




AgentRL:多轮多任务强化学习新范式如何突破LLM智能体训练瓶颈?
本文将介绍AgentRL框架——一个专为多轮、多任务智能体强化学习训练设计的革命性框架。通过全异步生成-训练管道、跨策略采样和任务优势归一化等创新技术,AgentRL在五个智能体任务上显著超越GPT-5、Claude-Sonnet-4和DeepSeek-R1等顶尖模型,单一多任务模型性能媲美五个任务专用模型,为构建通用LLM智能体开辟了新路径。
论文标题:AgentRL: Scaling Agentic Reinforcement Learning with a Multi-Turn, Multi-Task Framework
来源:arXiv:2510.04206 [cs.AI],链接:https://arxiv.org/abs/2510.04206
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
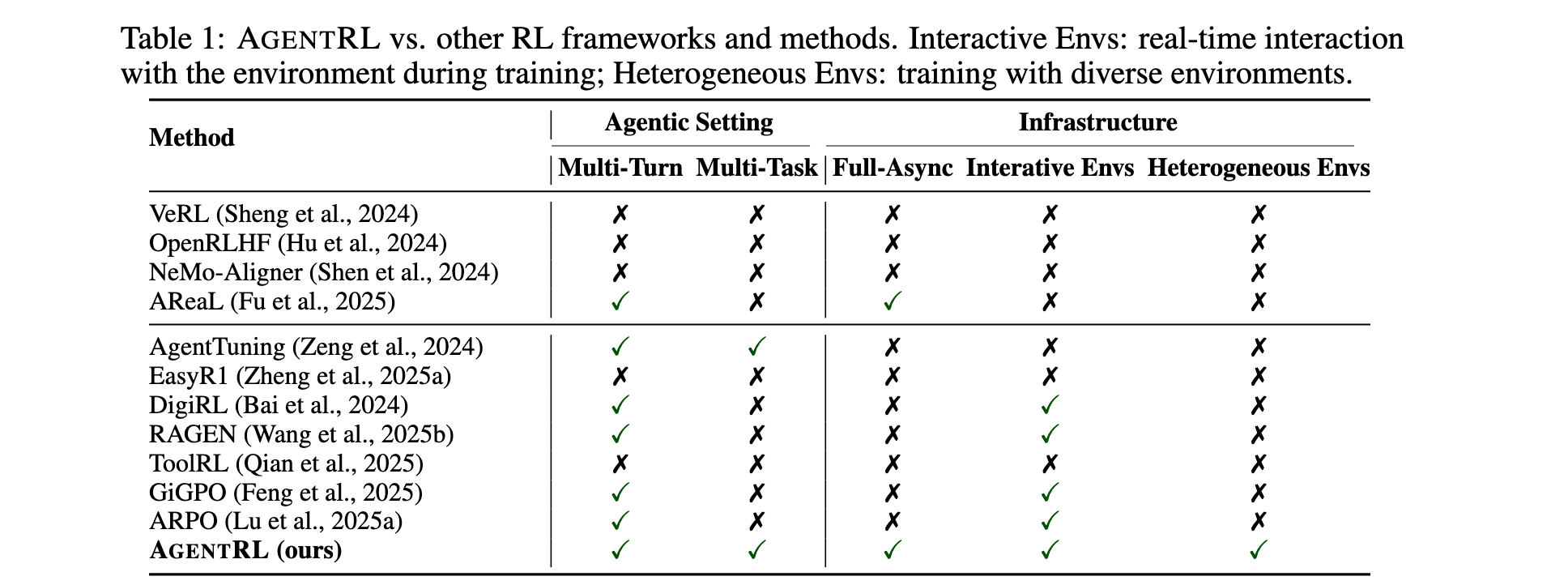
大型语言模型(LLMs)的快速发展激发了构建通用智能体的浓厚兴趣,这些智能体能够通过在线交互进行学习。然而,在多轮、多任务环境中应用强化学习(RL)训练LLM智能体仍面临巨大挑战,主要源于缺乏可扩展的基础设施和稳定的训练算法。现有的RL框架大多局限于单轮、单任务场景,无法满足现实世界中智能体需要与环境进行多轮动态交互的需求。
研究问题
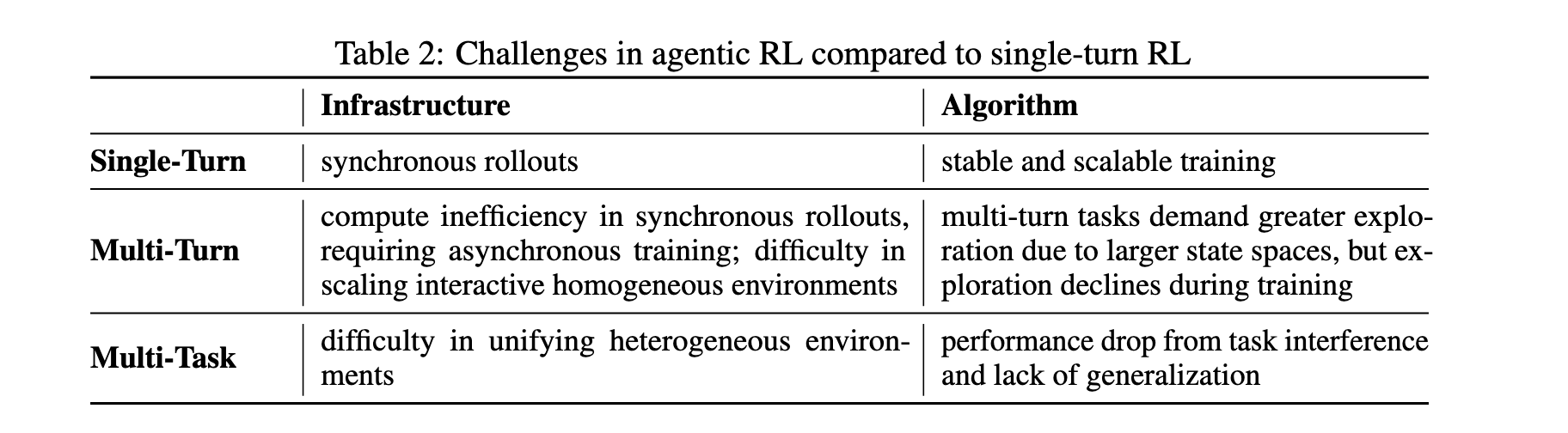
- 基础设施挑战:多轮训练中同步rollout存在计算效率低下问题,需要异步训练;难以扩展交互式同质环境以支持大规模并行训练。
- 算法探索挑战:多轮设置下状态空间巨大,模型探索能力在训练过程中下降,导致性能提升受限。
- 多任务训练挑战:异构环境难以统一,任务间干扰导致性能下降,缺乏有效的多任务优化方法。
主要贡献
- 异步多任务框架:开发了全异步生成-训练管道,显著提升多轮训练效率;设计了基于函数调用的统一API接口、容器化环境部署和集中化控制器,支持异构环境扩展。
- 跨策略采样策略:通过多个LLM生成单轨迹动作,增加候选池多样性,在保持语言有效性的同时扩展状态空间覆盖,有效解决多轮设置下的探索不足问题。
- 任务优势归一化:针对多任务RL中的任务异质性,在任务批次内归一化token级优势,确保每个任务的token级优势分布具有零均值和单位方差,显著提升多任务训练稳定性。
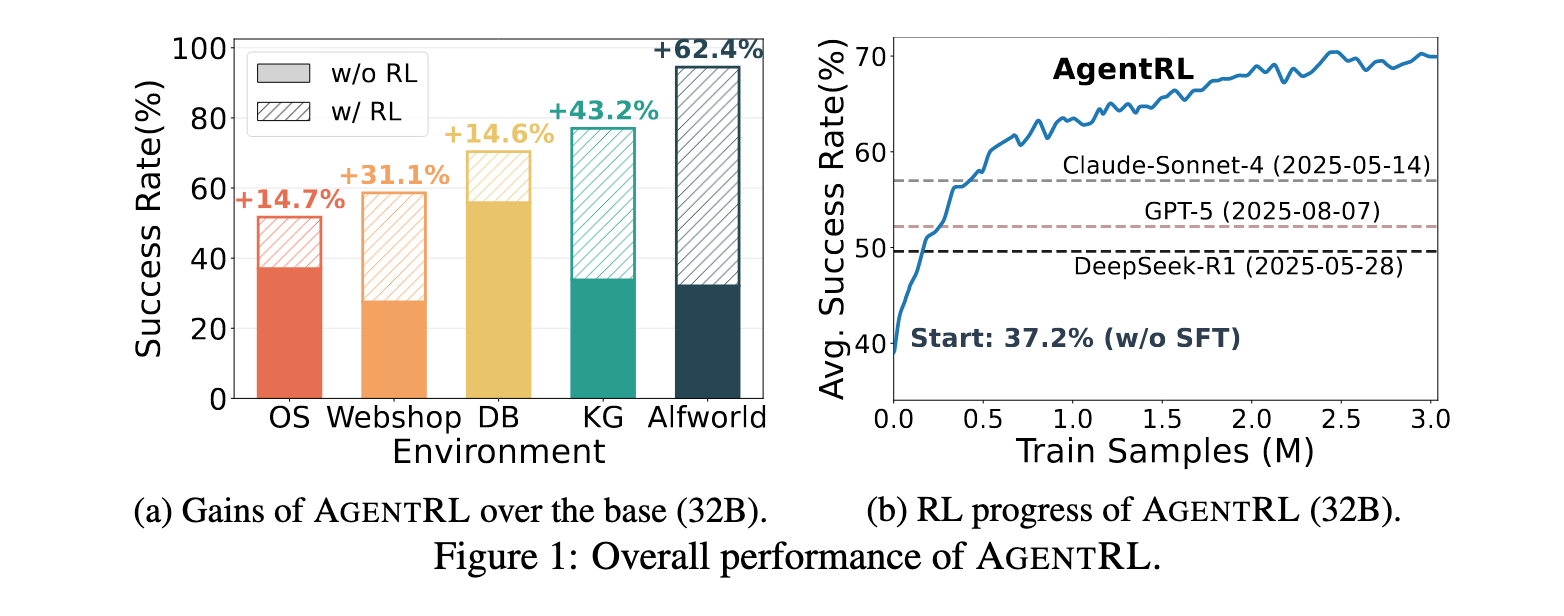
- SOTA性能验证:在五个智能体任务上,AgentRL训练的开放LLM显著超越GPT-5、Claude-Sonnet-4、DeepSeek-R1等顶尖模型;多任务训练性能媲美任务专用模型,并展现出向未见任务的泛化能力。
方法论精要
异步多轮智能体训练框架
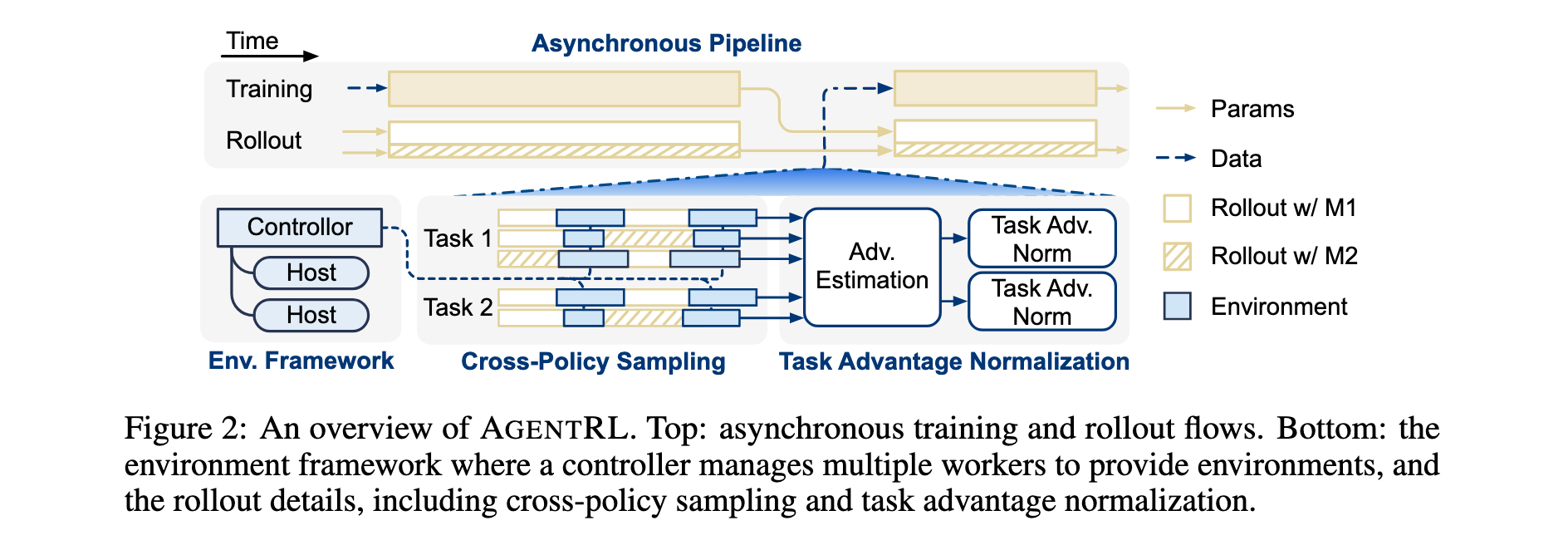
- 全异步生成-训练管道:基于协程调度的异步rollout-training策略,rollout引擎在专用资源组中运行,与训练异步执行。训练模块在每个更新后持续从rollout引擎拉取可用数据,无需等待整批rollout完成,支持动态批处理大小,有效减少GPU空闲气泡。
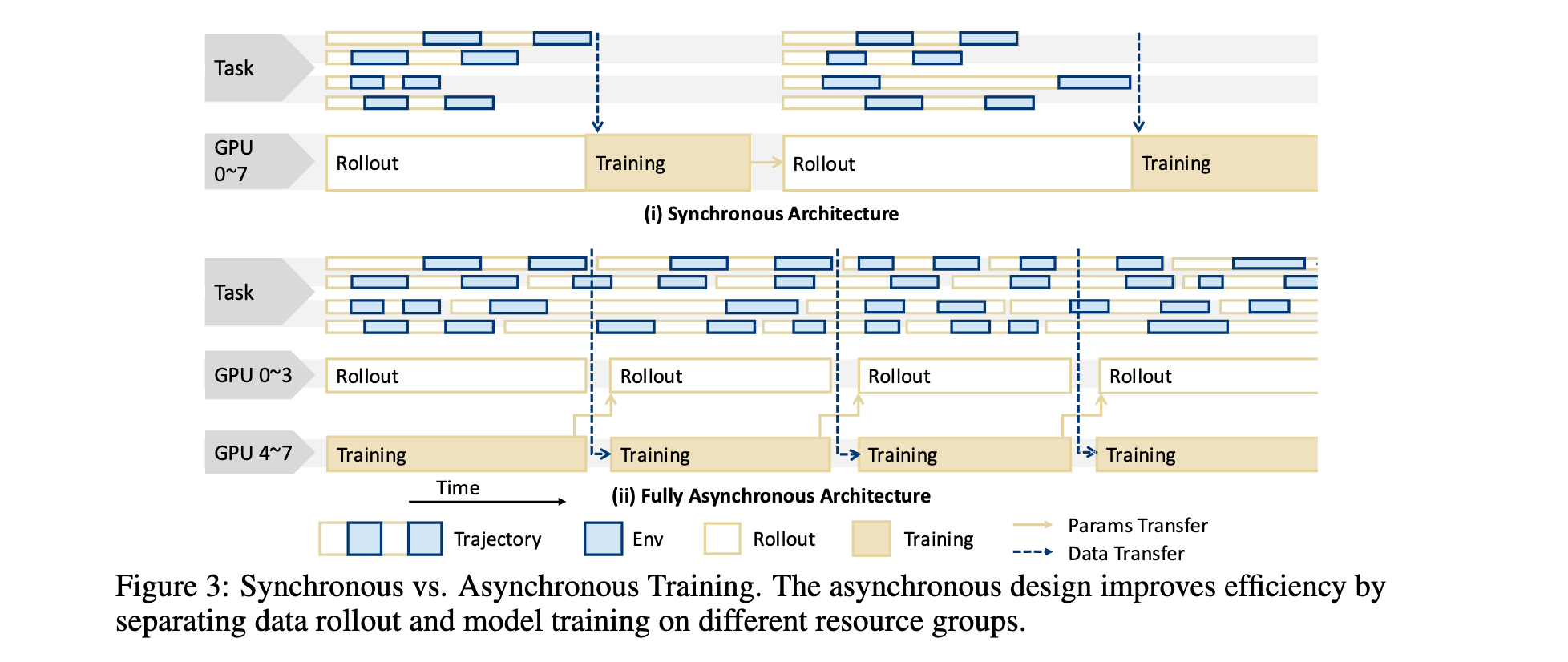
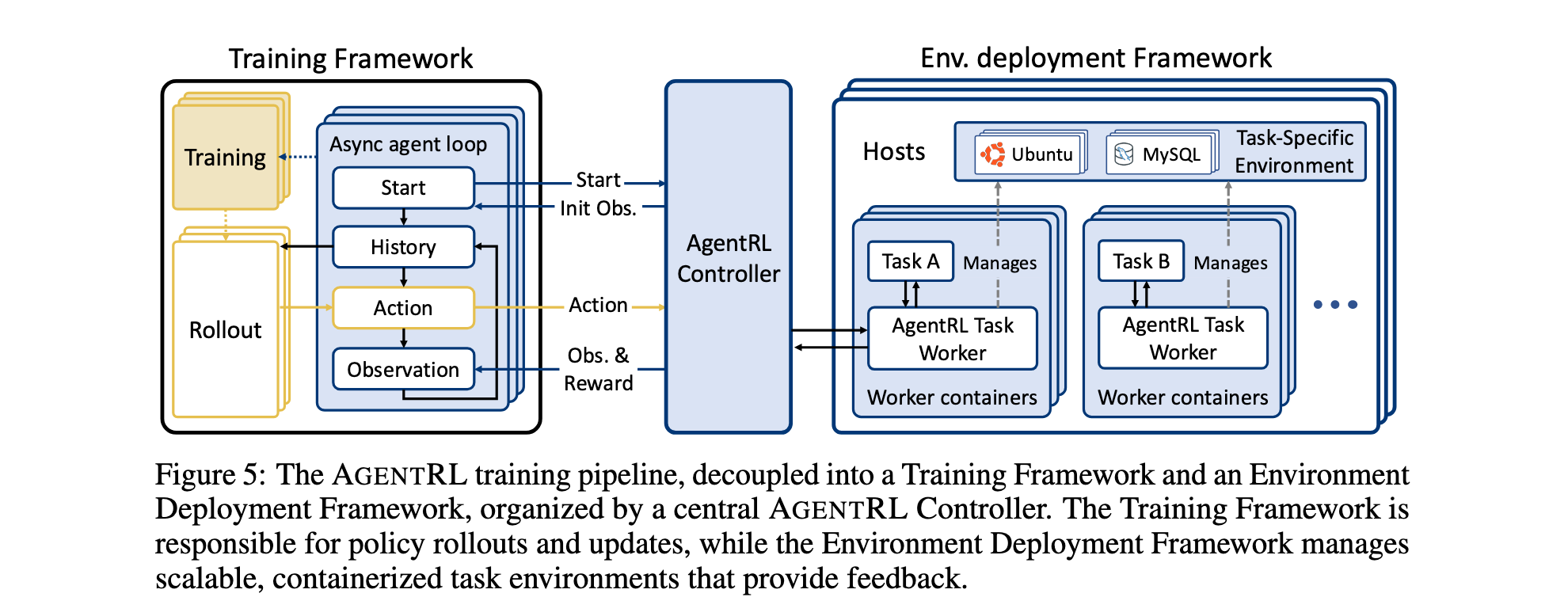
- 可扩展智能体环境基础设施:
- 函数调用环境接口:引入统一的函数调用API,简化环境交互,支持集中化管理和监控
- 容器化部署:每个任务环境容器化为独立执行单元,提高资源分配效率,隔离并发会话故障
- 集中化高性能控制器:作为训练引擎的全局协调器,优化高并发工作负载,管理数千个并行训练episode的生命周期
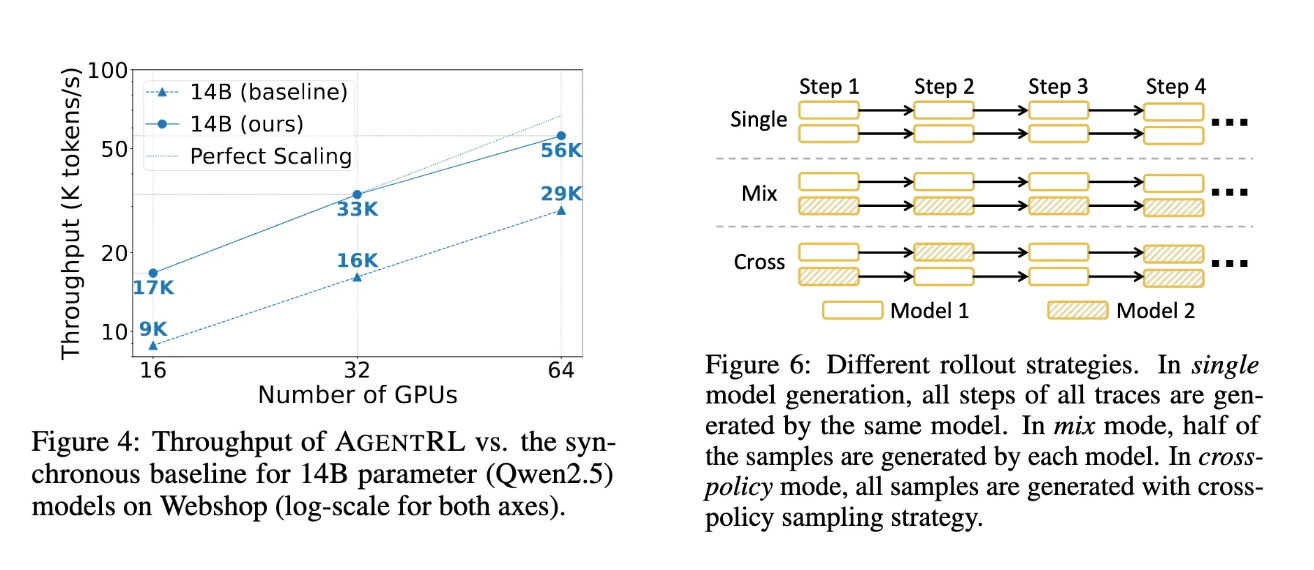
跨策略采样策略
- 策略设计:在单轨迹中允许多个LLM生成动作,每个步骤的动作从可用模型池中随机选择,而非承诺单一模型。通过聚合不同模型的数据增加候选池多样性,同时保持整体质量。
- 理论支撑:语言状态通过基础函数Γ随机映射到环境状态,跨策略采样扩展了成功状态集的语言预像覆盖范围,增加到达目标相关状态的概率,同时避免偏离语言有效区域。
- 实现方式:在RL训练中,将部分rollout引擎标记为陈旧引擎,这些引擎每多个步骤更新一次参数而非每步更新,实现与早期版本的跨策略采样。
任务优势归一化
- 问题定义:多任务RL中,智能体任务在难度、序列长度和采样效率方面差异显著,导致标准RL算法在不同任务上学习速率差异巨大,造成训练不稳定和性能不平衡。
- 归一化方法:对于每个任务i,计算token级优势估计 A ^ i , s , g , t , k \hat{A}_{i,s,g,t,k} A^i,s,g,t,k,其中i表示任务索引,s表示任务内样本索引,g表示组内轨迹索引,t表示环境步骤,k表示动作 a t a_t at内的token位置。在每个任务批次内归一化每个token的优势:
A ~ i , s , g , t , k = A ^ i , s , g , t , k − μ i σ i \tilde{A}_{i,s,g,t,k} = \frac{\hat{A}_{i,s,g,t,k} - \mu_i}{\sigma_i} A~i,s,g,t,k=σiA^i,s,g,t,k−μi
其中 μ i = mean ( A i tok ) \mu_i = \text{mean}(A^{\text{tok}}_i) μi=mean(Aitok)和 σ i = std ( A i tok ) \sigma_i = \text{std}(A^{\text{tok}}_i) σi=std(Aitok),确保每个任务的token级优势分布具有零均值和单位方差。
异构环境部署
- 统一工作器API:在所有任务中统一工作器API,使每个任务能够使用相同的生命周期操作集进行实例化和管理。
- 控制器网关API:训练侧的控制器向RL引擎提供单一网关API,抽象任务异质性,将多任务执行作为单任务情况的透明扩展。
实验洞察
数据集与基线
- 数据集:五个智能体任务涵盖多样化场景
- ALFWorld:文本冒险游戏,评估常识推理和动态规划能力
- DB:数据库管理,通过SQL查询处理自然语言问题
- KG:知识图谱导航,在大型知识图谱中执行多步推理和信息检索
- OS:操作系统交互,通过Bash命令行与Ubuntu Docker系统交互
- WebShop:网页购物,模拟电商体验中的产品搜索和决策
- 基线模型:
- 闭源API模型:Claude-Sonnet系列、GPT-5、o系列模型
- 开放基础模型:Qwen2.5-Instruct系列、DeepSeek-V3和R1
- 智能体训练方法:Hephaestus、AgentLM等
主要结果
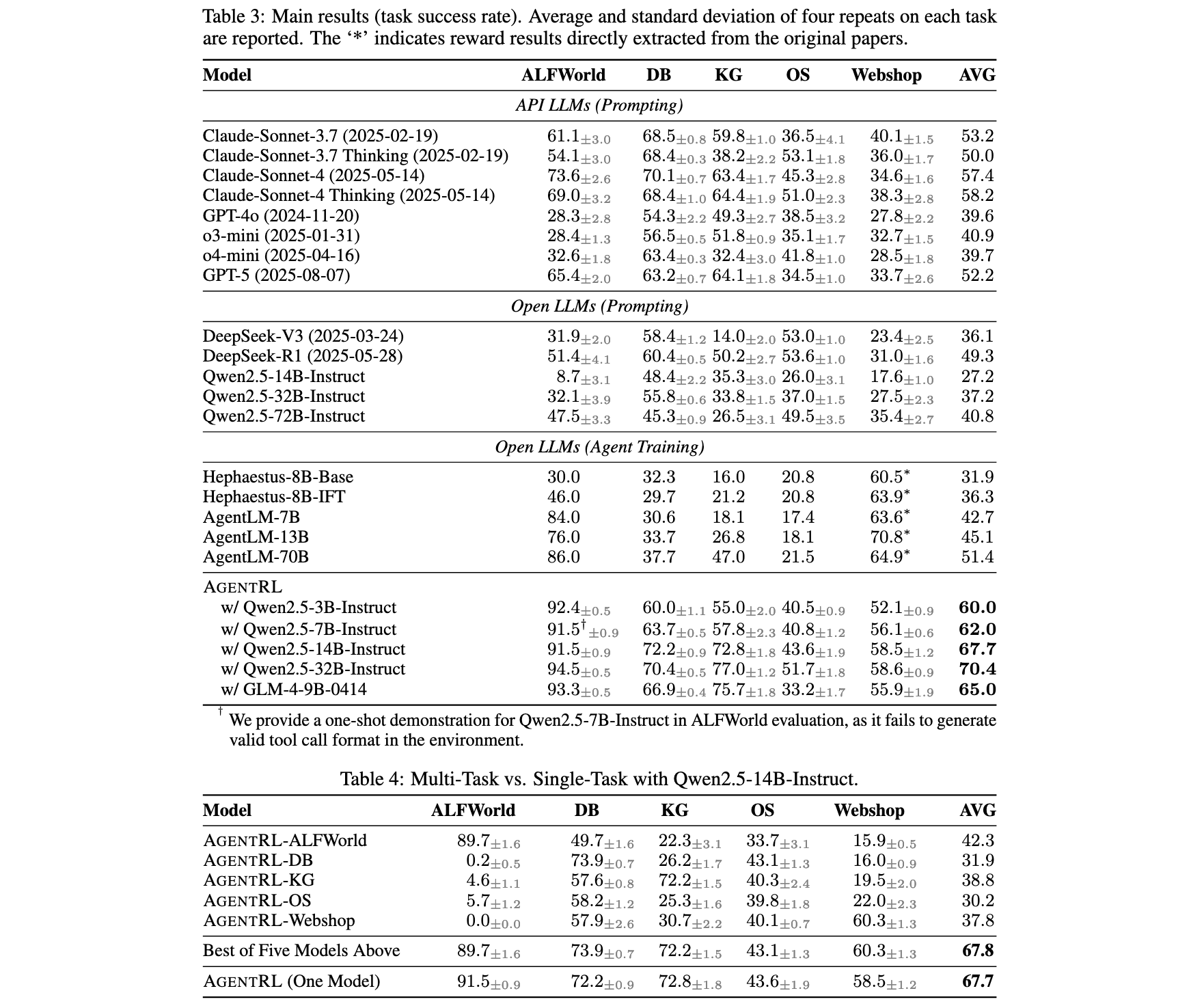
- SOTA性能:AgentRL在五个任务上建立新的顶尖平均成功率70.4%,从3B到32B的所有AgentRL训练模型一致超越包括GPT-5、Claude-Sonnet-4 Thinking和DeepSeek-R1在内的强基线。
- 多任务vs单任务:单任务RL智能体仅在特定训练环境中表现优异,但无法泛化到其他任务,跨任务转移性能差。相比之下,AgentRL多任务训练达到与"五选一"单任务专家几乎相同的性能,同时在所有任务上保持强劲表现。
- 泛化能力:在BFCL-v3基准测试上,AgentRL在多轮任务上表现明显提升,单轮任务也有适度改善,表明该方法能够增强函数调用的泛化能力。

消融实验
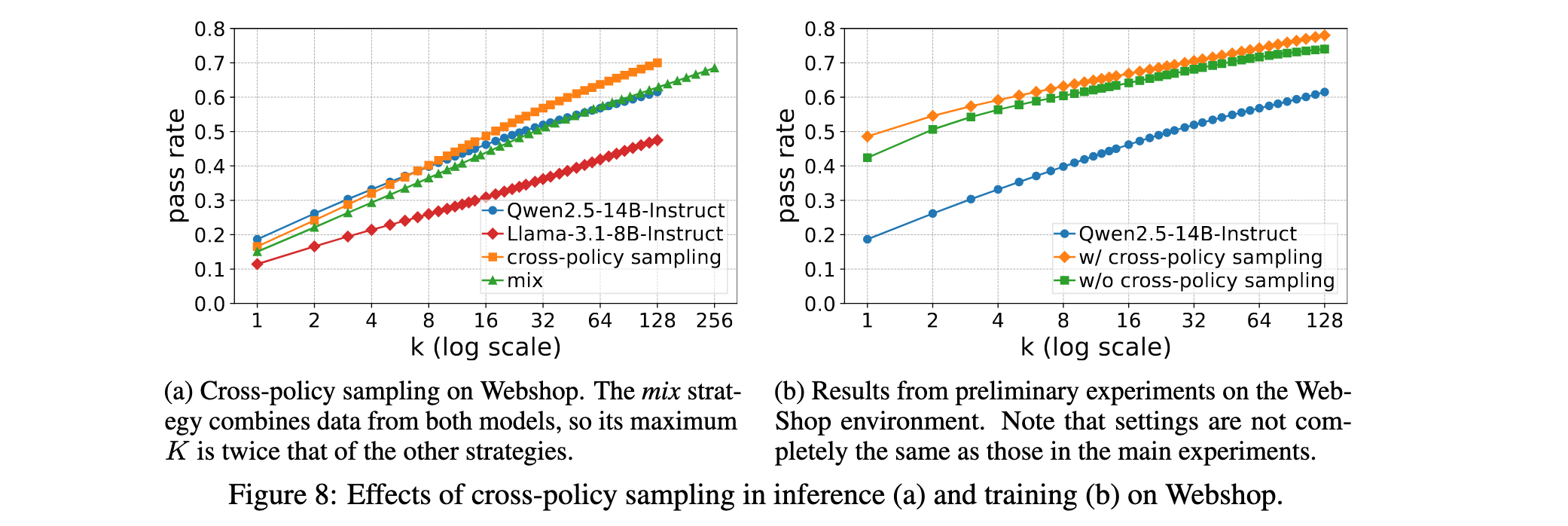
- 跨策略采样效果:移除跨策略采样导致性能显著下降,在某些开放环境中尤为明显。KG任务训练过程中,无跨策略采样的模型能力更早达到顶峰,表明跨策略采样能够探索更多可能状态,特别是在更开放的环境中扩展模型能力边界。
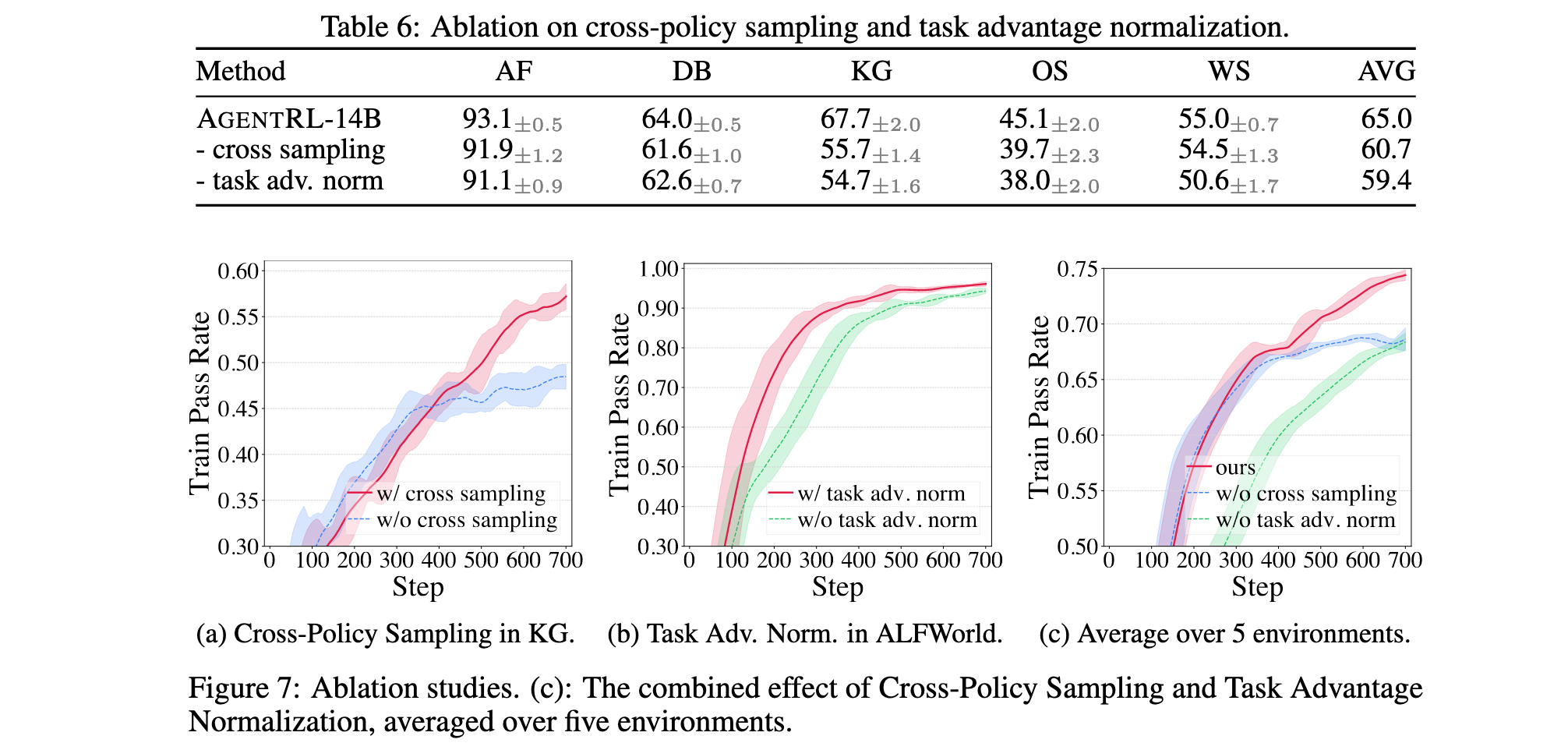
- 任务优势归一化效果:移除任务优势归一化导致明显性能下降,训练效果严重降低并在某些任务上表现出波动。模型倾向于以不同速率学习不同任务而非联合学习,表明归一化每个任务的优势有效稳定多任务训练,减少负向干扰。
关键发现
- 缩放定律:AgentRL训练模型显示清晰的缩放定律趋势,性能随模型规模增加而持续提升
- 跨架构适用性:成功应用于不同架构系列的模型,验证框架的广泛适用性
- OOD泛化:在未见任务上的表现提升,证明方法超越训练分布的泛化能力
- 训练稳定性:异步设计显著提升训练吞吐量,相比同步基线带来显著效率提升
技术创新与未来展望
核心技术突破
- 异步训练架构:通过解耦rollout和训练,实现高效的硬件调度,显著提升多轮训练吞吐量
- 环境统一抽象:函数调用API和容器化部署实现异构环境的无缝集成和扩展
- 探索策略创新:跨策略采样在保持语言有效性的同时扩展状态空间覆盖
- 多任务优化:任务优势归一化有效缓解任务间干扰,稳定训练过程
局限性与改进方向
- 分布偏移:跨策略采样可能引入轻微的分布偏移,导致训练动态中的轻微不稳定性
- 环境复杂度:当前工作专注于受控环境,未来需要扩展到更复杂动态的现实场景
- 模型规模限制:当前验证主要在中等规模模型,需要进一步验证在超大模型上的效果
未来发展方向
- 环境扩展:将AgentRL扩展到更广泛的环境类型和更大的模型规模
- 算法优化:探索更复杂的跨策略采样变体和改进的多任务优化方法
- 现实应用:在真实世界复杂场景中应用和验证框架性能
- 通用智能体:朝着创建更通用和更强大的LLM智能体目标迈进
AgentRL框架为多轮、多任务智能体强化学习训练提供了系统性的解决方案,通过基础设施和算法的双重创新,不仅实现了SOTA性能,更为构建通用LLM智能体奠定了坚实基础。随着框架的不断完善和扩展,我们有理由相信,真正的通用人工智能智能体正在向我们走来。



















 5001
5001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









