







docker搭建ELK+filebeat+springboot项目配置
一、Docker安装-离线
1.1下载 Docker 离线包
链接:https://pan.baidu.com/s/1HTEHMuU3K0k07Ej97CFPRQ?pwd=7734 提取码:7734
–来自百度网盘超级会员V6的分享
在这里可以选择自己需要的版本进行下载:
https://download.docker.com/linux/static/stable/
1.2离线安装工具
https://github.com/Jrohy/docker-install/
按图示下载安装工具:
链接:https://pan.baidu.com/s/1PYqAU2jOadCWrjjnjtmPOQ?pwd=7734 提取码:7734
–来自百度网盘超级会员V6的分享
1.3安装
将前面下载的以下文件放入服务器的 /root/docker-install 文件夹下:
- [docker-install]
- docker-20.10.6.tgz
- install.sh
- docker.bash
执行安装:
# 进入 docker-install 文件夹
cd docker-install
# 为 docker-install 添加执行权限
chmod +x install.sh
# 安装
./install.sh -f docker-20.10.6.tgz
1.4镜像加速
由于国内网络问题,需要配置加速器来加速。
修改配置文件 /etc/docker/daemon.json
下面命令直接生成文件 daemon.json
cat <<EOF > /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com"
],
"max-concurrent-downloads": 10,
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"data-root": "/var/lib/docker"
}
EOF
1.5确认安装结果
docker info
docker run hello-world
ps:在线安装Docker
我们使用 Docker 来运行 Elasticsearch,首先安装 Docker,参考下面笔记:
二、Docker搭建ES集群
2.1关闭防火墙
后面我们要使用多个端口,为了避免繁琐的开放端口操作,我们关掉防火墙
# 关闭防火墙
systemctl stop firewalld.service
# 禁用防火墙
systemctl disable firewalld.service
2.2下载 Elastic Search 镜像
docker pull elasticsearch:7.9.3
链接:https://pan.baidu.com/s/1s9BCzzE-BmKAbU2IAjLouQ?pwd=7734 提取码:7734
–来自百度网盘超级会员V6的分享
2.3集群部署结构
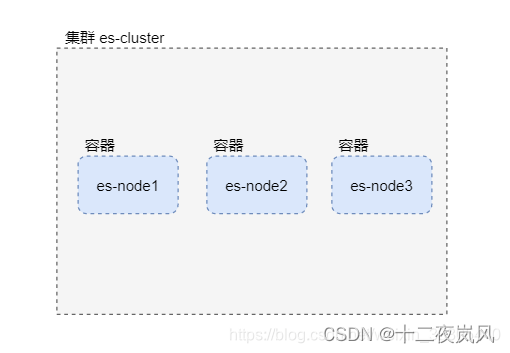
在一台服务器上,使用Docker部署三个ES容器组成的集群
2.4准备虚拟网络和挂载目录
# 创建虚拟网络
docker network create es-net
# node1 的挂载目录
mkdir -p -m 777 /var/lib/es/node1/plugins
mkdir -p -m 777 /var/lib/es/node1/data
# node2 的挂载目录
mkdir -p -m 777 /var/lib/es/node2/plugins
mkdir -p -m 777 /var/lib/es/node2/data
# node3 的挂载目录
mkdir -p -m 777 /var/lib/es/node3/plugins
mkdir -p -m 777 /var/lib/es/node3/data
2.5设置 max_map_count
必须修改系统参数 max_map_count,否则 Elasticsearch 无法启动:
在 /etc/sysctl.conf 文件中添加 vm.max_map_count=262144
echo 'vm.max_map_count=262144' >>/etc/sysctl.conf
# 立即生效
sysctl -p
确认参数配置:
cat /etc/sysctl.conf
2.6启动 Elasticsearch 集群
node1:
docker run -d \
--name=node1 \
--restart=always \
--net es-net \
-p 9200:9200 \
-p 9300:9300 \
-v /var/lib/es/node1/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node1/data:/usr/share/elasticsearch/data \
-e node.name=node1 \
-e node.master=true \
-e network.host=node1 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
环境变量说明:
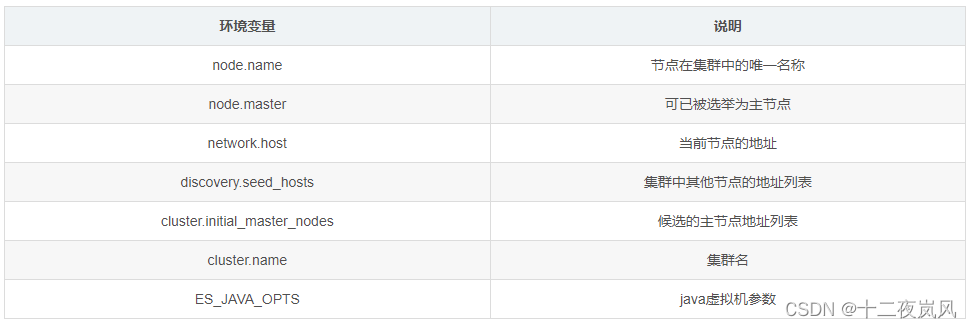 参考 https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html
参考 https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html
node2:
docker run -d \
--name=node2 \
--restart=always \
--net es-net \
-p 9201:9200 \
-p 9301:9300 \
-v /var/lib/es/node2/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node2/data:/usr/share/elasticsearch/data \
-e node.name=node2 \
-e node.master=true \
-e network.host=node2 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
node3:
docker run -d \
--name=node3 \
--restart=always \
--net es-net \
-p 9202:9200 \
-p 9302:9300 \
-v /var/lib/es/node3/plugins:/usr/share/elasticsearch/plugins \
-v /var/lib/es/node3/data:/usr/share/elasticsearch/data \
-e node.name=node3 \
-e node.master=true \
-e network.host=node3 \
-e discovery.seed_hosts=node1,node2,node3 \
-e cluster.initial_master_nodes=node1 \
-e cluster.name=es-cluster \
-e "ES_JAVA_OPTS=-Xms256m -Xmx256m" \
elasticsearch:7.9.3
2.7查看启动结果结果
http://192.168.128.136:9200

http://192.168.128.136:9200/_cat/nodes

2.8chrome浏览器插件:elasticsearch-head
elasticsearch-head 项目提供了一个直观的界面,可以很方便地查看集群、分片、数据等等。elasticsearch-head最简单的安装方式是作为 chrome 浏览器插件进行安装。
- 在 elasticsearch-head 项目仓库中下载 chrome 浏览器插件
https://github.com/mobz/elasticsearch-head/raw/master/crx/es-head.crx - 将文件后缀改为 zip
- 解压缩
- 在 chrome 浏览器中选择“更多工具”–“扩展程序”
- 在“扩展程序”中确认开启了“开发者模式”
- 点击“加载已解压的扩展程序”
- 选择前面解压的插件目录
- 在浏览器中点击 elasticsearch-head 插件打开 head 界面,并连接

2.9Elasticsearch安装IK中文分词器
从 ik 分词器项目仓库中下载 ik 分词器安装包,下载的版本需要与 Elasticsearch 版本匹配:
https://github.com/medcl/elasticsearch-analysis-ik
链接:https://pan.baidu.com/s/11omvwfDly4_HU-z8ESCkeQ?pwd=7734 提取码:7734
–来自百度网盘超级会员V6的分享
下载 elasticsearch-analysis-ik-7.9.3.zip 复制到 /root/ 目录下
在三个节点上安装 ik 分词器
cd ~/
# 复制 ik 分词器到三个 es 容器
docker cp elasticsearch-analysis-ik-7.9.3.zip node1:/root/
docker cp elasticsearch-analysis-ik-7.9.3.zip node2:/root/
docker cp elasticsearch-analysis-ik-7.9.3.zip node3:/root/
# 在 node1 中安装 ik 分词器
docker exec -it node1 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip
# 在 node2 中安装 ik 分词器
docker exec -it node2 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip
# 在 node3 中安装 ik 分词器
docker exec -it node3 elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.3.zip
# 重启三个 es 容器
docker restart node1 node2 node3
查看安装结果
在浏览器中访问 http://192.168.128.136:9200/_cat/plugins

如果插件不可用,可以卸载后重新安装:
docker exec -it node2 elasticsearch-plugin remove analysis-ik docker exec -it node3 elasticsearch-plugin remove analysis-ik ```
ik分词测试
ik分词器提供两种分词器: ik_max_word 和 ik_smart
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
ik_max_word 分词测试
使用 head 执行下面测试:
向 http://192.168.128.136:9200/_analyze 路径提交 POST 请求,并在协议体中提交 Json 数据:
{
"analyzer":"ik_max_word",
"text":"中华人民共和国国歌"
}

ik_smart 分词测试
使用 head 执行下面测试:
向 http://192.168.128.136:9200/_analyze 路径提交 POST 请求,并在协议体中提交 Json 数据:
{
"analyzer":"ik_smart",
"text":"中华人民共和国国歌"
}

三、Docker搭建Kibana
3.1下载 Kibana 镜像
docker pull kibana:7.9.3
3.2启动 Kibana 容器
docker run \
-d \
--name kibana \
--net es-net \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS='["http://node1:9200","http://node2:9200","http://node3:9200"]' \
--restart=always \
kibana:7.9.3
Kibana汉化:
docker exec -it kibana bash
echo -e "\ni18n.locale: \"zh-CN\"">>/usr/share/kibana/config/kibana.yml
exit
docker restart kibana
启动后,浏览器访问 Kibana,进入 Dev Tools:
http://192.168.128.136:5601/

四、Docker搭建Logstash和使用方法
4.1下载Logstash镜像
docker pull logstash:7.9.3
4.2建立文件夹,给data文件夹777权限
[root@centos7964 /var/lib/elk/logstash]# ll
总用量 0
drwxrwxrwx. 2 root root 47 5月 14 09:59 config
drwxrwxrwx. 4 root root 69 5月 14 10:11 data
drwxrwxrwx. 2 root root 27 5月 15 09:33 pipeline
只需要建logstash.yml、pipelines.yml、logstash.conf文件
[root@centos7964 /var/lib/elk/logstash]# tree
.
├── config
│ ├── jvm.options
│ ├── logstash.yml
│ └── pipelines.yml
├── data
│ ├── dead_letter_queue
│ ├── queue
│ └── uuid
└── pipeline
└── logstash.conf
5 directories, 5 files
4.3只需要建logstash.yml、pipelines.yml、logstash.conf文件
内容分别为
path.logs: /usr/share/logstash/logs
config.test_and_exit: false
config.reload.automatic: false
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.133.100:9200" ]
# This file is where you define your pipelines. You can define multiple.
# # For more information on multiple pipelines, see the documentation:
# # https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
#
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline/logstash.conf"
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 5044
codec => json_lines
}
}
filter{
}
output {
elasticsearch {
hosts => ["192.168.128.136:9200"]
index => "elk_logstash"
}
if [appname] == "Saledev" {
elasticsearch {
hosts => "192.168.128.136:9200"
index => "saledevlog_%{+YYYY.MM.dd}"
}
}
if [appname] == "Qualitydev" {
elasticsearch {
hosts => "192.168.128.136:9200"
index => "qualitydevlog_%{+YYYY.MM.dd}"
}
}
if [appname] == "Purchasedev" {
elasticsearch {
hosts => "192.168.128.136:9200"
index => "purchasedevlog_%{+YYYY.MM.dd}"
}
}
if [appname] == "MESdev" {
elasticsearch {
hosts => "192.168.128.136:9200"
index => "mesdevlog_%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
4.4创建容器
docker run -it \
--name logstash \
--restart=always \
--privileged \
-p 5044:5044 \
-p 9600:9600 \
--net es-net \
-v /etc/localtime:/etc/localtime \
-v /var/lib/elk/logstash/config:/usr/share/logstash/config \
-v /var/lib/elk/logstash/pipeline:/usr/share/logstash/pipeline \
-v /var/lib/elk/logstash/data:/usr/share/logstash/data \
-d logstash:7.9.3
查看日志是否启动成功,没报错就可以
4.5SpringBoot整合logstash
引入依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.3</version>
</dependency>
配置spring-logback.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文档如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文档是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。
当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="10 seconds">
<property name="log.path" value="./logs"/>
<springProperty scope="context" name="env" source="spring.profiles.active"/>
<springProperty scope="context" name="appName" source="spring.application.name"/>
<property name="console.log.pattern"
value="%red(%d{yyyy-MM-dd HH:mm:ss}) %green([%thread]) %highlight(%-5level) %boldMagenta(%logger{36}%n) - %msg%n"/>
<property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n"/>
<!-- 控制台输出 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${console.log.pattern}</pattern>
<charset>utf-8</charset>
</encoder>
</appender>
<!-- 控制台输出 -->
<appender name="file_console" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/sys-console.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志文件名格式 -->
<fileNamePattern>${log.path}/sys-console.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- 日志最大 1天 -->
<maxHistory>1</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${log.pattern}</pattern>
<charset>utf-8</charset>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- 过滤的级别 -->
<level>INFO</level>
</filter>
</appender>
<!-- 系统日志输出 -->
<appender name="file_info" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/sys-info.log</file>
<!-- 循环政策:基于时间创建日志文件 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志文件名格式 -->
<fileNamePattern>${log.path}/sys-info.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>60</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${log.pattern}</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<!-- 过滤的级别 -->
<level>INFO</level>
<!-- 匹配时的操作:接收(记录) -->
<onMatch>ACCEPT</onMatch>
<!-- 不匹配时的操作:拒绝(不记录) -->
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<appender name="file_error" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/sys-error.log</file>
<!-- 循环政策:基于时间创建日志文件 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志文件名格式 -->
<fileNamePattern>${log.path}/sys-error.%d{yyyy-MM-dd}.log</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>60</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${log.pattern}</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<!-- 过滤的级别 -->
<level>ERROR</level>
<!-- 匹配时的操作:接收(记录) -->
<onMatch>ACCEPT</onMatch>
<!-- 不匹配时的操作:拒绝(不记录) -->
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- info异步输出 -->
<appender name="async_info" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>512</queueSize>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref="file_info"/>
</appender>
<!-- error异步输出 -->
<appender name="async_error" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>512</queueSize>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref="file_error"/>
</appender>
<!--LOGSTASH config -->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.128.136:5044</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder">
<!--自定义时间戳格式, 默认是yyyy-MM-dd'T'HH:mm:ss.SSS<-->
<timestampPattern>yyyy-MM-dd HH:mm:ss</timestampPattern>
<customFields>{"appname":"${appName}${env}"}</customFields>
</encoder>
</appender>
<!--系统操作日志-->
<root level="info">
<appender-ref ref="console" />
<appender-ref ref="async_info" />
<appender-ref ref="async_error" />
<appender-ref ref="file_console" />
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
主要配置ip地址和端口
4.6使日志插入logstash
只需要使用lombok依赖的@Slf4j注解,把要放入日志的东西加进去即可
package com.wnhz.smart.es.controller;
import com.wnhz.smart.common.http.ResponseResult;
import com.wnhz.smart.es.doc.BookTabDoc;
import com.wnhz.smart.es.service.IBookTabDocService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* @author Hao
* @date 2023-12-06 10:40
*/
@RestController
@RequestMapping("/api/query")
@Slf4j
public class QueryController {
@Autowired
private IBookTabDocService iBookTabDocService;
@GetMapping("/test")
public ResponseResult<List<BookTabDoc>> test() {
List<BookTabDoc> allBooks = iBookTabDocService.getAllBooks();
log.debug("从es中查询到的所有数据:{}", allBooks.subList(0, 1000));
return ResponseResult.ok(allBooks.subList(0, 3));
}
}
这样所有的数据就会自动插入logstash
4.7配置kibana
进入http://192.168.128.136:5601/app/management(原网页点击Stack Management),点击index Patterns创建匹配模式,输入logstash.conf文件中的index后面的名字,这里是elk_logstash
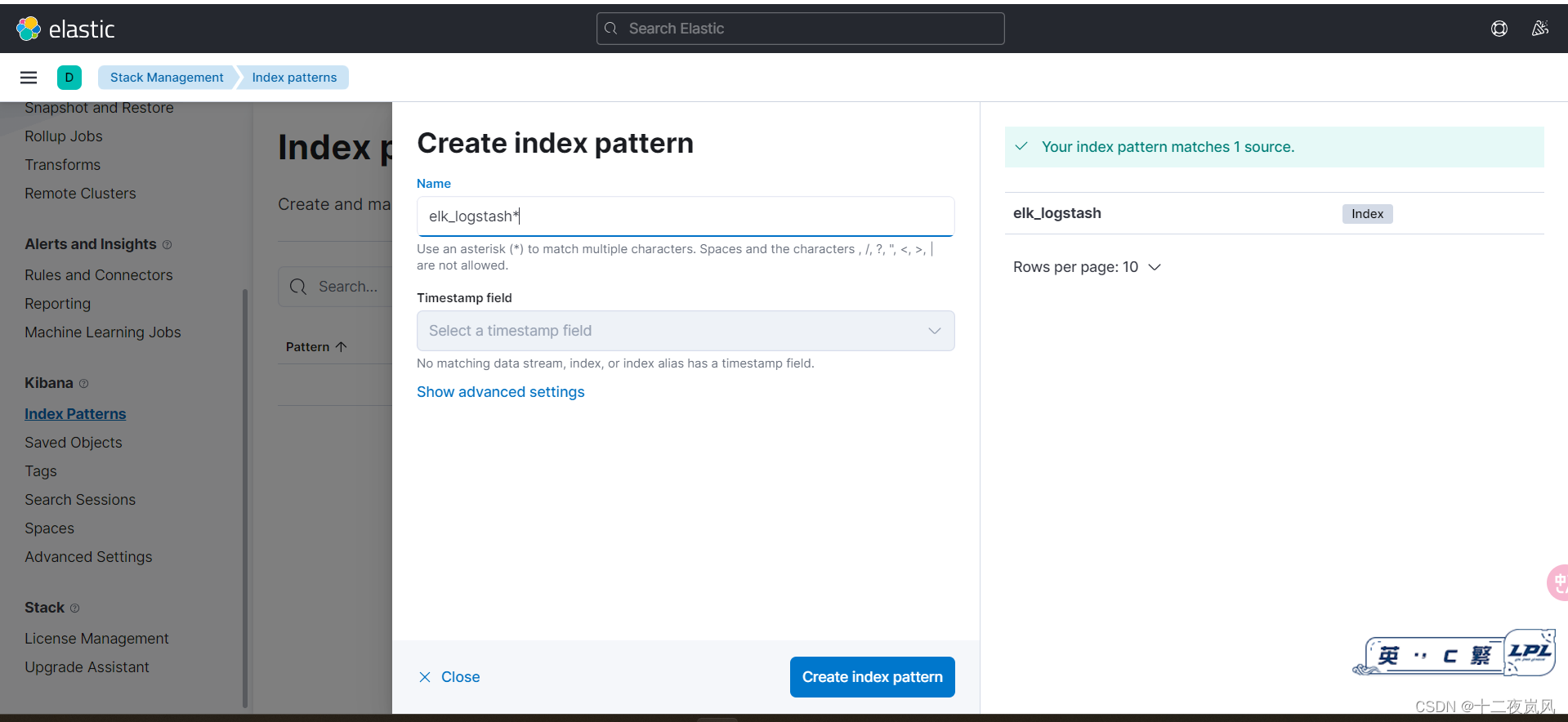
查询方法:message 内容
日志的条数查询错误解决
当日志的条数太多会出现下面的错误警告
The length [1417761] of field [message] in doc[20]/index[elk_logstash] exceeds the
[index.highlight.max_analyzed_offset] limit [1000000]. To avoid this
error, set the query parameter [max_analyzed_offset] to a value less
than index setting [1000000] and this will tolerate long field values
by truncating them.
解决方法
解决方案,使用任意一个可以put http值和参数的工具,对目标主机上部署的es进行put命令配置:
!!!注意是put请求,请求地址和body参数分别为:
http://localhost:9200/_all/_settings?preserve_existing=true
{
"index.highlight.max_analyzed_offset" : "999999999"
}
返回结果这样就是成功了
{
"acknowledged": true
}
五、Docker搭建Filebeat和使用方法
5.1下载Filebeat镜像
docker pull elastic/filebeat:7.9.3
5.2临时启动镜像
docker run -d --name=filebeat elastic/filebeat:7.9.3
5.3拷贝数据文件
docker cp filebeat:/usr/share/filebeat /var/lib/elk/
chmod 777 -R /var/lib/elk/filebeat
chmod go-w /var/lib/elk/filebeat/filebeat.yml
5.4编辑配置文件
# 收集系统日志
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
output.elasticsearch:
hosts: '192.168.31.196:9200'
indices:
- index: "filebeat-%{+yyyy.MM.dd}"
5.5以新的方式启动
docker rm -f filebeat
docker run -d \
--name=filebeat \
--user=root \
--restart=always \
--net es-net \
-v /var/lib/elk/filebeat:/usr/share/filebeat \
-v /var/lib/elk/logdemo:/var/log/messages \
elastic/filebeat:7.9.3
等待30秒,查看日志是否有错误
docker logs -f filebeat
5.6查看日志
访问elasticsearch head
http://192.168.128.136:9200/
















 3101
3101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









