







目录
补充:在group by查询中select语句中出现的字段必须要出现在group by中,聚合函数可除外,不然会报错
1、`ROWS`方式,通常使用BETWEEN ... AND(物理窗口)
MySQL基础回顾
一、MySQL中查询五子句
基本使用:select * from table ① where ② group by ③ having ④ order by ⑤ limit顺序不能颠倒,执行按顺序执行
1.1、where子句
1、模糊查询
① like是模糊查询关键字
② %表示任意多个任意字符
③ _表示一个任意字符
2、范围查询
① between .. and .. 表示在一个连续的范围内查询
② in 表示在一个非连续的范围内查询
3、空判断查询(特殊)
① 判断为空使用: is null
② 判断非空使用: is not null
4、in
IN关键字用于判断某个字段的值是否在指定集合中。如果字段的值恰
好在指定的集合中,则将字段所在的记录将査询出来。
1.2、group by子句
GROUP BY 列名 [HAVING 条件表达式] [WITH ROLLUP]-
group by 根据指定的一个或者多个字段对数据进行分组
-
group_concat(字段名)函数是统计每个分组指定字段的信息集合
-
聚合函数在和 group by 结合使用时, 聚合函数统计和计算的是每个分组的数据
-
having 是对分组数据进行条件过滤
-
with rollup在最后记录后面新增一行,显示select查询时聚合函数的统计和计算结果
补充:在group by查询中select语句中出现的字段必须要出现在group by中,聚合函数可除外,不然会报错
1.3、having子句
跟where子句差不多的功能,但是一般在group by语句后面使用,对分组后的结果进行筛选,其执行的顺在where之后
1.4、order by子句
select * from 表名 order by 列1 asc|desc [,列2 asc|desc,...]① 排序使用 order by 关键字
② asc 表示升序
③ desc 表示降序
1.5、limit子句
limit关键字在MySQL中,主要用于限制查询结果返回的数量。
select * from 表名 limit start,count-
使用 limit 关键字可以限制数据显示数量,通过 limit 关键可以完成分页查询
-
limit 关键字后面的第一个参数是开始行索引(默认是0,不写就是0),第二个参数是查询条数
二、连接查询
2.1、内连接查询
查询两个表中符合条件的共有记录
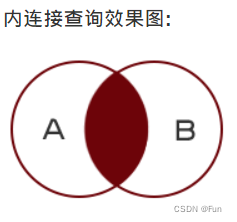
内连接查询语法格式:
select 字段 from 表1 inner join 表2 on 表1.字段1 = 表2.字段22.2、左外连接
以左表为主根据条件查询右表数据,如果根据条件查询右表数据不存在使用null值填充
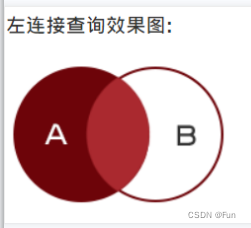
左连接查询语法格式:
select 字段 from 表1 left join 表2 on 表1.字段1 = 表2.字段22.3、右外连接
以右表为主根据条件查询左表数据,如果根据条件查询左表数据不存在使用null值填充
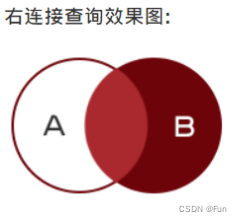
右连接查询语法格式:
select 字段 from 表1 right join 表2 on 表1.字段1 = 表2.字段2三、子查询
1、子查询(嵌套查询)
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句,外部那个select语句则称为主查询.
主查询和子查询的关系:
-
子查询是嵌入到主查询中
-
子查询是辅助主查询的,要么充当条件,要么充当数据源(数据表)
-
子查询是可以独立存在的语句,是一条完整的 select 语句
2、with语句使用 CTE
with (临时表) as
(
sql语句(子查询)
)
select 字段
from 临时表窗口函数
一、基本使用
窗口函数的基本语法
<window_function> OVER (...)
<window_function>: 聚合函数,排序函数,分析函数
OVER(...):窗口函数的窗框通过`OVER(...)` 子句定义, 定义窗框 (开窗方式和大小)
OVER( PARTITION BY )的使用
<window_function> OVER (PARTITION BY column1, column2 ... column_n)
`PARTITION BY` 的作用与 `GROUP BY`类似:将数据按照传入的列进行分组,与 `GROUP BY` 的区别是, `PARTITION BY` 不会改变结果的行数。
执行顺序:
窗口函数与where子句,where子句先执行,窗口函数后执行
窗口函数与order by子句,窗口函数先执行,order by子句后执行
窗口函数只能出现在SELECT和ORDER BY子句中 如果查询的其他部分(WHERE,GROUP BY,HAVING)需要窗口函数,使用子查询,然后在子查询中在使用窗口函数 如果查询使用聚合或GROUP BY,请记住窗口函数只能处理分组后的结果,而不是原始的表数据
二、聚合函数
1、count()
表示求指定列的总行数
2、max()
表示求指定列的最大值
3、min()
表示求指定列的最小值
4、sum()
表示求指定列的和
5、avg()
表示求指定列的平均值
三、排序函数
基本使用:
<ranking function> OVER (ORDER BY <order by columns>)
1、rank ()
数据相同 并列排序 返回序号不连续
2、dense_rank()
数据相同 并列排序 但返回序号连续
3、row_number()
数据相同 顺序排序 返回序号连续(返回行号)
4、区别
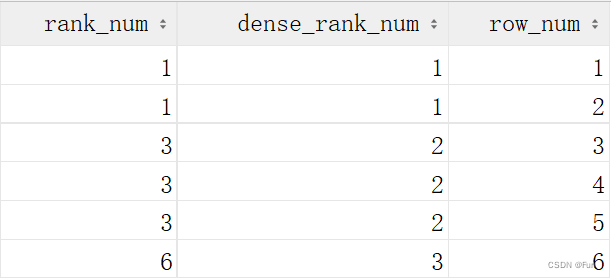
5、ntile(x)
`NTILE(X)`函数将数据分成X组,并给每组分配一个数字(1,2,3....)
四、window frame自定义窗口
window frames基本语法
<window function> OVER (...
ORDER BY <order_column>
[ROWS|RANGE] <window frame extent>
)
1、`ROWS`方式,通常使用BETWEEN ... AND(物理窗口)
上限(upper_bund)和下限(lower_bound)的取值为如下5种情况:
UNBOUNDED PRECEDING – 对上限无限制
N PRECEDING – 当前行之前的第 n 行 ( n ,填入具体数字如:5 PRECEDING )
CURRENT ROW – 仅当前行
N FOLLOWING –当前行之后的第 n 行 ( n ,填入具体数字如:5 FOLLOWING )
UNBOUNDED FOLLOWING – 对下限无限制
2、`RANGE`方法(逻辑窗口)
`ROWS` 和 `RANGE` 的区别是, `RANGE` (范围)考虑的是具体取值;
`ROWS` 和 `RANGE` 的区别与 `ROW_NUMBER` 和 `RANK()`的区别类似
使用方法跟rows一样,但是取值跟order by 后面的字段相关
在使用`RANGE` 时,一般用
`RANGE UNBOUNDED PRECEDING`
`RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING`
`RANGE CURRENT ROW`
一般 不与 n PRECEDING 或 n FOLLOWING 一起使用,窗口大小不容易固定
3、order by 与over()的联系
如果不写rows或者range,默认 UNBOUNDED PRECEDING – 对上限无限制
五、分析函数
基本使用
<analytic function> OVER (...)
1、LEAD(X)函数(超前函数)
LEAD 领先的意思 找行号更大的数据
LEAD函数还可以传入两个参数LEAD(x,y,z):
x 跟传入一个参数时的情况一样(传入字段)
y 代表了偏移量
z将最后往前移的字段替换为指定的
2、LAG(X)函数(落后函数)
跟LEAD函数一样的使用方法,但功能相反(LAG 落后的意思 找行号更小的数据)
3、FIRST_VALUE(x)函数
FISRT_VALUE函数,从名字中能看出,返回指定列的第一个值
4、LAST_VALUE(x)函数
LAST_VALUE(x)返回最后一个值
易错:当OVER子句中包含ORDER BY时,SQL会自动带上默认的window frame语句:
RANGE UNBOUNDED PRECEDING, 意味着我们的查询范围被限定在第一行到当前行
解决方法:window frame语句【RANGE|ROWS】 BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
5、NTH_VALUE(x,n)函数
NTH_VALUE(x,n) 函数返回 x列,按指定顺序的第n个值
跟LAST_VALUE(x)函数一样,后面需要加【RANGE|ROWS】BETWEEN UNBOUNDED PRECEDINGAND UNBOUNDED FOLLOWING
其他函数补充
日期函数
数学函数
字符串函数















 4140
4140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









