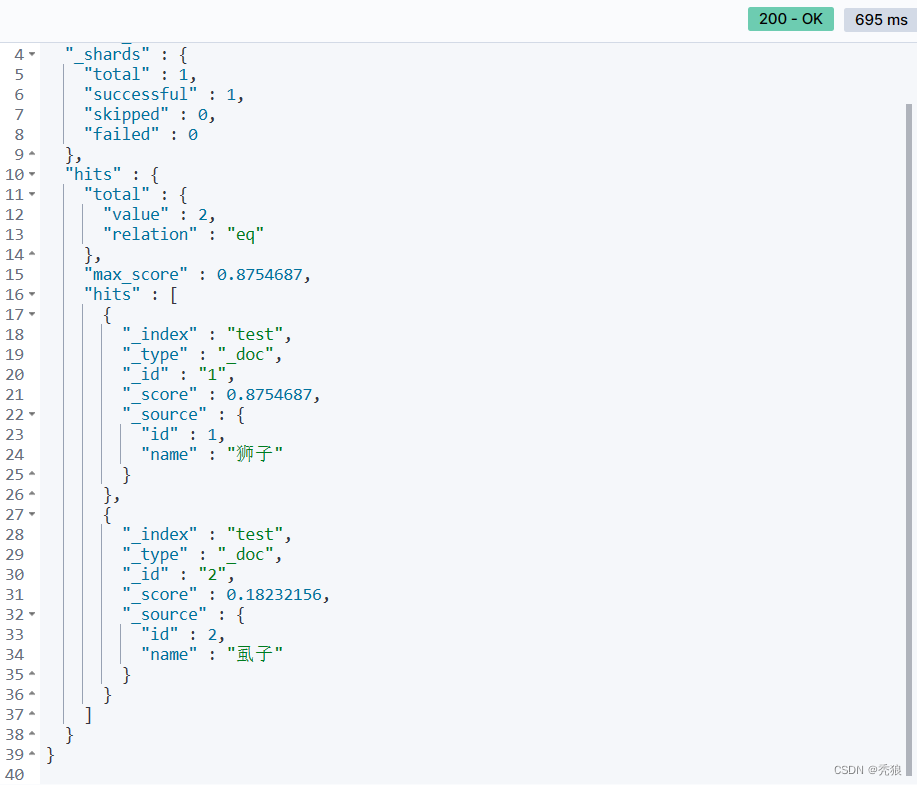
我们会发现主要拼音相同的数据都会被输出。
#设置不通过拼音匹配所有符合的数据
#在mappings中设置搜索时的解析方式为: ik_smart,搜索时不要使用拼音分词器,所以使用ik_smart
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}进行测试:

结果就不会通过拼音匹配使用的数据。
如何使用拼音分词器?
-
①下载pinyin分词器
-
②解压并放到elasticsearch的plugin目录
-
③重启即可
如何自定义分词器?
-
①创建索引库时,在settings中配置,可以包含三部分
-
②character filter
-
③tokenizer
-
④filter
拼音分词器注意事项?
-
为了避免搜索到同音字,搜索时不要使用拼音分词器
自动补全查询
-
参与补全查询的字段必须是completion类型。
-
字段的内容一般是用来补全的多个词条形成的数组。
测试例子
创建索引库:
# 自动补全的索引库
PUT test
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}插入数据:
# 示例数据
POST test/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test/_doc
{
"title": ["Nintendo", "switch"]
}
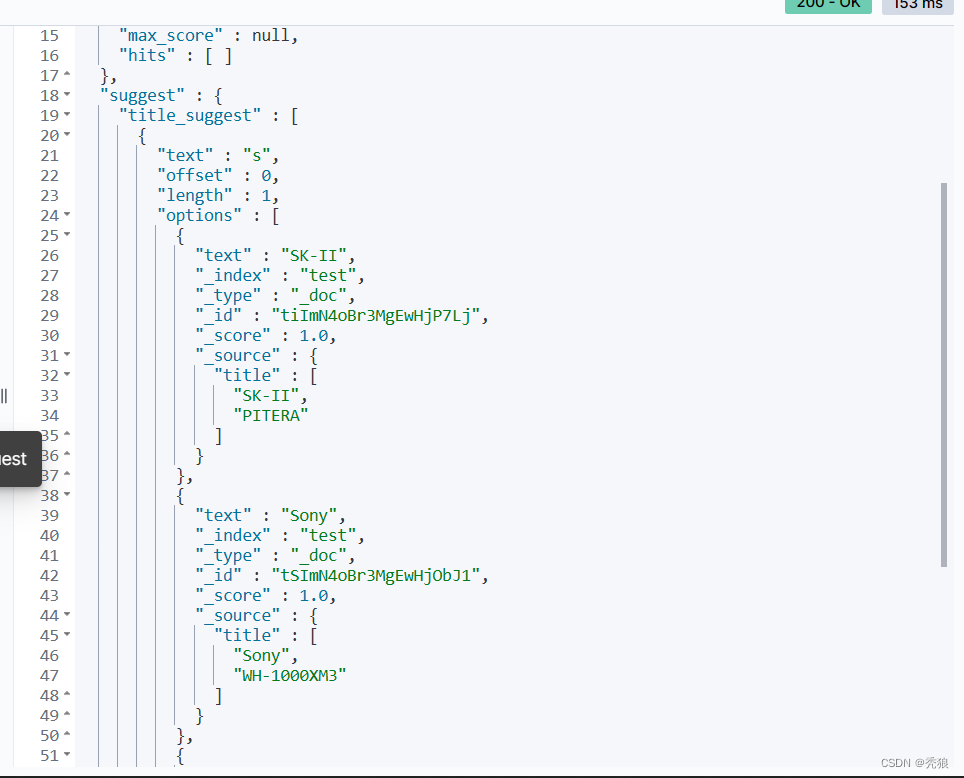
进行自动补全查询:
# 自动补全查询
# s表示关键字,也就是我们输入的关键字
#field中就是表示要补全的字段
#skip_duplicates跳过重复的
#size表示查询的条数
POST /test/_search
{
"suggest": {
"title_suggest": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}测试结果为下:
通过RestClient实现自动补全
格式代码为下:
@Test
public void autoComplete() throws IOException {
//创建请求
SearchRequest request = new SearchRequest("test");
//通过API编写DSL
request.source().suggest(new SuggestBuilder().addSuggestion("title_suggest",
SuggestBuilders.completionSuggestion("title")
.prefix("s")
.skipDuplicates(true)
.size(10)));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//对结果进行解析
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestion = suggest.getSuggestion("title_suggest");
List<CompletionSuggestion.Entry.Option> options = suggestion.getOptions();
options.forEach(item -> System.out.println(item.getText()));
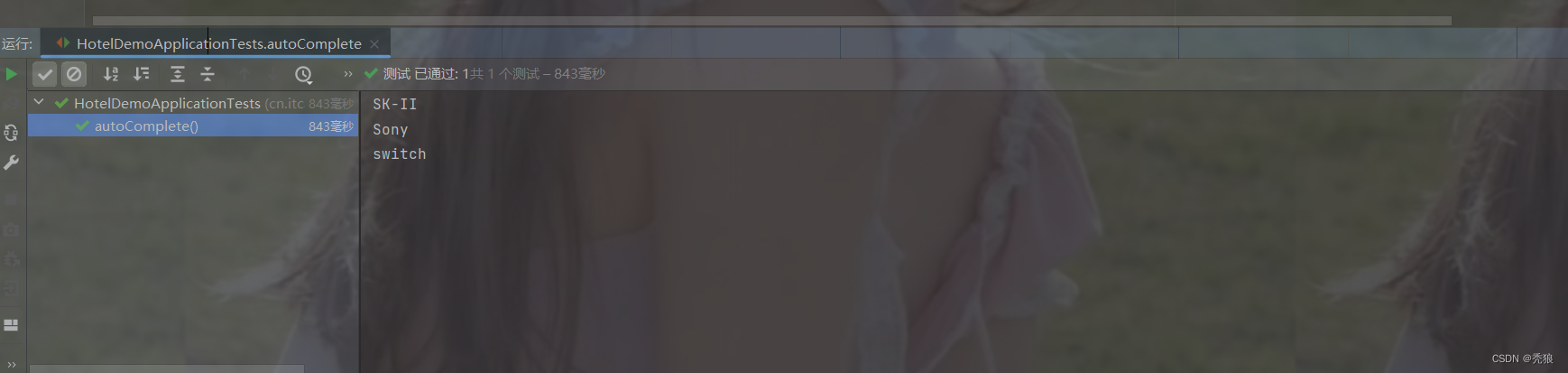
}效果图为下:
数据同步
当我们的数据库发生增删改的时候,es并不会获得到新的数据,需要我们进行同步,所以我们需要完成数据同步。
通过mq实现异步通知例子
mysql增删改模块的编写
1. 创建队列, 交换机, 绑定二者关系。
设置rabbitmq的配置和引入对应的依赖
spring:
rabbitmq:
host: 119.9.212.171 # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: guest # 用户名
password: guest # 密码新建配置类
import cn.itcast.hotel.Constant.MQConstant;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MQConfig {
//创建新增和修改的消息队列(因为es中的修改和新增的代码时相同的,所以直接发送同种类型的消息即可)
@Bean
public Queue insertOrUpdateQueue() {
return new Queue(MQConstant.HOTEL_INSERT_QUEUE, true);
}
//创建删除的消息队列
@Bean
public Queue deleteQueue() {
return new Queue(MQConstant.HOTEL_DELETE_QUEUE, true);
}
//创建交换机
@Bean
public TopicExchange getExchange() {
return new TopicExchange(MQConstant.HOTEL_EXCHANGE, true,false);
}
//将新增和修改的消息队列和交换机进行绑定
@Bean
public Binding insertOrUpdateQueueBinding() {
return BindingBuilder.bind(insertOrUpdateQueue()).to(getExchange()).with(MQConstant.HOTEL_INSERT_KEY);
}
//将删除的队列和交换机进行绑定
@Bean
public Binding deleteQueueBinding() {
return BindingBuilder.bind(deleteQueue()).to(getExchange()).with(MQConstant.HOTEL_DELETE_KEY);
}
}
2. 向对应的消息队列中发送消息。在controller层中发送消息)
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
//发送消息
rabbitTemplate.convertAndSend(MQConstant.HOTEL_INSERT_QUEUE, MQConstant.HOTEL_INSERT_KEY, hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MQConstant.HOTEL_DELETE_QUEUE, MQConstant.HOTEL_DELETE_KEY, id);
}2.在消费端中,也就是es模块中配置消费者,进行接收消息,并处理信息,更新索引库中的数据。
创建配置类配置RestClient的信息
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
@Component
public class EsConfig {
@Bean
public RestHighLevelClient getRestHighLevelClient() {
return new RestHighLevelClient(RestClient.builder(HttpHost.create("http://139.9.214.176:9200")));
}
}
创建配置类配置消息监听者的信息
import cn.itcast.hotel.Constant.MQConstant;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.impl.HotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
@Configuration
public class MQConfig {
@Autowired
RestHighLevelClient restHighLevelClient;
@Autowired
HotelService hotelService;
//创建insertOrUpdateQueue的监听器
@RabbitListener(queues = MQConstant.HOTEL_INSERT_QUEUE)
public void getInsertOrUpdateMessage(String message) {
//这里就先不考虑数据库查询非空的问题,也就是修改操作
System.out.println("id:" + message);
//通过id从数据库中查询对应的新的信息
QueryWrapper<Hotel> wrapper = new QueryWrapper<>();
wrapper.eq("id", Integer.parseInt(message));
Hotel hotel = hotelService.getOne(wrapper);
//将该信息封装成对象,通过DSL修改当前的索引库
HotelDoc hotelDoc = new HotelDoc(hotel);
//创建对应的请求
IndexRequest request = new IndexRequest("hotel").id(String.valueOf(hotelDoc.getId()));
//通过API编写DSL
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//发送请求
try {
restHighLevelClient.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//创建deleteQueue的监听器
@RabbitListener(queues = MQConstant.HOTEL_DELETE_QUEUE)
public void getDeleteMessage(String message) {
System.out.println("id:" + message);
//创建请求
DeleteRequest request = new DeleteRequest("hotel").id(message);
//发送请求
try {
restHighLevelClient.delete(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
最终完成例子, 完成数据同步。















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









