







前沿、本人学习使用,如有侵权私信联系删除
一、kaggle介绍
Kaggle是一个数据科学和机器学习竞赛平台,旨在提供数据集、工具和社区支持,让数据科学家、机器学习工程师和其他相关领域的人员能够分享、合作和竞赛。它提供了各种竞赛任务,参与者可以通过解决这些任务来提升他们的数据分析和建模技能。
二、kaggle初步学习使用
Titanic Tutorial | Kaggle-泰坦尼克号教程
如果你是小白,对kaggle并未有所解,你可以选择根据该教程学习
该内容是在-Titanic Tutorial | Kaggle泰坦尼克号教程 的解释说明
1、任务要求:
简单概括就是:谁活谁死
希望使用泰坦尼克号乘客数据(姓名、年龄、票价等)来尝试预测谁会活下来,谁会死。
2、查看比赛数据:
请单击比赛页面顶部的“数据”选项卡。然后,向下滚动以查找文件列表。
There are three files in the data: (1) train.csv, (2) test.csv, and (3) gender_submission.csv.
数据中有三个文件:(1) train.csv、(2) test.csv 和 (3) gender_submission.csv。
train.csv包含机上乘客子集的详细信息(确切地说是 891 名乘客——每个乘客在表中都有不同的行)。要调查此数据,请单击屏幕左侧的文件名。完成此操作后,您可以在窗口中查看所有数据。
第二列中的值(“幸存”)可用于确定每位乘客是否幸存:
- if it's a "1", the passenger survived.
如果是“1”,则乘客幸免于难。 - if it's a "0", the passenger died.
如果是“0”,则乘客死亡。
例如,train.csv中列出的第一位乘客是欧文·哈里斯·布劳恩德先生。他在泰坦尼克号上去世时年仅 22 岁。
单击test.csv(在屏幕左侧)以检查其内容。请注意,test.csv没有“幸存”列 - 这些信息对您是隐藏的,您在预测这些隐藏值方面的表现将决定您在比赛中的得分!
3、gender_submission.csv
gender_submission.csv 文件作为示例提供,演示应如何构建预测。它预测所有女乘客都活了下来,所有男乘客都死了。您关于生存的假设可能会有所不同,这将导致不同的提交文件。但是,就像这个文件一样,你的提交应该有:
- “PassengerId”列,其中包含test.csv每位乘客的 ID。
- “幸存”列(您将创建!),其中“1”表示您认为乘客幸存下来的行,“0”表示您预测乘客死亡。
三、创建笔记本
1、编码环境
在本部分中,将训练自己的机器学习模型来改进预测。
2、创建The Notebook
首先要做的是创建一个 Kaggle Notebook,您将在其中存储所有代码。这部分不需要安装下载环境。
点击比赛页面上的“代码”选项卡。然后,单击“新建笔记本”。
1.步骤一
 2.步骤二
2.步骤二
3.步骤三
 4.步骤四,在这个地方就可以根据自己的需求,一步步进行便携了
4.步骤四,在这个地方就可以根据自己的需求,一步步进行便携了
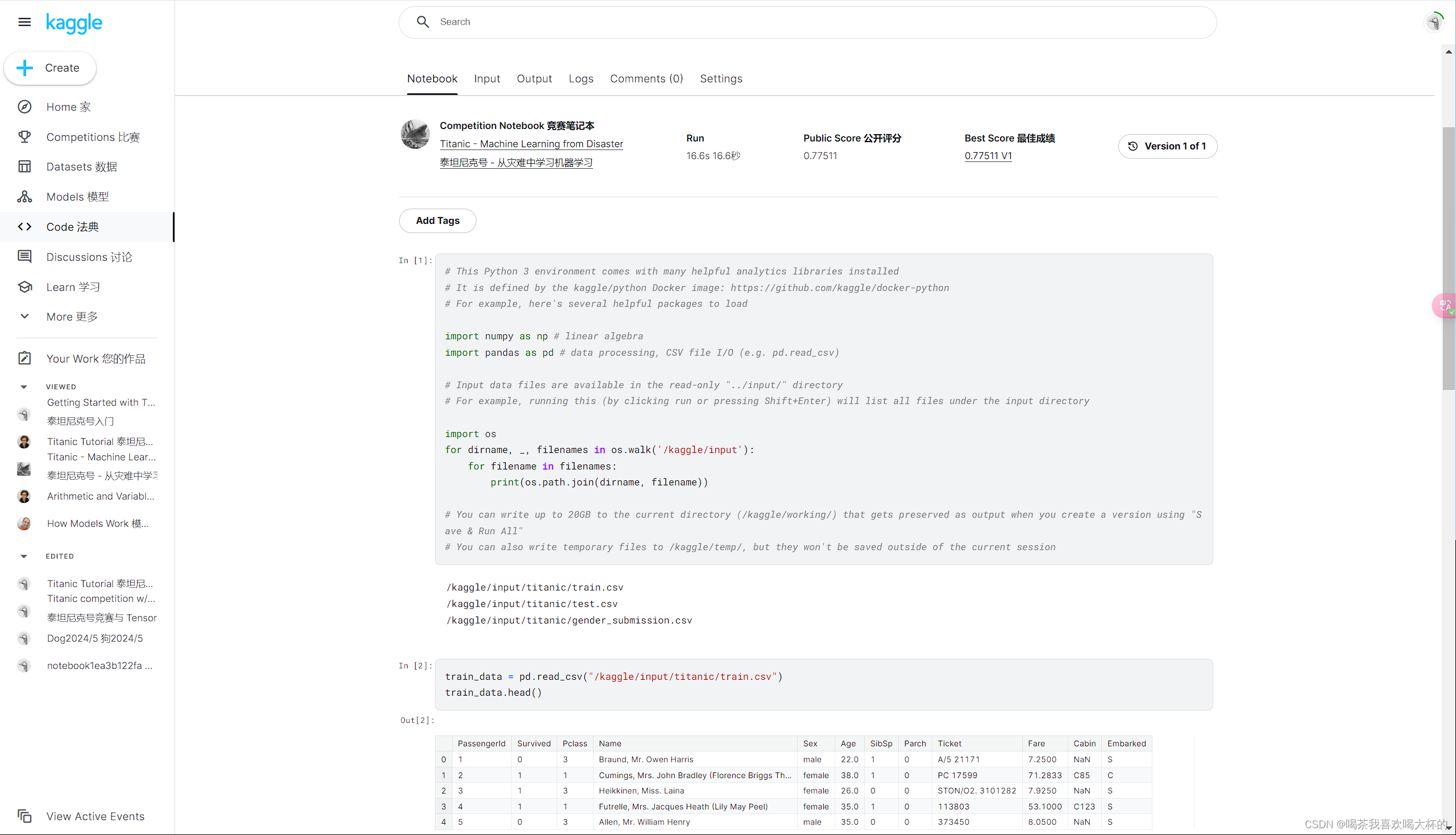
第一个代码单元格中已经包含了一些代码。若要运行此代码,请将光标放在代码单元格中。(如果您的光标位于正确的位置,您会注意到灰色框左侧有一条蓝色垂直线。然后,点击播放按钮(显示在蓝线左侧),或点击键盘上的 [Shift] + [Enter]。
如果代码成功运行,则返回三行输出。下面,您可以看到刚刚运行的相同代码,以及应在笔记本中看到的输出。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csv
这向我们显示了比赛数据的存储位置,以便我们可以将文件加载到笔记本中。接下来我们将这样做。
3、 加载数据
笔记本中的第二个代码单元格现在显示在包含文件位置的三行输出下方。
将下面的两行代码键入到第二个代码单元格中。然后,完成后,单击蓝色播放按钮,或按[Shift] + [Enter]。
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris 布劳恩德,欧文·哈里斯先生 | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... 卡明斯,约翰·布拉德利夫人(弗洛伦斯·布里格斯... | female | 38.0 | 1 | 0 | PC 17599 个人电脑 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina Heikkinen,莱娜小姐 | female | 26.0 | 0 | 0 | STON/O2. 3101282 STON/O2.3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) Futrelle,雅克·希思夫人(莉莉·梅·皮尔) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry 艾伦,威廉·亨利先生 | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
If you're not already familiar with Python (and pandas), the code shouldn't make sense to you -- but don't worry! The point of this tutorial is to (quickly!) make your first submission to the competition. At the end of the tutorial, we suggest resources to continue your learning.
如果你还不熟悉 Python(和 pandas),那么代码对你来说应该没有意义——但别担心!本教程的重点是(快速!)向比赛提交您的第一次参赛作品。在本教程结束时,我们建议提供资源以继续学习。
At this point, you should have at least three code cells in your notebook.
此时,笔记本中应至少有三个代码单元格。
将下面的代码复制到笔记本的第三个代码单元格中,以加载test.csv文件的内容。
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | Kelly, Mr. James 凯利,詹姆斯先生 | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | 3 | Wilkes, Mrs. James (Ellen Needs) 威尔克斯,詹姆斯夫人(艾伦需要) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | 2 | Myles, Mr. Thomas Francis 迈尔斯,托马斯·弗朗西斯先生 | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | 3 | Wirz, Mr. Albert Wirz, Albert 先生 | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) Hirvonen,亚历山大夫人(Helga e Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
成功运行所有代码后,所有数据(train.csv 和 test.csv)都将加载到笔记本中。(上面的代码只显示了每个表的前 5 行,但所有数据都在那里——所有 891 行train.csv和所有 418 行test.csv!
四、第一次提交
当有如此多的数据需要整理时,寻找模式最初可能会让人感到不知所措。所以,我们将从简单开始。
1、 探索模式
请记住,gender_submission.csv 中的示例提交文件假定所有女性乘客都幸存下来(并且所有男性乘客都已死亡)。
Is this a reasonable first guess? We'll check if this pattern holds true in the data (in train.csv).
这是一个合理的第一个猜测吗?我们将检查此模式在数据中是否成立(train.csv)。
women = train_data.loc[train_data.Sex == 'female']["Survived"]
rate_women = sum(women)/len(women)
print("% of women who survived:", rate_women)
% of women who survived: 0.7420382165605095
在继续之前,请确保代码返回上述输出。上面的代码计算了幸存的女性乘客(train.csv)的百分比。
然后,在另一个代码单元格中运行以下代码:
由此可以看出,船上近 75% 的女性幸存下来,而只有 19% 的男性活着讲述了这件事。由于性别似乎是生存的有力指标,因此gender_submission.csv的提交文件并不是一个糟糕的第一猜测!
但归根结底,这份基于性别的投稿仅基于一个专栏的预测。可以想象,通过考虑多个列,我们可以发现更复杂的模式,这些模式可能会产生更明智的预测。由于一次考虑多个列是相当困难的(或者,同时考虑许多不同列中所有可能的模式需要很长时间),我们将使用机器学习来自动执行此操作。
2、你的第一个机器学习模型
我们将构建所谓的随机森林模型。这个模型由几棵“树”构成(下图中有三棵树,但我们将构建 100 棵树!),它们将单独考虑每位乘客的数据,并投票决定个人是否幸存下来。然后,随机森林模型做出民主决定:得票最多的结果获胜!
下面的代码单元格在数据的四个不同列(“Pclass”、“”、“SibSp”和“Parch”)中查找模式。它根据 train.csv 文件中的模式构建随机森林模型中的树,然后为test.csv中的乘客生成预测。该代码还会将这些新预测保存在 CSV 文件submission.csv中。
将此代码复制到笔记本中,并在新的代码单元格中运行它。
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
Your submission was successfully saved!
同样,如果这段代码对您没有意义,请不要担心!现在,我们将重点介绍如何生成和提交预测。
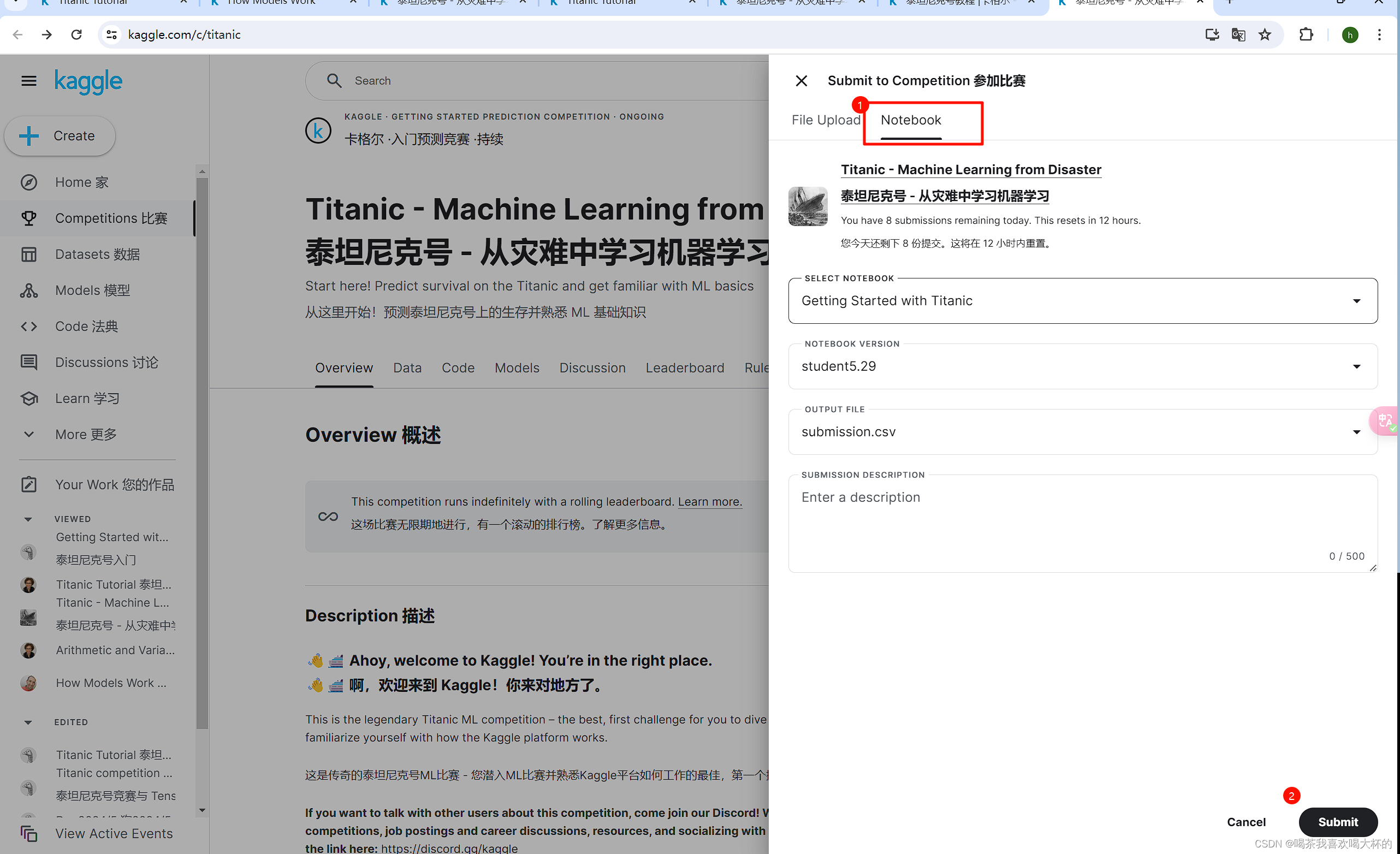
准备就绪后,单击笔记本右上角的“保存版本”按钮。这将生成一个弹出窗口。
- 确保选中“保存并全部运行”选项,然后单击“保存”按钮。
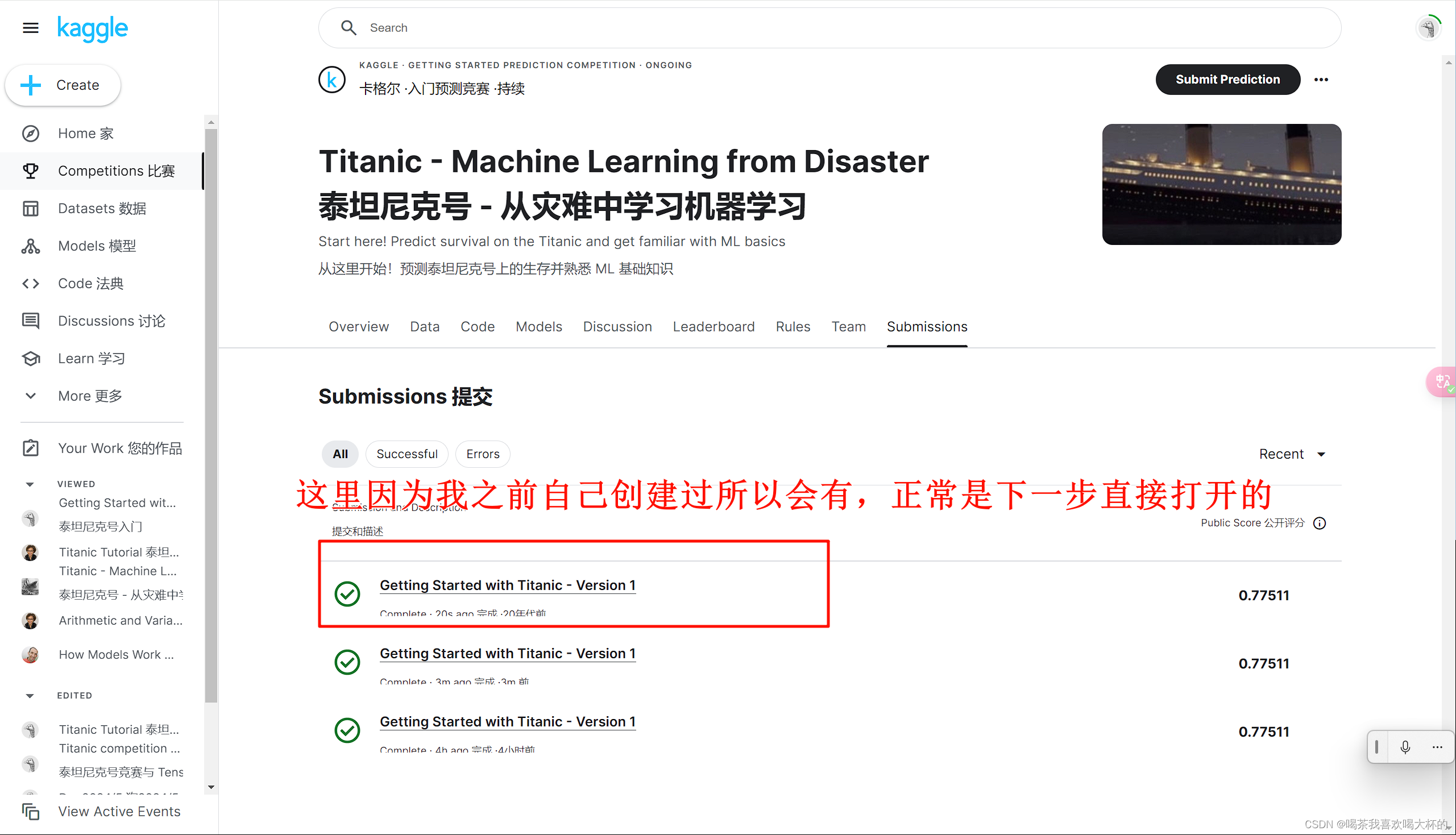
- 这将在笔记本的左下角生成一个窗口。运行完成后,单击“保存版本”按钮右侧的数字。这将在屏幕右侧拉出一个版本列表。单击最新版本右侧的省略号 (...),然后选择在查看器中打开。
- 单击屏幕顶部的“数据”选项卡。然后,单击“提交”按钮提交您的结果。
恭喜您首次向 Kaggle 比赛提交作品!在十分钟内,您应该会收到一条消息,提供您在排行榜上的位置。干得好!















 7445
7445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









