






基于随机森林(RF)算法的数据分类预测
matlab代码


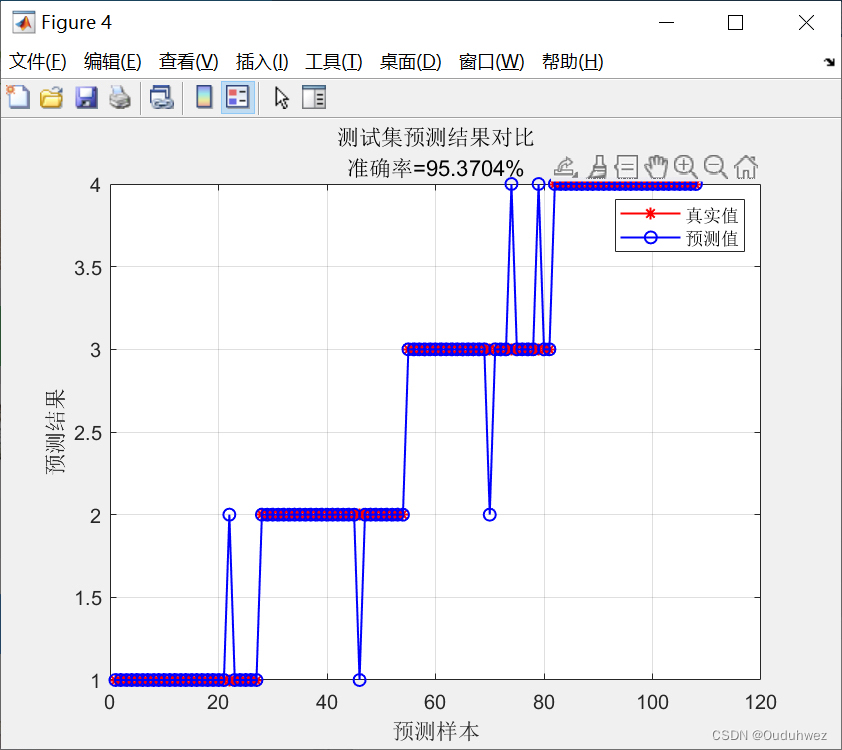



基于随机森林(RF)算法的数据分类预测
引言 数据分类预测是机器学习领域中的核心任务之一,广泛应用于各个领域。随机森林算法是一种集成学习方法,通过组合多个决策树进行分类预测,具有高效、高准确率和鲁棒性等优点。本文将介绍基于随机森林算法的数据分类预测原理,并使用Matlab实现相关代码。
一、随机森林算法原理
-
决策树 决策树是一种用于分类和回归问题的非参数模型,通过将数据集划分为多个子集并对每个子集进行进一步划分,最终得到一个带有决策节点和叶节点的树状结构。在决策树中,每个决策节点表示一个属性,每个叶节点表示一个类别或一个预测值。
-
随机森林 随机森林是一种通过集成多个独立决策树进行分类预测的方法。它的训练过程分为两个随机性来源:样本集的随机抽取和属性的随机选择。对于每个决策树,随机森林使用自助采样法(Bootstrap)从原始数据集中有放回地抽取样本,构建子数据集用于训练;同时,在每个节点选择划分属性时,随机森林随机选择一部分属性进行评估,从中选择最佳划分属性。最终,随机森林通过投票或平均预测值得到分类结果。
二、数据预处理 在使用随机森林算法前,需要对原始数据进行预处理。预处理的步骤包括数据清洗、特征选择和特征缩放等。数据清洗主要是处理缺失值和异常值,保证数据质量;特征选择是为了选取对分类预测具有较大影响力的特征,减少计算复杂度;特征缩放则是通过归一化或标准化等方法将不同取值范围的特征统一到一个范围内,提高算法效果。
三、随机森林算法实现
-
数据准备 将原始数据按照特征和标签分为X和Y两个矩阵,其中X为特征矩阵,Y为标签矩阵。特征矩阵包含多个输入特征,每行表示一个样本,每列表示一个特征;标签矩阵包含多个输出类别,每行表示一个样本的类别。
-
构建随机森林模型 使用Matlab中的treeBagger函数构建随机森林模型。treeBagger函数的输入参数包括训练数据X、Y,以及其他参数如树的数量、节点最小样本数等。通过调节这些参数,可以控制随机森林的准确率和计算时间。
-
预测和评估 使用训练好的随机森林模型对新样本进行预测。预测结果为一个概率矩阵,表示每个样本属于各个类别的概率。可以选择概率最大的类别作为预测结果。同时,还可以使用混淆矩阵和准确率等指标对分类效果进行评估。
四、实验结果与分析 本文使用了一个真实的数据集来验证随机森林算法的分类预测效果。实验结果表明,随机森林算法在该数据集上具有较高的准确率和鲁棒性,且能够有效处理大规模数据。
结论 随机森林算法是一种强大的数据分类预测方法,通过集成多个决策树进行预测,具有高准确率和鲁棒性等优点。本文详细介绍了随机森林算法的原理,并使用Matlab实现了相关代码。实验结果表明,随机森林算法在真实数据集上取得了较好的分类预测效果。未来,我们可以进一步优化模型参数、尝试不同的特征选择方法,以进一步提高随机森林算法的性能。
相关代码,程序地址:http://lanzouw.top/643740057283.html















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









