






MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。同时也衍生了很多用于操作Mysql数据库的软件,图形界面工具有:sqlyog,navicat,mysql workbench,这里用sqlyog来举例。
1、通过图形界面对MySQL数据库进行操作
<1>安装sqlyog
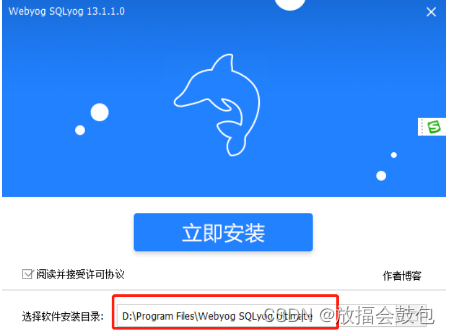
<2>傻瓜式安装 ,安装完成后,创建新连接<3>输入MySQL服务器的ip,端口号,用户名和密码,进行连接

<3>输入Mysql服务器的ip端口号,用户名和密码,进行连接。
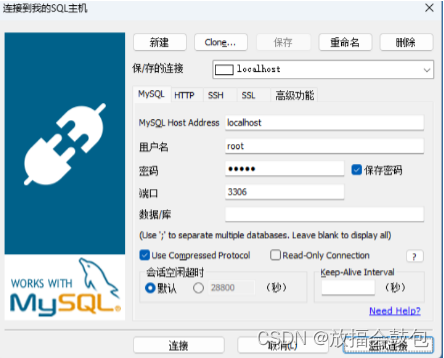
<4>连接成功,进入到图形界面,进行操作
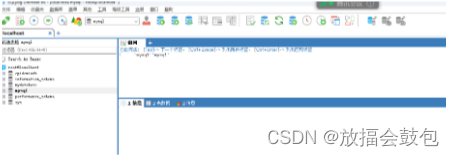
<5>创建数据库右键单击,选择创建数据库
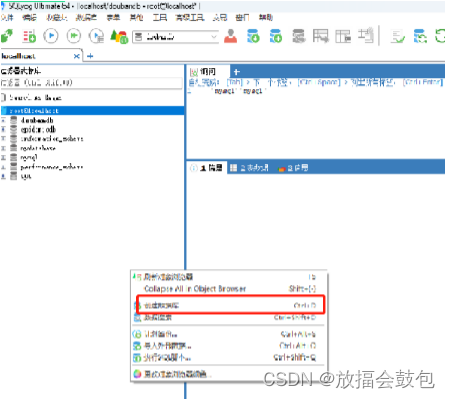

<2>创建表
选择doubandb数据库,在表上右键单击,选择创建表

填写表相关信息和列相关信息

注意点:
1、表的引擎选择: innodb
2、表的字符集: utf8
3、一张表只能有一个主键,主键必须唯一,非空。通过主键可以唯一确定一条记录
4、数据类型的选择,字符串: varchar 数字:float或int, 日期类型: date或datetime

<3>添加数据在books表上选择“打开表”,

2、使用命令行操作数据库
<1>连接数据库
mysql -u root -p密码
<2>查看数据库
show databases

名称解释命令DDL(数据定义语言)定义和管理数据对象CREATE DROP ALTER
<3> 切换数据库
use 数据库名称

<4>创建数据库create database 数据库名

<5>删除数据库drop database 数据库名

3、通过结构化查询语句**SQL**操作关系型数据库


<1>DDL
创建数据表
create table [if not exists] `表名`(
'字段名1' 列类型 [属性][索引][注释],
'字段名2' 列类型 [属性][索引][注释],
#...
'字段名n' 列类型 [属性][索引][注释]
)[表类型][表字符集][注释];
栗子:
CREATE TABLE IF NOT EXISTS `users`(
`uid` VARCHAR(200) PRIMARY KEY NOT NULL COMMENT '用户id',
`username` VARCHAR(200) UNIQUE NOT NULL COMMENT '用户名',
`gender` INT NOT NULL DEFAULT 1
) ENGINE=INNODB DEFAULT CHARSET=utf8;
列类型:
varchar(长度)
int
float
date/datetime
数据字段属性
UnSigned :
无符号的
声明该数据列不允许负数 .
ZEROFILL :
0填充的
不足位数的用0来填充 , 如int(3),5则为005
Auto_InCrement :
自动增长的 , 每添加一条数据 , 自动在上一个记录数上加 1(默认)
通常用于设置主键 , 且为整数类型
可定义起始值和步长
当前表设置步长(AUTO_INCREMENT=100) : 只影响当前表 SET @@auto_increment_increment=5 ; 影响所有使用自增的表(全局)
NULL 和 NOT NULL :
默认为NULL , 即没有插入该列的数值
如果设置为NOT NULL , 则该列必须有值
DEFAULT :
默认的
用于设置默认值
例如,性别字段,默认为"男" , 否则为 “女” ; 若无指定该列的值 , 则默认值为"男"的值
primary key:
用于设置主键
unique:
用于设置唯一性,不能重复,但是可以为空
ENGINE=innodb DEFAULT CHARSET=utf8:SQL引擎及其约束和字符编码
显示表结构:
desc 表名;

删除数据表(慎用)
drop table 表名
修改表
修改表名:ALTER TABLE 旧表名 RENAME AS 新表名
alter table userss rename as users添加字段:ALTER TABLE 表名 ADD 字段名 列类型 [ 属性 ]
ALTER TABLE users ADD `password` VARCHAR(200) COMMENT '密码';
--一次性添加多个字段
ALTER TABLE users ADD `tel` VARCHAR(200), ADD `address` VARCHAR(200);
修改字段:ALTER TABLE 表名 MODIFY 字段名 列类型 [ 属性 ]
alter table users modify `gender` varchar(100) default '男';
删除字段:ALTER TABLE 表名 DROP 字段名
alter table users drop `tel`, drop `gender`;
<2>DML
insert
INSERT INTO 表名 [(字段1, 字段2, 字段2,.... )] VALUES('值1','值2','值3',...)
insert into users(uid,username,password) values('u1001','admin','123456');
INSERT INTO users VALUES('u1002','ls','123456','','');
--可同时插入多条数据,values 后用英文逗号隔开
INSERT INTO users VALUES('u1003','ls','123456','',''),
('u1004','ww','123456','','');
update
UPDATE 表名 SET column_name = value [ ,column_name2 = value2, .... ] [WHERE condition];
-- 修改uid='u1001'的password为654321
update users set password ='654321' where uid='u1001';
-- 修改uid='u1001'的password为123456和tel为18954271245
update users set password ='1234566',tel='18954271245' where uid='u1001';
-- 修改users表中所有数据的address为无
update users set address = '无' where 1=1
-- 修改users表中username不等于admin的数据,将 address修改为null
update users set address = null where username <> 'admin'
-- 修改users表中age>18的用户的address为陕西
update users set address='陕西' where age > 18
-- 修改users表中age>18并且小于40 的用户的address为山西
UPDATE users SET address='山西' WHERE age between 18 and 40;
UPDATE users SET address='山西运煤到西山' WHERE age >=18 and age <=40
-- 修改users表中username为admin 或ls的地址为四川
UPDATE users u SET u.address='四川' WHERE u.username = 'admin' or u.username= 'ls'
UPDATE users u SET u.address='四川' WHERE u.username in('admin','ls')
-- 修改users表中username包含ls的用户的address为深圳 (模糊匹配)
update users u set u.address='深圳' where u.username like '%ls%'
-- 修改users表中username不为admin和ls的地址为浙江
UPDATE users u SET u.address='四川' WHERE u.username <> 'admin' and u.username <> 'ls'
UPDATE users u SET u.address='浙江' WHERE u.username not IN('admin','ls')
delete
DELETE FROM 表名 [ WHERE condition ];
-- 删除users表中uid等于u1005的用户
DELETE FROM users WHERE uid = 'u1005'
<3>DQL
查询语句
使用的关键字 select
简单的单表查询或多表的复杂查询和嵌套查询
数据库语言中最核心、最重要的语句
使用频率最高的语句
语法:
SELECT [ALL | DISTINCT]
{ * | table.* | [ table.field1 [ as alias1] [, table.field2 [as alias2]][, ...]] }
FROM table_name [ as table_ alias ]
[ left|out|inner join table_name2 ] #联合查询
[ WHERE ... ] #指定结果需满足的条件
[ GROUP BY ...] #指定结果按照哪几个字段来分组
[ HAVING ...] #过滤分组的记录必须满足的次要条件
[ ORDER BY... ] #指定查询记录按一个或者多个条件排序
[ LIMIT { [ offset,] row_count | row_count OFFSET offset }] ;
<1>单表查询
-- 查询所有书籍的分类信息
SELECT * FROM classify;
-- 查询所有书籍的分类信息名称
SELECT cname FROM classify;
-- 给表起别名
SELECT c.`cname` FROM classify c;
-- 给列起别名
SELECT c.`cname` AS 'classifyName' FROM classify c;
-- 查询价格大于40元的所有书籍,显示书名和isbn
SELECT b.`bookname`, b.`isbn` FROM books b WHERE b.`price` > 40;
-- 查询有多少本书存在评论信息
SELECT DISTINCT(c.`booid`) FROM COMMENT c;
注释:
查询表中所有的数据列结果,采用“*”符号;效率比较低,不推荐
通过AS可以给表和列起别名,其中AS可以省略不写
distince关键字的作用是去重
<2>数据库中的表达式
-- 表达式
select 1+1;
-- 由于纸的价格上涨,需要给每本书进行涨价10%,保留两位小数 [运算表达式]
select b.`bookname`,b.`price`, round(b.`price`*(1.1),2) newprice from books b;
-- 涨价完成后,更新到数据库中。(练习)
-- 统计书本的数量 [函数]
select count(b.`bid`) `sum` from books b;
-- sum函数 求和 max 最大值 min 最小值 AVG 求平均值 round 四舍五入
<3>查询条件
where关键字后面紧跟条件,类似于 update中所描述的条件
-- 查询bookname中社会的书籍信息
select b.`bid`,b.`bookname`,b.`isbn` from books b where b.`bookname` like '%社会%'
<4> 多表查询
-- 多表查询
-- 查询所有书所对应的分类信息 书的信息--books 分类信息 --classify
SELECT b.`bid`,b.`bookname`,b.`isbn`,b.`dateofpublication`, c.cname FROM books b, classify c
WHERE b.`cid` = c.cid
-- 查询所有书所对应的分类信息,没有分类信息,也要显示(左外连接或右外连接查询)SELECT b.`bid`,b.`bookname`,b.`isbn`,b.`dateofpublication`, c.cname FROM books b LEFT JOIN classify c ON b.`cid` = c.cid
SELECT b.`bid`,b.`bookname`,b.`isbn`,b.`dateofpublication`, c.cname FROM classify c RIGHT JOIN books b ON b.`cid` = c.cid
-- 内连接 inner join
<5>排序
-- 排序 order by
-- 查询所有书所对应的分类信息,没有分类信息,也要显示,并按照编号进行排序
SELECT b.`bid`,b.`bookname`,b.`isbn`,b.`dateofpublication`, c.cname from books b
left join classify c on b.`cid` = c.cid
order by b.bid ASC, b.isbn desc, b.`bookname` desc
<6> limit限制
-- 显示前3条分类信息
SELECT * FROM classify LIMIT 3;
-- 显示第2条到第5条的分类信息
SELECT * FROM classify LIMIT 1,4;
<7>分组聚合
group by--指定结果按照哪几个字段来分组
having--->过滤分组的记录必须满足的条件
-- 统计每本书的评论数
SELECT c.`booid`, COUNT(*) FROM `comment` c
GROUP BY c.booid
-- 统计每个用户的评论个数
SELECT c.`userid`, COUNT(*) FROM `comment` cGROUP
BY c.`userid`
-- 统计每本书评论的数量大于等于2条
SELECT c.`booid`, COUNT(c.`score`) nums FROM `comment` cGROUP BY c.booidHAVING nums >=2
-- 统计评分大于等于4.5书的评论数















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











