







Hive基础知识回顾
1、Hive与Hadoop的关系
Hive是基于Hadoop的一个数据仓库工具(所以Hive的logo跟大象和黄蜂有关),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
Hive使用Hadoop HDFS作为数据存储系统
Hive使用Hadoop MapReduce来分析数据
本质是将SQL转换为MapReduce程序。
主要用途:用来做离线数据分析,比直接用MapReduce开发效率更高。

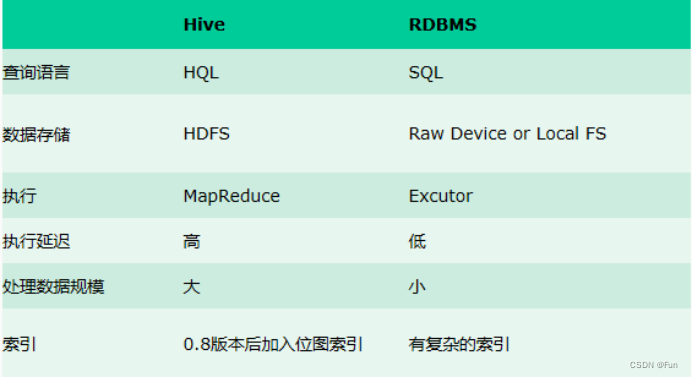
2、Hive与数据库的关系
Hive用于海量数据的离线数据分析。hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析。
-
Hive属于OLAP系统 是面向分析的 侧重于数据分析
-
数据库属于OLTP系统 是面向事务的 侧重于数据时间交互
更直观的对比请看下面这幅图:
3、metadata 、metastore
Metadata即元数据。元数据包含用Hive创建的database、table、表的字段等元信息。元数据存储在关系型数据库中。
Metastore即元数据服务,作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
这样Hive就会有三种部署模式,内嵌模式、本地模式、远程模式。
内嵌模式:使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务
远程模式:需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。
本地模式:用外部数据库来存储元数据
| metadata储存位置 | metastore服务需不需要单独配置、启动 | |
| 内嵌模式 | Derby | 否 |
| 本地模式 | MySQL | 否 |
| 远程模式 | MySQL | 是 |
4、Hive的架构

用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
元数据存储:通常是存储在关系数据库如 mysql/derby中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
5、Hive的启动方式
第一代客户端启动方式 /bin/hive
需要先启动metastore 服务
前台启动命令:apache-hive-3.1.2-bin/bin/hive --service metastore
后台启动命令:nohup apache-hive-3.1.2-bin/bin/hive --service metastore &
然后启动hive
apache-hive-3.1.2-bin/bin/hive第二代客户端启动方式 bin/beeline
需要先启动metastore
nohup apache-hive-3.1.2-bin/bin/hive --service metastore &
启动hiveserver2:
nohup apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
再启动beeline
/apache-hive-3.1.2-bin/bin/beeline
最后链接hive2
! connect jdbc:hive2://node1:10000Hive SQL--DDL
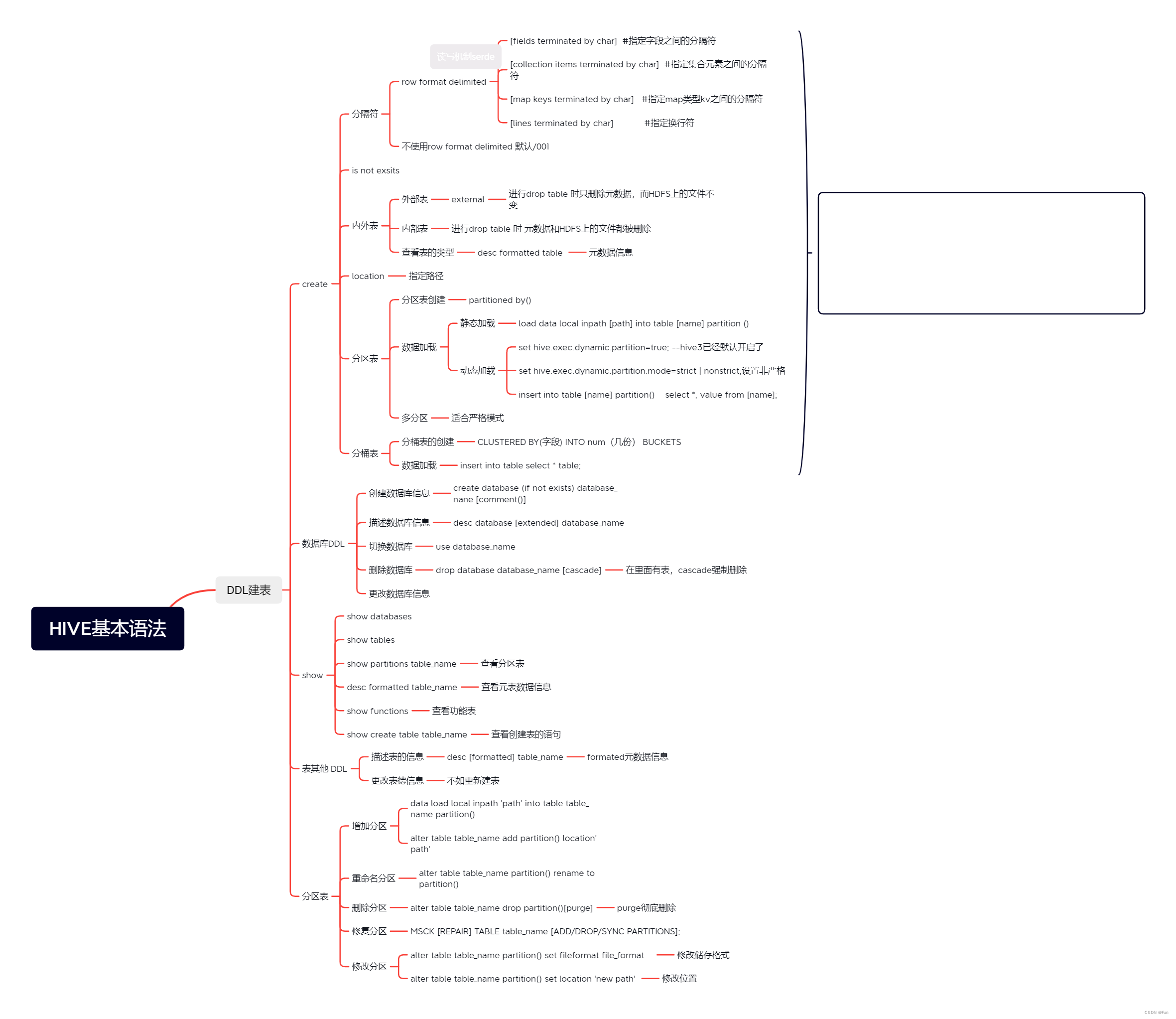
数据定义语言 (Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database(schema)、table、view、index等。核心语法由CREATE、ALTER与DROP三个所组成。DDL并不涉及表内部数据的操作.
1、完整建表语法树
CREATE [TEMPORARY][EXTERNAL] TABLE [IF NOT EXISTS][db_name.]table_name
[(col_name data_type [COMMENT col_comment], ... ]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)】]
[CLUSTERED BY (col_name, col_name,.….)[SORTED BY (col_name [ASC|DESC].….]
INTO num_buckets BUCKETS]
[ROW FORMAT DELIMITED|SERDE serde_name WITH SERDEPROPERTIES (property_name=property_value..]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES(property_name=property_value,...)];- []中括号的语法表示可选。
- |表示使用的时候,左右语法二选一。
- 建表语句中的语法顺序要和上述语法规则保持一致。
- 大写的是建表语法的关键字,用于指定某些功能。
2、建表语法解析
- TEMPORARY
创建一张临时表
- EXTERNAL
外部表(External table)中的数据不是Hive拥有或管理的,只管理表元数据的生命周期。要创建一个外部表,需要使用EXTERNAL语法关键字。
删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。
内部表(Internal table)也称为被Hive拥有和管理的托管表(Managed table)。默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。
当删除内部表时,它会删除数据以及表的元数据。
什么时候需要外部表
当需要通过Hive完全管理控制表的整个生命周期时,请使用内部表。
当文件已经存在或位于远程位置时,请使用外部表,因为即使删除表,文件也会被保留。
- IF NOT EXISTS
建表的时候,如果表名已经存在,默认会报错,通过IF NOT EXISTS关键字可以忽略异常
-
COMMENT
字段或列的注释是用属性COMMENT 来添加。
-
LOCATION
在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便。
ROW FORMAT DELIMITED|SERDE
其中ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。
如果使用delimited,表示使用默认的LazySimpleSerDe类来处理数据。
如果数据文件格式比较特殊可以使用ROW FORMAT SERDE serde_name指定其他的Serde类来处理数据,甚至支持用户自定义SerDe类。
ROW FORMAT DELIMITED具体的子语法
[fields terminated by char] #指定字段之间的分隔符
[collection items terminated by char] #指定集合元素之间的分隔符
[map keys terminated by char] #指定map类型kv之间的分隔符
[lines terminated by char] #指定换行符-
默认分隔符
-
Hive在建表的时候,如果没有row format语法,则该表使用==\001默认分隔符==进行字段分割;
-
如果此时文件中的数据字段之间的分隔符也是\001 ,那么就可以直接映射成功。
-
针对默认分隔符,其是一个不可见分隔符,在代码层面是\001表示
-
在vim编辑器中,连续输入ctrl+v 、ctrl+a;
-
在实际工作中,Hive最喜欢的就是\001分隔符,在清洗数据的时候,==有意识==的把数据之间的分隔符指定为\001;
-
PARTITIONED BY
-
==分区表的字段不能是表中已有的字段==;分区的字段也会显示在查询结果上;
-
分区的字段是虚拟的字段,出现在表所有字段的后面,其值来自于加载数据到表中的时候手动指定。
- 分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度
分区表是一种优化表,建表的时候可以不使用,但是,当==创建分区表之后,使用分区字段查询可以减少全表扫描,提高查询的效率==。
目的为了之后的查询工作
CLUSTERED BY INTO N BUCKETS
-
其中CLUSTERED BY (col_name)表示根据哪个字段进行分;
-
INTO N BUCKETS表示分为几桶(也就是几个部分)。
-
需要注意,分桶的字段必须是表中已经存在的字段。
使用分桶表的好处
- 基于分桶字段查询时,减少全表扫描
- JOIN时可以提高MR程序效率,减少笛卡尔积数量
-
分桶表数据进行抽样
STORED AS
逻辑表中的数据,最终需要落到磁盘上,以文件的形式存储,有两种常见的存储形式。行式存储和列式存储。
- 行式存储 -- 适合数据的插入删除
- 列式存储 -- 适合查询
- 行式存储textfile 文件格式 -- 不写stored by 默认使用此格式
- ORC、Parquet 列式存储格式 -- 底层是以二进制形式存储,数据存储效率极高,方便查询,
3、数据库DDL操作
-
Create database
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
-- COMMENT:数据库的注释说明语句
-- LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse
-- WITH DBPROPERTIES:用于指定一些数据库的属性配置。- desc database
-- 显示Hive中数据库的名称,其注释(如果已设置)及其在文件系统上的位置等信息。
DESCRIBE DATABASE/SCHEMA [EXTENDED] db_name;
-- EXTENDED:用于显示更多信息- use database
选择特定的数据库,切换当前会话使用哪一个数据库进行操作。
- drop database
DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE];
-- 默认行为是RESTRICT,这意味着仅在数据库为空时才删除它。
-- 要删除带有表的数据库,在后面加上CASCADE- alter database
--更改数据库属性
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
--更改数据库所有者
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
--更改数据库位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;4、表的其他DDL操作
- Describe table
-- 显示Hive中表的元数据信息
describe [formatted|extended] [db_name.]table_name;
-- 如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。
-- 如果指定了FORMATTED关键字,则它将以表格格式显示元数据。- Drop table
DROP TABLE删除该表的元数据和数据。如果已配置垃圾桶(且未指定PURGE),则该表对应的数据实际上将移动到.Trash/Current目录,而元数据完全丢失。删除EXTERNAL表时,该表中的数据不会从文件系统中删除,只删除元数据。
如果指定了PURGE,则表数据不会进入.Trash/Current目录,跳过垃圾桶直接被删除。因此如果DROP失败,则无法挽回该表数据。
DROP TABLE [IF EXISTS] table_name [PURGE]; 从表中删除所有行。可以简单理解为清空表的所有数据但是保留表的元数据结构。如果HDFS启用了垃圾桶,数据将被丢进垃圾桶,否则将被删除。
TRUNCATE [TABLE] table_name;- Alter table
--1、更改表名
ALTER TABLE table_name RENAME TO new_table_name;
--2、更改表属性
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ... );
--更改表注释
ALTER TABLE student SET TBLPROPERTIES ('comment' = "new comment for student table");
--3、更改SerDe属性
ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, ... )];
ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;
ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = ',');
--移除SerDe属性
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );
--4、更改表的文件存储格式 该操作仅更改表元数据。现有数据的任何转换都必须在Hive之外进行。
ALTER TABLE table_name SET FILEFORMAT file_format;
--5、更改表的存储位置路径
ALTER TABLE table_name SET LOCATION "new location";
--6、更改列名称/类型/位置/注释
CREATE TABLE test_change (a int, b int, c int);
// First change column a's name to a1.
ALTER TABLE test_change CHANGE a a1 INT;
// Next change column a1's name to a2, its data type to string, and put it after column b.
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
// The new table's structure is: b int, a2 string, c int.
// Then change column c's name to c1, and put it as the first column.
ALTER TABLE test_change CHANGE c c1 INT FIRST;
// The new table's structure is: c1 int, b int, a2 string.
// Add a comment to column a1
ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'this is column a1';
--7、添加/替换列
--使用ADD COLUMNS,可以将新列添加到现有列的末尾但在分区列之前。
--REPLACE COLUMNS 将删除所有现有列,并添加新的列集。
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type,...);
5、分区表DDL操作
- Add partition
- rename partition
- delete partition
- msck partition
- alter partition
6、show操作
--1、显示所有数据库
show databases;
show schemas;
--2、显示当前数据库所有表
show tables;
--3、显示表分区信息,分区按字母顺序列出,不是分区表执行该语句会报错
show partitions table_name;
--4、显示表/分区的扩展信息
SHOW TABLE EXTENDED [IN|FROM database_name] LIKE table_name;
show table extended like student;
--5、显示表的创建语句
SHOW CREATE TABLE [db_name.]table_name;
--6、显示当前支持的所有自定义和内置的函数
show functions;
--7、Describe desc
-- 查看表信息
desc extended table_name;
--查看表信息(格式化美观)
desc formatted table_name;
--查看数据库相关信息
describe database database_name;
思维导图
DML(数据操纵语言)
1、load
load加载操作是将数据文件移动到与 Hive表对应的位置的纯复制/移动操作.
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]
[INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)- 其中当中的local关键字是指从本地文件系统(hiveserver2)加载数据到Hive表中
这个就相当于执行了hadoop fs -put 这个命令,属于复制操作
- 如果没有local关键字是指从HDFS文件系统加载数据到Hive表中
这个相当于执行了hadoop fs -mv 这个命令,属于移动操作,HDFS文件系统的文件将会移动到对应的HIVE表下
- 如果使用了OVERWRITE关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
2、insert into
- 使用insert +value方式
这样执行过程非常非常慢,因为Hive底层是使用MapReduce把数据写入HDFS的。
- 使用insert + select加载数据
在hive中,insert主要是结合 select 查询语句使用,将查询结果插入到表中
保证后面select查询语句返回的结果字段个数、类型、顺序和待插入表一致;
如果不一致,Hive会尝试帮你转换,但是不保证成功;
- Multi Inserts (多重插入)
multiple inserts可以翻译成为多次插入,多重插入,核心是:一次扫描,多次插入。其功能也体现出来了就是减少扫描的次数。
如果需要将一张表中的字段分别加载多张表中,可以使用多重插入,这样可以简化操作
from 加载的表
insert overwrite table 目标表1
select 目标字段1
insert overwrite table 目标表2
select 目标字段2
...;- Dynamic partition inserts (动态分区插入)
分区的值是由后续的select查询语句的结果来动态确定的,根据查询结果自动分区。
但是需要对hive进行配置
-- 需要设置true为启用动态分区插入
set hive.exec.dynamic.partition = true
-- 设置非严格模式
set hive.exec.dtnamic.partition.mode = nonstrict补充:对于静态分区和动态分区区别
1、如果是在加载数据的时候人手动写死指定的 叫做静态分区
2、如果是通过insert+select 动态确定分区值的,叫做动态分区
如果没有设置非严格模式,在使用动态分区时必须有一个分区进行静态加载
3、数据导出操作
--标准语法:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
--Hive extension (multiple inserts):
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
--row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
DQL
语法树
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows];cluster/distribute/sort/order by
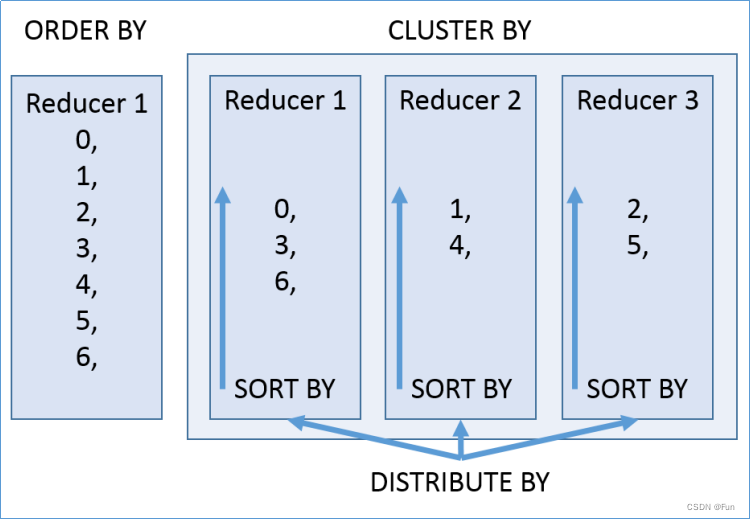
-
order by
ORDER BY语法类似于SQL语言中的ORDER BY语法。会对输出的结果进行全局排序,因此底层使用MapReduce引擎执行的时候,只会有一个reducetask执行。
-
distribute by
DISTRIBUTE BY负责分,
distribute by(字段)根据指定字段将数据分到不同的reducer,分发算法是hash散列
-
sort by
SORT BY负责分组内排序,
sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
-
cluster by
distribute和sort的字段是同一个时,此时,cluster by = distribute by + sort by
Hive性能调优
fetch抓取机制
能不走MR就不走MR
MR本地模式
能在本地就在本地
join优化
map端jion
大表对大表jion
空key 过滤
空key转换
桶表join
group by数据倾斜调优
负载均衡
task并行度(针对MR)
其他调优
执行计划explain
并行执行(没有依赖)
hive严格模式
推测执行机制
浪费资源
其他
Hive数据类型
Hive中的数据类型指的是Hive表中的列字段类型。Hive数据类型整体分为两个类别:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
原生数据类型包括:数值类型、时间类型、字符串类型、杂项数据类型;
复杂数据类型包括:array数组、map映射、struct结构、union联合体。
关于Hive的数据类型,需要注意:
- 英文字母大小写不敏感;
- 除SQL数据类型外,还支持Java数据类型,比如:string;
- int和string是使用最多的,大多数函数都支持;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用。
- 如果定义的数据类型和文件不一致,hive会尝试隐式转换,但是不保证成功。
- 可以参考LanguageManual Types - Apache Hive - Apache Software Foundation
Hive读写文件流程
SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。序列化是对象转化为字节码的过程;而反序列化是字节码转换为对象的过程。Hive使用SerDe(和FileFormat)读取和写入行对象。
Hive读取文件机制:首先调用InputFormat(默认TextInputFormat),返回一条一条kv键值对记录(默认是一行对应一条记录)。然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
Hive写文件机制:将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列,然后调用OutputFormat将数据写入HDFS文件中。
Hive的数据压缩
-
Hive的默认执行引擎是MapReduce,因此通常所说的Hive压缩指的是MapReduce的压缩。
-
压缩是指通过==算法对数据进行重新编排==,降低存储空间。无损压缩。
-
MapReduce可以在两个阶段进行数据压缩
-
map的输出
-
减少shuffle的数据量 提高shuffle时网络IO的效率
-
-
reduce的输出
-
减少输出文件的大小 降低磁盘的存储空间
-
-
-
压缩的弊端
-
浪费时间
-
消耗CPU、内存
-
--设置Hive的中间压缩 也就是map的输出压缩
1)开启 hive 中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
2)开启 mapreduce 中 map 输出压缩功能
set mapreduce.map.output.compress=true;
3)设置 mapreduce 中 map 输出数据的压缩方式
set mapreduce.map.output.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
--设置Hive的最终输出压缩,也就是Reduce输出压缩
1)开启 hive 最终输出数据压缩功能
set hive.exec.compress.output=true;
2)开启 mapreduce 最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
3)设置 mapreduce 最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4)设置 mapreduce 最终数据输出压缩为块压缩 还可以指定RECORD
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
-- 推荐使用snappy
Snappy
org.apache.hadoop.io.compress.SnappyCodec
在Hive中推荐使用ORC+snappy压缩。















 2202
2202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









